11번가 주니어 개발자의 첫 MSA 설계 및 개발기
안녕하세요. 11번가 주문개발팀 개발자 고다경입니다. 입사 후 파일럿 프로젝트를 진행한 것을 Product로 전환하는 과정을 담았습니다. 많이 부족한 글이지만 신입~주니어의 글이라 생각해주시고 읽어주시기 바랍니다 🙏
목차
- 그래서 무엇을 했나요 ?
- Q. 데이터 전송,, 혹시,, 너,, 뭐,, 돼,,?
- 뭐부터 해야할지..
- 설계 과정
- Flow 설계
- 코드 중복을 어떻게 줄여요 ?
- 전송되는 데이터는 어떻게 보장할까.
- Logging & Monitoring
- 개발하며 겪은 시행 착오
- 과정을 진행하며 느낀점
- 마치며..
그래서 무엇을 했나요 ?
2020년 1월에 입사한 뒤 주어진 과제는 CDC(Change Data Capture) 개발이었습니다.
What is Change Data Capture ?
Database의 데이터에 대한 변경 사항을 식별 및 캡처한 다음 이러한 변경 사항을 실시간으로 Down Stream 또는 System에 전달하는 Process 를 나타냅니다.
- Source Database의 Transaction에서 모든 변경 대상을 캡쳐해서 실시간으로 데이터를 동기화 합니다
- 안정적인 데이터 복제 및 Down Time 없는 마이그레이션을 제공합니다.
- 최신 클라우드 아키텍처에 적합하며, 실시간 데이터를 이동하기 때문에 실시간 분석 및 Data Science 도 지원합니다
목표는 Oracle에서 제공하는 CDC 솔루션인 OGG(Oracle Golden Gate)를 사용하지 않고 쿠폰 DB의 변경 사항이 생길 경우 메인 DB에 변경 사항을 반영해주는 것이었습니다.
OGG를 사용하지 않으려 한 이유는, 현재 거대한 데이터베이스 중심인 메인 DB에 더 이상의 부하를 주지 않으려고 한 것이 컸습니다.
또한 과제 당시 MSA 설계와 Kafka 기술 스택의 경험 및 활용하길 원해서 해당 스택으로 개발을 진행하고, 클라우드 아키텍처에 적합하기에 AWS 기반으로 개발하였습니다.

Q. 데이터 전송,, 혹시,, 너,, 뭐,, 돼,,?

쉬울거라 생각하진 않았지만, 막상 시작하니 정말 설계부터 쉽지 않았습니다. 초기에 필요한 기능은 다음과 같았습니다.
- CDC 기능을 개발해 OGG를 대체할 것.
- 변경 데이터를
실시간 반영해야한다. 순서 보장이 필요함.
- 변경 데이터를
- 데이터 동기화에 대한
로깅및모니터링개발.
이후 요구사항의 구체화, 오버엔지니어링의 지양 등으로 필요한 기능이 변경되게 됩니다.
뭐부터 해야할지..

데이터를 전송하는 방법에는 Infra Level에서의 전송과 Application Level에서의 전송이 있다고 판단 했습니다. 이 중 좀 더 유연하고 확장성 있는 구조를 위해 Application Level에서 CDC를 구현하기로 결정했습니다.
이후 요구사항을 바탕으로 적용해야할 사내 시스템에 대해 파악해보았습니다.
현재 11번가에는 Vine 이라는 이름의 API Server가 있습니다. 그 중 쿠폰 도메인에 대한 API Server가 존재합니다. 11번가에서는 내부적으로 끊임없이 레거시를 개선하고 있습니다. 그의 일환으로 레거시 프로젝트의 로직을 API Server로 이관하는 작업도 진행 중입니다.
해당 작업이 완료되었다는 가정하에, 모든 로직이 API Server에 모여있음을 가정한다면, 해당 API Server에 전송 로직을 구현하는 것이 좋을 것이란 판단이 들었습니다.
설계 과정
Why Kafka ?!
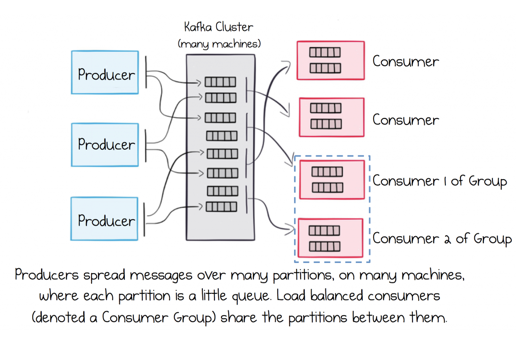
설계의 가장 큰 목적은 Oracle에 의존적이며 부하가 많이 발생하는 OGG를 대체하는 것입니다. OGG와 같이 대용량 데이터를 거의 실시간(Near Real-time) 으로 반영하기 위해서는 Batch System 이 아닌 Reactive System 이 필요합니다. 따라서 시스템 간 느슨한 연결이 필요하며, 이에 Message Queue를 사용하기로 했습니다. Message Queue 중 사내 인프라가 이미 갖춰져 있으며, 대용량 처리에 적합한 Apache Kafka를 선택했습니다.
Kafka의 특징은 다음과 같습니다.
데이터의 종류별로Topic을 생성할 수 있습니다.- 하나의 Topic에
여러 개의 Partition을 설정해 대량의 데이터를분산 처리할 수 있습니다. - 하나의 데이터를
여러 App이 Consume할 수 있습니다.- 일반적인 Queue와 다르게 데이터를 File System에 저장하며
- 그래서
각 Consumer마다 다른 Offset으로 데이터를 처리할 수 있습니다. - 이를 이용해 한가지의 데이터를 동시에
여러 방법으로 이용할 수 있습니다.
- Topic 간에
Stream을 제공합니다.- 필요하다면
데이터를 실시간 변환해 Topic 간 주고 받을 수 있습니다. - 하나의 데이터에 대해 App 마다 필요한 형식이 다르다면 Kafka Streams를 이용해 데이터를 실시간으로 변경해 전송할 수 있습니다.
