Live11 과 Schema Registry
안녕하세요. 11번가 Tech 플랫폼 개발팀에서 Live11 서비스를 개발하고 있는 유예본입니다.
11번가의 라이브방송 서비스인 Live11 에서는 Kafka 와 함께 Schema Registry 를 어떻게 사용하고 있는지 Compatibility (호환성) 를 중심으로 이야기 해보려고 합니다.
Schema Registry 나 Schema 는 특정 언어에 종속적이지 않지만 본 글에서는 자바 애플리케이션에서 사용하는 경우로 제한하여 적어 보았습니다.
목차
- Live11 Architecture
- Schema Registry 도입
- Schema Registry 는 어떻게 동작?
- Schema 정의는 어떻게?
- Schema Evolution
- Compatibility
- 마무리
- 참고자료
Live11 Architecture