- 필요하다면
Flow 설계
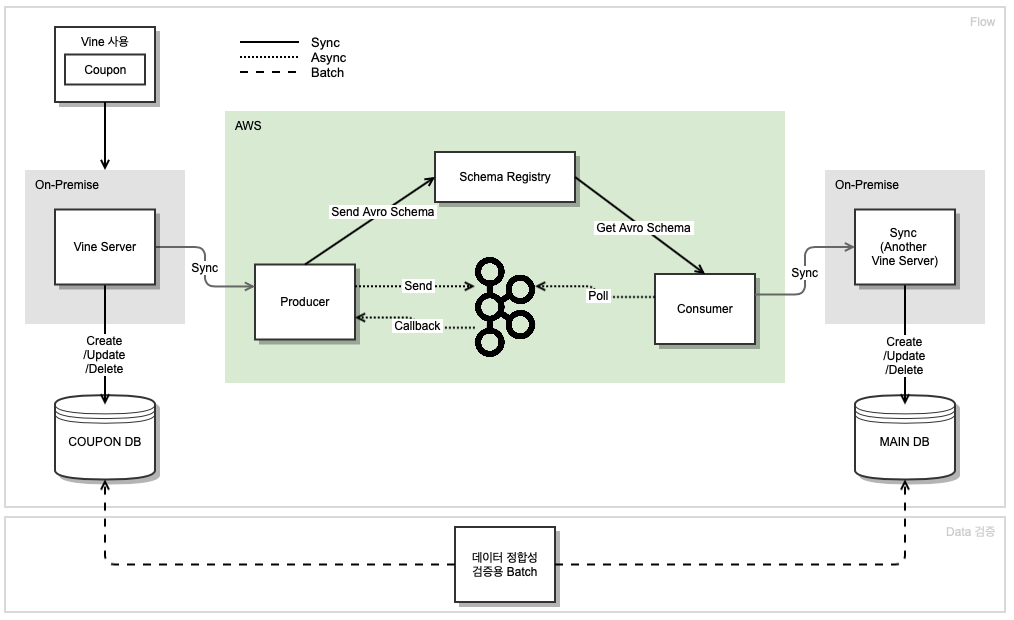
전체적인 데이터의 흐름은 다음과 같습니다.
쿠폰 DB에 대한 로직이 있는 Vine Server에서 출발한 변경된 데이터가 Producer Server → Kafka → Consumer 를 거쳐 메인 DB에 Access 하는 Server에 도착해 변경사항을 저장합니다.
좀 더 구체적으로 말씀드리자면,
Vine API를 사용하고 있는 곳에서 Vine API를 호출해 로직이 수행될 때 쿠폰 DB에 데이터가 저장되고, 동시에 Producer에게 Message를 Producing 합니다. 그리고 Kafka를 거쳐서 Consumer는 메인 DB와 연결된 Server에 Consume한 데이터를 보내고, 다 전달된 변경된 데이터는 그대로 메인 DB에 저장됩니다.
기술 스택
기술 스택은 다음과 같습니다
- Java 11 → Java 8
- 기존 Vine과의 Java Version을 맞추기 위해 변경
- Oracle Database
- Oracle → Oracle 이전
- Oracle → 다른 DB 이전도 가능하지만 기존 DB가 모두 Oracle임
- MyBatis
- Gradle v6.8.3
- On-Premise
- AWS EC2
- Kafka
- spring-kafka version v2.6.0
- AWS MSK
- 당시 MSK가 spring-kafka 2.6.1 와 호환
- Spring Boot Version에 따라 2.6.0 or 2.6.2로 설정이 가능함
- SpringBoot 2.6.x → 2.3.12.RELEASE
- SpringBoot에 내장된 spring-kafka Version 수정을 위해 변경
- Schema Registry
- Avro
- AWS Glue
- Nexus
- Avro Schema Data 의 upload → import 위해 사용
- OOP, Clean Code, Test..
Sync ? Blocking ? Async ? Non-Blocking?
판단을 위해 참고한 것들은 다음과 같습니다. 🤔
Spring MVC의 경우 DeferredResult 등 의 사용으로Async를 지원합니다 링크- Spring MVC의 경우 Blocking이 기본이며, Servlet 3.1 이후부터 Non-block과 Async를 지원하더라도 WebFlux에 비해 성능이 떨어집니다.
Spring WebFlux는 기본적으로Netty를 사용합니다.Tomcat도 사용할 수 있으나 동작되는 방식이 같지 않습니다. 링크- WebFlux를 사용하며 Tomcat을 사용하는 경우, Servlet 3.1 이후의 Non-Blocking 방식을 사용하지만, MVC 자체에
Blocking의 가능성이 있어큰 Thread Pool을 생성합니다. - WebFlux의 기본 서버인 Netty는 Blocking의 가능성이 없어
작은 크기의 고정 Thread Pool(Event Loop)을 생성합니다. - 따라서 Tomcat을 사용한다면, Non-block이며 Async를 지원은 하지만 완전한 Non-block, Async에 비해 성능이 떨어집니다.
- 또한 아키텍처에 Reactive한 Non-block 방식이 꼭 필요한지 고려해 봐야합니다.
- 흐름 중 한 곳이라도 Block이 존재한다면 Non-block 방식은 무의미합니다.
- WebFlux를 사용하며 Tomcat을 사용하는 경우, Servlet 3.1 이후의 Non-Blocking 방식을 사용하지만, MVC 자체에
- 참고한 링크들 📚
First Flow ) Vine → Producer 호출
Vine에서 Producer를 호출할 때는 동기(Sync)로 호출합니다.
기본적으로 Vine 서버들은 Servlet 기반의 서버들입니다. WebFlux가 아닌 Servlet 기반의 Spring도 비동기(Async) 를 지원하여, 호출 방식에 대해 고민했습니다. 하지만 Producer의 작업이 오래 걸리지 않는 단순히 데이터를 받아 전달하는 것이고, 내부에서 Kafka를 이용해 데이터를 전송하기에 앞단에서 부터 비동기 처리를 할 필요가 없다는 판단이 들었습니다.
따라서 비동기가 꼭 필요한 상황이 아니며, 당시 사내에서 사용하는 Vine Platform이 당시 Feign Client만 지원해 동기 전송이 기본인 점을 고려해, Async를 사용하는 모험을 하기보다 Sync 방식의 전송을 선택했습니다.
Second Flow ) Consumer → Another Vine
Another Vine 은 메인 DB에 Access 하는 Server 입니다. 자세한 사항에 대해서는 추후 설명하겠습니다.
Kafka → Consumer는 기본적으로 비동기(Async)로 동작합니다.
현재 구조에서 Consumer는 On-Premise가 아닌 Cloud 기반이기에 트래픽 부스팅이 예상되는 경우 서버를 쉽게 증설할 수 있습니다. 또한 중간의 MSK가 대용량 트래픽을 적절히 조절해 주기에 이 부분에 대한 이슈는 크게 없을 것으로 보입니다. 다만 트래픽이 몰려 Consumer의 처리 시간이 지연된다면 Topic 내부의 Partition Lag이 증가하게 됩니다. Consumer Lag을 모니터링해 수동으로 데이터의 정합성을 맞추어 주어야 합니다.
Producer와 Consumer의 분리
Producer와 Consumer를 굳이 분리한 이유는,
비지니스 로직과 전송부가 강결합되어 있는 것보다는 분리되어 있는 것이 추후 확장성에 도움이 될 것이란 판단이 들었기 때문입니다. 해당 프로그램은 현재는 단순 CDC 프로그램으로 구상하였지만, 추후 Kafka의 데이터를 다양한 방식으로 이용할 수 있기에 Producer, Consumer는 분리하는 것이 맞다는 판단이 들었습니다.
Source Server와 Target Server
그리고 메인 DB를 Access 하는 App은 전송 부분의 Vine 서버와 동일한 App을 사용했습니다.

현재 개발의 목적은 쿠폰 DB에 저장되는 데이터를 그대로~ 빠르게~ 옮겨서 메인 DB에 저장하는 것입니다.
쿠폰 DB와 매칭되는 Source Server에 있는 도메인 Code들을 메인 DB에 Access 하는 Target Server의 App에 그대로 복사해서 서버를 구현한다면, 중복 코드로 인해 개발자의 관리포인트가 더 늘어나게 됩니다. 따라서 쿠폰 DB에 연결된 App에서 메인 DB를 연결하는 코드를 작성한 뒤, 같은 Code를 각기 다른 서버에 다른 이름으로 띄워 사용해, Source Server와 Target Server에서 도메인 Code를 동일하게 사용하기로 결정했습니다.
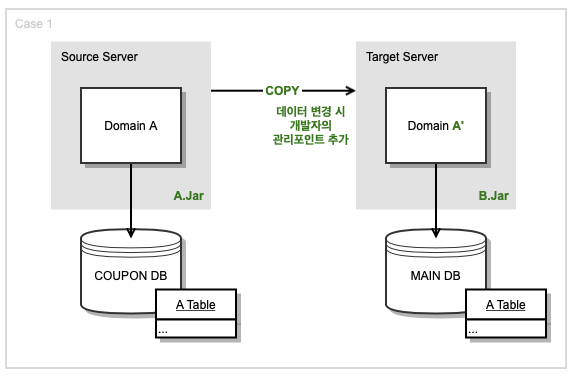
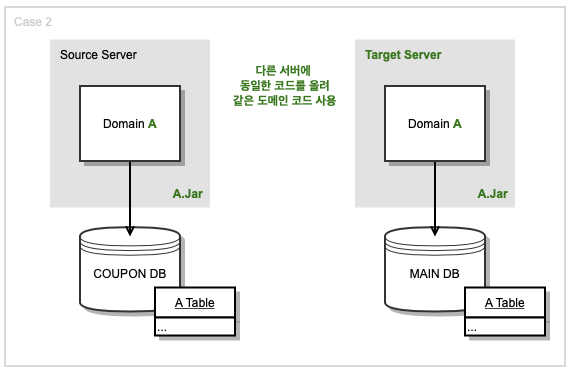
쿠폰, 메인 DB Connection이 Source Server와 Target Server에 둘 다 유지된다는 단점이 있지만, 이 방식의 장점은, 두 서버에서 도메인 Code를 같이 사용해 중복 코드와 관리 포인트를 줄일 수 있다는 점입니다. 그리고 쿠폰 DB와 메인 DB에 대한 Persistence Level의 Test Code를 짤 수 있습니다. 쿠폰 DB에 INSERT 한 뒤 SELECT 한 Origin 값과, 전송된 Avro 데이터로 메인 DB에 INSERT 한 뒤 SELECT 한 값이 동일한지 Test Code로 확인할 수 있습니다.
코드 중복을 어떻게 줄여요 ?
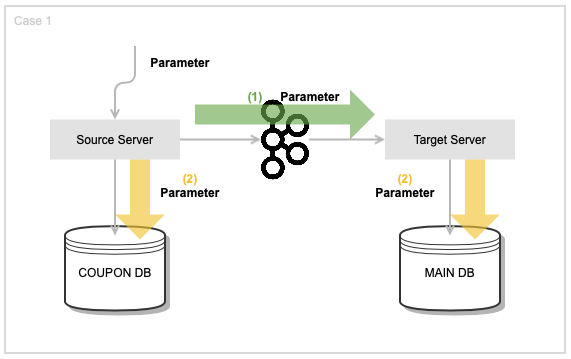
초기 설계는 다음과 같았습니다.
이벤트의 Parameter 데이터를 전송하고 Source와 Target Server에서 동일한 데이터로 동일한 쿼리를 수행했습니다.
Target Server에서는 메인 DB 설정을 따로 해야해서 같은 프로젝트지만 Source Server의 기존 Mapper를 복사해 와 기존 쿼리를 그대로 이용하는 방식으로 개발했습니다. Source 서버에서 이벤트가 발생할 때( = 쿼리문이 실행될 때), 해당 데이터를 Target 서버에 보내고, Target 서버에서는 Source Server에서 복사해 온 동일한 쿼리를 수행 하도록 했습니다. 따라서 기존 쿼리에 변경 사항이 있다면 복사한 쿼리에도 반영해 주어야 합니다. 이 부분도 코드의 중복으로 쿼리 변경시 관리할 포인트가 추가되었습니다. 그리고 단순한 쿼리보다 복잡한 쿼리가 많았고, Code Level에서의 로직보다 쿼리 내에서 로직이 많아서 변경할 데이터를 받아서 복잡한 쿼리를 똑같이 실행하는게 비효율적이란 판단에 방식을 수정했습니다.
또한, Source와 Target에는 Domain 코드가 존재하지만, Producer와 Consumer에서 Domain 코드가 없어서 추가로 코드 중복이 발생하게 됩니다.
이때 Avro Schema의 도입을 생각하게 됩니다.
Schema Registry 란게 있다면서요?

What is Schema Registry ?
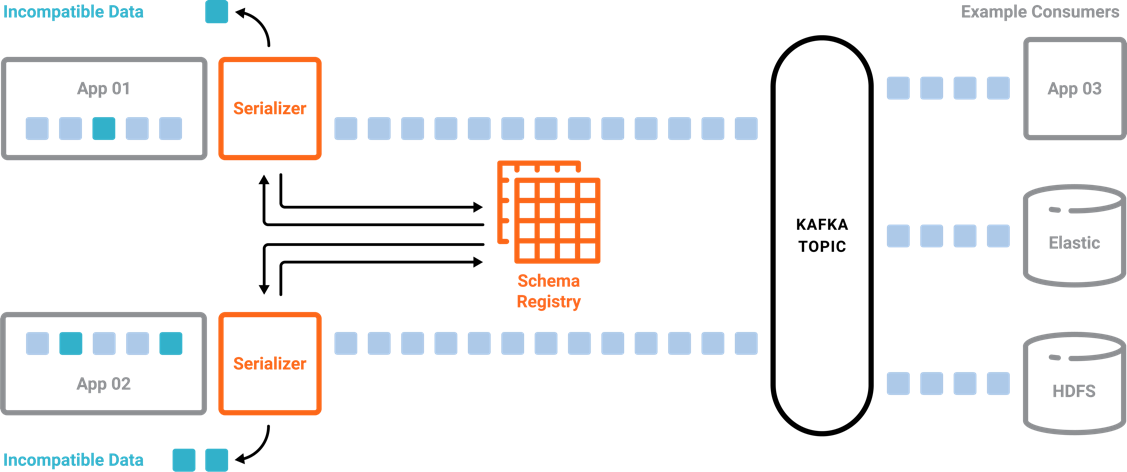
- Kafka 사용시 Producer는 어떤 Consumer가 메세지를 가져가는지, Consumer는 어떤 Producer가 메세지를 보냈는지 모릅니다.
- 따라서 메세지의 송/수신자의
결합도를 낮춥니다.
- 따라서 메세지의 송/수신자의
- 하지만 메세지를
Serialize/Deserialize하는 구조로 되어 있어 내부적으로 데이터에 대한 결합도가 남아 있게 됩니다.- ex) Producer가 v1 메세지를 보내다가 v2 메세지를 보내면 Consumer가 수신하지 못합니다.
- Schema Registry는 Kafka 외부에 구성 되어 클라이언트와 통신합니다.
- Topic 별 메세지 Key, Value의
Schema Version을 관리하고,Schema 호환성 규칙을 강제하며,Schema 조회가 가능합니다. - 즉, 외부에서 메세지 변경사항에 대해 Versioning을 관리하여 Kafka App 간의 Data Schema 의존성을 낮출 수 있습니다.
- 스키마 호환성은 Backward, Forward, Full, None으로 구성됩니다.
- Backward :
- 현재 및 이전 버전의 스키마에도 호환됨
- 필드 삭제 또는 기본 값이 있는 필드 추가 인 경우
- Forward :
- 현재 및 이후 버전의 스키마에도 호환됨
- 필드 추가 또는 기본 값이 있는 필드 삭제
- Full :
- 앞 뒤 버전의 스키마에 호환됨
- 기본 값이 있는 필드 추가 또는 삭제
- None : 스키마 호환성 체크하지 않음
- Backward :
- 스키마 호환성을 체크한다면 필드에
기본값은 필수로 지정해야합니다. - 일반적으로 Avro 방식을 사용합니다.
- Avro 명세를 지켜서 Data를 생성해야합니다.
- Schema Registry는 스키마 생성, 조회, 관리에 대한 HTTP API를 제공합니다, 클라이언트들은 이 API를 활용해 스키마를 관리할 수 있습니다.
Avro Schema를 적용한 뒤 변경한 설계는 다음과 같았습니다.
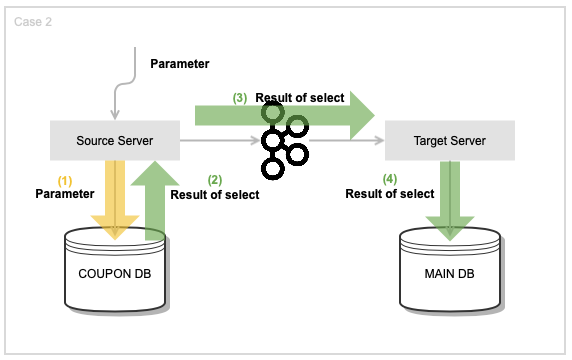
Source 서버에서 쿼리문을 수행한 뒤, 그 결과물의 데이터를 전송했습니다.
그리고 이벤트 단위가 아닌 테이블 단위로 Avro 객체를 생성하고, Target Server가 Source Server와 동일한 쿼리를 실행하는 것이 아닌 Create, Update, Delete 로직만 수행하도록 했습니다.
즉 Source에서 어떤 쿼리를 실행하든 Target Server는 CUD만 수행합니다. 이로써 쿼리 코드 중복을 줄였습니다.
그리고 Avro Schema를 적용하여 Producer와 Consumer에서도 중복적인 Domain 코드를 작성하지 않고 Domain 코드를 사용할 수 있게 되었습니다.
Persistence Level의 Test Code
@Test // Persistence Test를 위해 @SpringBootTest 사용
public void updateCouponStateTest() {
// given
final CouponParameter couponParameter = this.createCouponParameterWithRequiredValuesSet();
// couponDao는 Source Server, mainDao는 target Server에서 사용
// COUPON insert 후 select 한 값으로
Coupon coupon = couponDao.insertCouponState(couponParameter);
// MAIN 저장 위해 Avro Object 변환 후 MAIN insert
final CouponAvro couponAvro = SchemaUtil.pojoToAvroObject(coupon, CouponAvro.newBuilder().build());
mainDao.insertCoupon(couponAvro);
// 데이터 변경 후 update
final String editedData = "EDIT";
coupon.edit(editedData);
Coupon editedCoupon = couponDao.updateCouponState(coupon);
final CouponAvro editedCouponAvro = SchemaUtil.pojoToAvroObject(editedCoupon, CouponAvro.newBuilder().build());
// when
mainDao.updateCoupon(editedCouponAvro);
// Source 는 Specific Query 를 실행했지만 Target 은 Common Update Query 사용
// then
final Coupon expected = couponDao.getCoupon(editedCoupon.getCouponNo());
final Coupon actual = mainDao.getCoupon(editedCoupon.getCouponNo());
// 같은 PK로 조회
assertThat(expected).equals(actual);
}
쿠폰 DB의 DAO에 INSERT 및 UPDATE 한 뒤 SELECT한 결과를 데이터가 같은 Avro 객체로 변환해 INSERT 및 UPDATE를 시행하고 결과값을 비교합니다
Schema Registry 적용 후 message를 전송하면 Domain 코드가 Avro 객체로 변환되어 Request/Response가 가능합니다. 테스트를 위해 수동으로 Avro 객체를 생성하기 위해 아래의 방식을 이용했습니다.
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.reflect.ReflectData;
public class SchemaUtil {
/**
* Domain Object를 Avro Object로 변환
*
* Domain Object를 Avro Object의 필드에 해당하는 값만 변환함.
* Domain Object가 Table Column과 온전히 일치하지 않지만
* Avro Object는 Table Column과 일치하기 때문에
* Avro Object 기준으로 필드를 세팅함.
*
* @param originDomainObject 변환할 Domain Object
* @param targetAvroObject 변환될 Avro Object
* @param <T> Domain과 mapping 되는 Avro Object({TABLE_NAME}Avro)
* @return Avro Object
*/
public static <T> T pojoToAvroObject(Object originDomainObject, T targetAvroObject) {
final GenericData.Record record = mapObjectToRecord(originDomainObject);
return mapRecordToObject(record, targetAvroObject);
}
static GenericData.Record mapObjectToRecord(Object targetObject) {
Assert.notNull(targetObject, "targetObject must not be null");
final Schema schema = ReflectData.get().getSchema(targetObject.getClass());
final GenericData.Record record = new GenericData.Record(schema);
schema.getFields()
.forEach(r -> record
.put(r.name(), PropertyAccessorFactory
.forDirectFieldAccess(targetObject)
.getPropertyValue(r.name()))
);
return record;
}
static <T> T mapRecordToObject(GenericData.Record record, T targetObject) {
Assert.notNull(record, "record must not be null");
Assert.notNull(targetObject, "targetObject must not be null");
final Set<String> fieldSet = extractFieldsOfTargetObject(targetObject);
record.getSchema()
.getFields()
.forEach(d ->{
if(!fieldSet.contains(d.name())) { // 각 fields의 교집합만 추출
return;
}
PropertyAccessorFactory.forDirectFieldAccess(targetObject)
.setPropertyValue(d.name(),
record.get(d.name()) == null ?
record.get(d.name()) :
record.get(d.name()).toString()
);
});
return targetObject;
}
private static <T> Set<String> extractFieldsOfTargetObject(T targetObject) {
final Field[] fields = targetObject.getClass().getDeclaredFields();
return Arrays.stream(fields)
.map(Field::getName)
.collect(Collectors.toSet());
}
}
테스트를 위해 Domain Code를 바탕으로 동일한 데이터를 가진 Avro 객체를 만들기 위해 작성한 코드 입니다.
기존 Domain Code들의 경우 DB Table의 Column과 완전히 일치하지 않았고, Avro 객체는 Default로 추가되는 Schema 정보를 가진 Private Field들이 있습니다. 그래서 Avro Schema를 DB Table과 일치하게 만들고 해당 스키마로 Avro 객체를 생성하도록 했습니다. 데이터는 테이블 기준으로 생성한 Schema의 Field들에 기존 Domain의 Field 값을 적용한 뒤, Avro Schema 객체의 고유 Field가 합쳐서 전송됩니다.
예를 들면 Table A에 a,b,c의 Column이 존재할 때 Domain A 코드에는 a, b의 Field만 존재합니다. 이때 Table A의 Column 기준으로 (a,b,c) Avro Schema를 작성 후 Avro 객체로 변환한다면 a,b,c,SCHEMA$ 등의 필드로 생성됩니다.
따라서 테스트를 위해 Avro 객체를 생성한 뒤 Domain Code와 Avro의 field가 일치하면 Avro 객체에 값을 추가합니다. 즉, 두 객체의 교집합에 해당하는 field에 값을 추가해 반환합니다.
전송되는 데이터는 어떻게 보장할까.

이때쯤 이런 의문이 듭니다.
아무런 문제 없이 데이터가 모두 정확히 전송이 될 수 있을까 ?
중복 전송
API 멱등성과 데이터의 순서 보장

멱등성이란 ? 연산을 여러번 적용해도 한 번 수행한 것과 동일한 결과가 나오는 것을 의미합니다.
- Client의 데이터를 받고 수신을 보낼 때 네트워크 장애 등으로 응답을 보내지 못한 경우, Client 측에서 데이터의 재전송이 이루어질 수 있습니다. 이 경우 Source와 Target의 데이터 정합성이 맞지 않을 수 있습니다.
- DB의 Create가 실행된다면 한번 실행되어 생성된 데이터는 그 다음에 중복으로 Create가 실행되어도 Database의 PK Error 때문에 다시 생성되지 않습니다. Delete도 마찬가지로 여러 번의 Delete가 수행되어도 한 번의 삭제만 이루어집니다. 하지만 여러 개를 수정하는 Update의 경우 여러 번을 실행할 때, 조건과 상태값에 따라 결과가 달라질 수 있습니다. 즉 항상 같은 결과를 갖지 못합니다.
- 1개의 로직에 대해 Create, Update, Delete의 순서가 섞여 전송된다면 그 로직은 멱등하지 않습니다.
Exactly once (enable.idempotence = true)
Kafka에는 정확히 한번 전송을 보장하는 옵션이 있습니다. 링크
- 해당 옵션 사용시
Producer→Broker→Topic간의 멱등성이 보장됩니다. 대신 특정 설정이 종속적입니다. - 또 해당 옵션은 Session 단위에서 유효한 기능으로 Producer App이 재시작하는 경우 멱등성이 보장되지 않습니다.
결과적으로 현재 구조에서 종단 간의 멱등성을 보장하지 못하고, 옵션의 제약이 생기며, 실제 적용해보았을 때 Producer의 성능이 크게 떨어져서 해당 옵션은 사용하지 않고 다른 방식으로 풀었습니다.
PK Error
따로 멱등성 보장을 위한 장치를 하지 않고, 변경된 데이터를 전송할 때 PK 정보를 포함해 전송하여 중복된 데이터 발생 시 DB PK Error로 종단 간 멱등성을 보장할 수 있습니다.
이 방식은 구현이 간단하며 서버 구축 및 운영 리소스를 적게 사용한다는 장점이 있습니다.
다만, 완전한 종단간 멱등성 보장을 위해서는 데이터의 순서가 보장되어야 합니다.
Topic 설계
- 데이터의 순서 보장
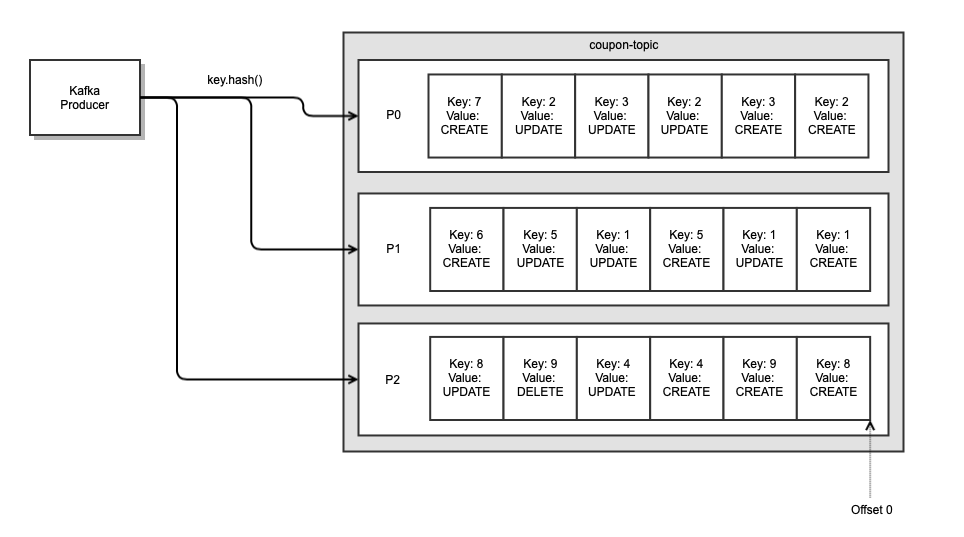
데이터는 일반적으로 Sequential 하게 흘러가기에 순서를 유지해야 합니다. 순서가 뒤바뀌면 데이터 정합성이 맞지 않을 우려가 있습니다.
이를 보장하기 위해, Origin Data의 PK를 Kafka Message Key로 사용해 Kafka의 Topic에 Partitioning 합니다. Kafka는 Partition 내에서 순서가 유지되므로 각 Partition 별로 순서가 유지됩니다. PK를 Key로 이용하는 경우 Key 값이 단순해서 Hash가 중복되더라도 같은 종류의 message가 같은 Partition으로 Partitioning 되므로 같은 데이터에 대해서 데이터 로직의 순서를 유지할 수 있습니다.
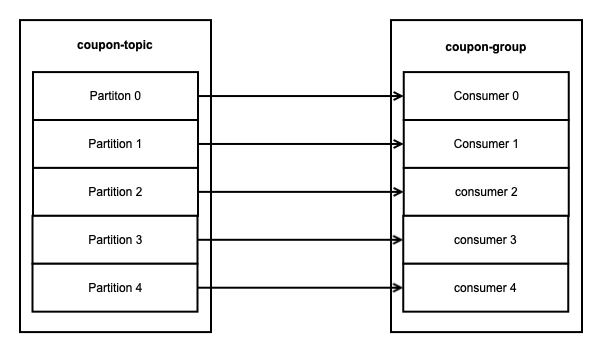
또한 1개의 Partition에 대해서 1개의 Consumer(같은 Consumer group 내에서)가 처리합니다. 따라서 이 경우 동시성 처리는 Kafka의 Partitoin 개수에 따라 결정됩니다.
이 방식의 단점은, Concurrency 성능이 partition에 의존적이며, Partition이 증가할수록 Kafka Broker, 서비스의 Heap Memory 등에 영향을 줍니다. 그리고 Partition에 대응되어 Consumer의 수가 늘어난다면, Consumer 수가 늘어날수록 Consumer Rebalancing 시간도 증가합니다.
- Consumer의 Multi Threading 와 Concurrency 성능
Kafka가 대용량 데이터 처리에 특화되어 있지만, 멀티 스레딩 처리를 하지 않으면 Concurrency 성능이 Partition의 갯수로 제한됩니다.
Partition 개수로만 Concurrency 성능이 조절된다면 Partition 개수의 변화가 있어야 하는데, 성능 조절을 위해 Partition 변경시 Key 와 Partition의 Mapping이 변경되는 Partition Rebalancing이 발생합니다. 또한 Partition은 비싼자원에 속해 갯수 증가를 신중히 고민해야 합니다. 링크
또, Partition에 대응되는 Consumer 수가 증가할 수록 Consumer Rebalance 시간이 증가합니다.
따라서 Concurrency 성능을 위해서는 Partition은 고정해두고 Thread의 갯수로 Concrrency 성능을 조정하는 것이 좋습니다. 링크
이 방식의 단점은 데이터의 순서가 보장되지 않는다는 점입니다.
- 데이터의 순서 보장 vs Concurrency 성능

No Silver Bullet. 세상에 완벽한 해결책은 없습니다. 데이터의 순서 보장을 하며 Concurrency 성능을 어느정도 포기하고 파티션 및 장비 증설로 성능을 커버하거나, 데이터의 순서 보장을 포기하고 전송 성능을 극대화하는 두 가지 선택지가 남았습니다.
팀원들과 논의 끝에 해당 데이터는 약간의 딜레이가 있게 Sync 되어도 문제는 없을 것 같지만, 데이터에 정합성은 중요하다는 결론이 나와서 전자의 방식을 선택했습니다.
- 그밖에 Topic 설계에 고려한 것들
보통 하나의 Database에서는 여러 Table들이 존재합니다. Table 단위로 데이터를 전송한다면, Table 갯수만큼 Topic을 생성해야할까요 ?
Confluent에 관련 글이 있습니다. 링크 . 간단히 요약하면 다음과 같습니다.
- Topic 설계시 가장 중요한 것은, 순서를 유지해야하는 것은 동일 topic에 두며 동일한 파티션 키를 사용하는 것
- 한 entity가 다른 entity에 종속되어 있는 경우나 함께 자주 필요한 경우 동일한 topic에 배치하는 것이 좋음.
- 특정 entity가 다른 entity보다 훨씬 높은 이벤트 비율을 갖는 경우 쓰기 처리량이 낮은 entity만 원하는 consumer를 위해 topic을 분리하는 것이 좋음 (처리량이 낮은 entity가 처리량 높은 entity의 영향을 덜 받기 위한)
전송 실패
전송 실패할 경우의 여러 Case에 대해서 고민해본 내용입니다.
- Kafka Broker
Kafka 장애는 일어날 일이 거의 드물고, 발생했을 시 데이터 유실은 불가피합니다. 따라서 아예 별개의 모니터링 및 로그 적재가 필요합니다.
- Consumer
카프카 Consumer의 장애로 전송 실패가 일어나는 경우에 일반적으로 Kafka에서 사용하는 Retry 로직을 사용하는 경우 Data의 순서 보장이 되지 않습니다. 따라서 다른 방식의 해결법이 필요합니다.
돌고 돌아 Batch 로…
현재 솔루션에서 가장 중요한 것은 데이터 정합성입니다. 따라서 가장 간단하면서 정확한 방법인 Batch로 정합성을 맞추기로 결정했습니다. 두 테이블간 잘못된 데이터를 확인하고 Origin Table을 기준으로 데이터를 보정하고 Slack 알림을 보냈습니다. 대부분의 데이터는 Kafka를 통해 전송하고, 잔여 데이터를 Batch로 처리하는 것이기에 Batch 로 데이터를 보정해도 문제가 없었습니다.
Transaction
메세지 전송의 트랜잭션을 보장하기 위한 것은 여러 방식이 있습니다.
- Outbox Pattren 링크
로컬에 전송용 테이블을 따로 두고, Origin 테이블과 전송용 테이블에 Data를 동시에 Access하고 Commit 되면 그때 카프카 브로커에 전송하는 방식입니다. 따라서 DB 트랜잭션이 커밋된 이후에만 메세지가 전송되도록 보장할 수 있습니다. 그리고 App에서 보낸 순서대로 Produce 할 수 있습니다.
- Saga Pattern 을 이용한 분산 트랜잭션 링크
마이크로서비스 끼리 이벤트를 주고 받다 특정 서비스에서 작업이 실패하는 경우, 이전까지 완료된 작업들에 대해서 보상 이벤트를 보내 분산환경에서 원자성을 보장하는 패턴입니다. SAGA 패턴의 핵심은 트랜잭션의 관리 주체가 DB가 아닌 APP에 있다는 것입니다.
예를 들어 A - B App에서 DB가 MS로 연결되어 있다면 A 성공 후 B가 실패하는 경우 B에서 A를 향해 트랜잭션 실패 이벤트를 발행합니다. 그걸 받은 A는 트랜잭션 롤백을 합니다.
- Saga Pattern은 Choreography와 Orchestration 두가지 종류가 존재합니다
- Choreography는 이벤트를 순차적으로 받은 뒤 성공한 마지막 App에서 완료 트랜잭션을 보냅니다. 구성하기 편하지만, 트랜잭션의 현재 상태를 알기 어렵습니다.
- Orchestration은 중간에 Orchestration하는 Saga Instance가 별도로 존재해 트랜잭션 내의 App들은 모두 Saga를 거쳐가도록합니다. 인프라 구현은 복잡해지지만 트랜잭션 현재 상태를 쉽게 알고 롤백하기 쉽습니다.
이 방식들을 선택하지 않은 이유는, 해당 솔루션이 사용되는 곳에서 데이터 저장과 메세지 전송에 대한 원자적인 트랜잭션을 보장하지 않아도 되었기 때문입니다.
보다 정확한 요구 사항은 아래와 같습니다.
- 데이터가 전송된다면 정확한 데이터가 들어갈 것.
- 실패한다면 아예 실패할 것.
- 메세지 전송의 실패가 Origin 로직에 영향을 주지 말 것
즉, Transaction을 분리해 개발하는 것이 필요했습니다. 그리고 보정용 Batch를 따로 개발했기에 전송에 실패한 소수의 데이터들은 Batch 를 통해 보정이 맞춰져 별개의 데이터 유실을 걱정하지 않았습니다.
Logging & Monitoring
- 로깅 및 모니터링에 대해서도 고민이 많았지만, 구현하지 않았기에 짧게 줄입니다. 로깅과 모니터링은 어떠한 상황에서도 안정성이 보장이 되어야 합니다. 이에 본 목적을 위한 Application 설계보다 과한 엔지니어링을 해야합니다. 이에 목적에 비해
오버 엔지니어링이라는 판단이 들어 관련 사항은 폐기했습니다. - 결과적으로 데이터 정합성을 맞추기 위한 Batch에서 데이터 정합성이 맞지 않을 시 Slack 알람을 하고 있어, Batch가 모니터링의 역할을 어느 정도 수행하게 되었습니다.
개발하며 겪은 시행 착오

개발하다보니 문제점이 있었습니다. 일반적으로 spring-kafka에서는 KafkaTemplate을 이용해 Producing 합니다. 그리고 Schema Registry (AWS Glue)의 경우 KafkaTemplate별로 Schema를 지정할 수 있었습니다. 현재 구조는 Schema Registry는 DB Table 단위로 나누어져 있고, Topic은 도메인 기준으로 나누어져 있었습니다. 즉, 1개의 Topic에 여러 Schema를 적용하는 상황이었습니다.
일반적으로 1개의 KafkaTemplete에 1개의 Schema 를 등록하는 것이 기본이라 KafkaTemplate에는 1개의 Schema 설정이 가능합니다. 이에 좀 더 찾아보니 <Schema subject name strategy> 와 관련된 내용이 있었습니다. 링크
Default는 TopicNameStrategy 로 Topic name에서 Subject name이 파생됩니다. TopicNameStrategy, RecordNameStrategy, TopicRecordNameStrategy 세가지 옵션 중 TopicRecordNameStrategy의 경우 Topic 또는 Record Name에서 Subject name이 파생되며, 논리적으로 관련된 이벤트를 그룹화하는 방법이며, Subject 하에 여러 데이터 구조를 가질 수 있는 옵션입니다.
관련 자료를 찾아보면 주로 “동일한 Topic에 여러 Event를 보내는 경우” 링크 가 나오지만 이는 서로 다른 이벤트들을 그룹화해 하나의 토픽에 보내는 것으로 현재 제 구조에는 부적합했습니다.
또한 자료를 찾아봐도 주로 Schema Registry에 관련 자료일 뿐 Spring-kafka에서 어떻게 적용해야하는지에 대한 자료는 거의 없었습니다. 이에 고민을 하다 아래와 같이 코드를 적용했습니다.
- Producer yml
# TopicRecordNameStrategy 적용
spring:
kafka:
properties:
key.subject.name.strategy: io.confluent.kafka.serializers.subject.TopicRecordNameStrategy
value.subject.name.strategy: io.confluent.kafka.serializers.subject.TopicRecordNameStrategy
- Producer config
@Configuration
public class CouponProducerConfig {
// 각 Schema 별로 KafkaTemplate을 설정
@Bean
public KafkaTemplate<?, ?> couponKafkaTemplate(ProducerListener<Object, Object> kafkaProducerListener,
ObjectProvider<RecordMessageConverter> messageConverter) {
Map<String, Object> defaultProperties = pf.getConfigurationProperties();
LinkedHashMap<String, Object> props = new LinkedHashMap<>(defaultProperties);
props.put(AWSSchemaRegistryConstants.SCHEMA_NAME, CouponSchema.Coupon.getName()); // enum으로 Schema 정보 관리
props.put(AWSSchemaRegistryConstants.DESCRIPTION, CouponSchema.Coupon.getDescription());
return createKafkaTemplate(kafkaProducerListener, messageConverter, props);
}
@Bean
public KafkaTemplate<?, ?> couponHistoryKafkaTemplate(ProducerListener<Object, Object> kafkaProducerListener,
ObjectProvider<RecordMessageConverter> messageConverter) {
Map<String, Object> defaultProperties = pf.getConfigurationProperties();
LinkedHashMap<String, Object> props = new LinkedHashMap<>(defaultProperties);
props.put(AWSSchemaRegistryConstants.SCHEMA_NAME, CouponSchema.CouponHistory.getName());
props.put(AWSSchemaRegistryConstants.DESCRIPTION, CouponSchema.CouponHistory.getDescription());
return createKafkaTemplate(kafkaProducerListener, messageConverter, props);
}
...
private KafkaTemplate<Object, Object> createKafkaTemplate(ProducerListener<Object, Object> kafkaProducerListener,
ObjectProvider<RecordMessageConverter> messageConverter,
LinkedHashMap<String, Object> props) {
KafkaTemplate<Object, Object> kafkaTemplate = new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(props));
kafkaTemplate.setProducerListener(kafkaProducerListener);
messageConverter.ifUnique(kafkaTemplate::setMessageConverter);
return kafkaTemplate;
}
}
- Producer send
@Component
public class SyncCouponClient {
private static final String TOPIC_NAME = "coupon-topic";
private final KafkaTemplate<Object, Object> couponKafkaTemplate;
private final KafkaTemplate<Object, Object> couponHistoryKafkaTemplate;
public SyncCouponClient(@Qualifier("couponKafkaTemplate") KafkaTemplate<Object, Object> couponKafkaTemplate
, @Qualifier("couponHistoryKafkaTemplate") KafkaTemplate<Object, Object> couponHistoryKafkaTemplate) {
this.couponKafkaTemplate = couponKafkaTemplate;
this.couponHistoryKafkaTemplate = couponHistoryKafkaTemplate;
}
// Schema 마다 다른 KafkaTemplate 사용
public void produceForCouponAvro(SendType sendType, long pk, String query, CouponAvro receivedData) {
log.debug("produceForCouponAvro: sendType: {}, pk: {}, query: {}, receivedDate: {}", sendType, pk, query, receivedData);
receivedData.put("sendType", sendType);
receivedData.put("query", query);
couponKafkaTemplate.send(new ProducerRecord<>(TOPIC_NAME, pk, receivedData));
}
public void produceForCouponHistoryAvro(SendType sendType, long pk, String query, CouponHistoryAvro receivedData) {
log.debug("produceForCouponHistoryAvro: sendType: {}, pk: {}, query: {}, receivedDate: {}", sendType, pk, query, receivedData);
receivedData.put("sendType", sendType);
receivedData.put("query", query);
couponHistoryKafkaTemplate.send(new ProducerRecord<>(TOPIC_NAME, pk, receivedData));
}
}
- Consumer consume
@Service
@KafkaListener(topics = {"coupon-topic"}, groupId = "coupon-group", containerGroup = "coupon-group", containerFactory = "couponListenerContainerFactory")
@RequiredArgsConstructor
public class DownloadCouponConsumerService {
@NonNull
private final CupnSyncAdapter cupnSyncAdapter;
@KafkaHandler
public void listenToCouponAvro(@Payload CouponAvro receivedData,
ConsumerRecord<Long, CouponAvro> record) {
log.debug("listenToCouponAvro: sendType: {}, pk: {}, partition: {}, query: {}", receivedData.getSendType(), record.key(), record.partition(), receivedData.getQuery());
log.debug("received coupon-topic receivedData : {}", receivedData);
cupnSyncAdapter.sendCoupon(receivedData);
}
@KafkaHandler
public void listenToCouponHistoryAvro(@Payload CouponHistoryAvro receivedData,
ConsumerRecord<Long, CouponHistoryAvro> record) {
log.debug("listenToMtDwldCupnCrtfAvro: sendType: {}, pk: {}, partition: {}, query: {}", receivedData.getSendType(), record.key(), record.partition(), receivedData.getQuery());
log.debug("received coupon-topic receivedData : {}", receivedData);
cupnSyncAdapter.sendCouponHistory(receivedData);
}
...
}
@KafkaListener 내에 topics 지정 후 @KafkaHandler 의 @Payload 를 이용하면 객체의 타입별로 구분해 Consume 할 수 있습니다.
과정을 진행하며 느낀점
- 컴퓨터 공학은 추상적인 것을 구체화 하는 과정이며, 구체화를 하기 위해서는 많이 정보들이 필요합니다. 하지만 추상적인 정보만 수집하면 안됩니다. 당장 아는 만큼이라도 만들어야 합니다. 정보 수집만 할 수록 더 어렵게 느껴질 수 있습니다.
- 아무 것도 없는 상황에서 개발을 해야한다면, Google, 사내 Wiki, Conference 영상, 관련 기술 모임, 팀장님 팀원들부터 다른 팀 분들 그리고 사돈의 팔촌까지 온갖 인적 자원 등을 적극적으로 활용해야합니다. 개인적으로는 “카프카 한국 사용자 모임”의 질의 응답도 꽤 도움이 되었습니다.
- 오버엔지니어링을 경계해야합니다. Avro를 적용함으로써 좀 더 안정적이고, 앞으로 데이터를 활용한다면 해당 플랫폼의 확장성이 좋겠지만, 다시 생각해보면 현재는 데이터를 활용할 계획이 없고, DB Table의 field 추가는 자주 일어나지 않으며, 이미 Batch로 잘못된 잔여 데이터의 정합성을 맞춘다면, 현재의 요구 사항에서는 Avro까지는 필요 없을 수도 있겠다는 생각이 듭니다.
- 명확한 요구 사항의 중요성을 알았습니다. 기존의 잘 몰랐을 때는 (사실 지금도 잘 모릅니다.) 데이터의 순서도 유지되면서 성능도 좋은
우주최강플랫폼을 생각했으나 그 둘은 공존할 수 없었습니다. (우주최강개발자는 가능할지도..) 결국 여러 번의 토의 끝에 데이터의 순서대로 동기화해 데이터의 정합성을 우선시하기로 했습니다. - 작은 프로토 타입을 빠르게 먼저 만드는 것이 중요하다는 생각이 들었습니다. 위와 같은 여러 번의 요구사항의 수정으로 이미 개발한 코드의 수정도 잦았습니다. 작은 프로토 타입을 빠르게 만들었다면 나 혼자 아는 로직에 대해 팀원들에게 좀 더 쉽게 의견을 구할 수 있지 않았을까 생각이 듭니다. 결과적으로 동기화 대상이 꽤 많았는데 절반 이상의 개발이 이루어진 것도 설계가 변경되서 3번을 엎고 다시 개발하는 과정을 거쳤습니다.
- 따라서 설계 변경은 신중하게 해야겠지만 퀵하게 해야합니다. 늦었다 생각할 때가 늦었습니다.. 하지만 더 늦기 전에 바꿔야 합니다..
- 너무 완벽하려고 제 능력보다 너무 어렵게 생각했습니다. 가장 중요한 것은 Make it work. 고 수준이 아니어도 우선 돌아가게 만드는 것이 중요합니다.
- No Silver Bullet. 은총알은 없습니다. 명확한 요구 사항에 맞는 프로그램만 있을 뿐 완벽한 약점 없는 프로그램은 없습니다.
마치며..
모든 개발은 지나고 나면, “지금 다시하면 더 잘할 수 있을텐데” 하고 아쉬움이 남는 것 같습니다.
지나온 과정에 대하여 좀 더 숙고하고, 지금의 아쉬운 점에 대해 다음에 동일한 이유로 아쉽지 않도록 성장하는 개발자가 되려고 합니다.
긴 글 읽어주셔서 감사합니다. 🙇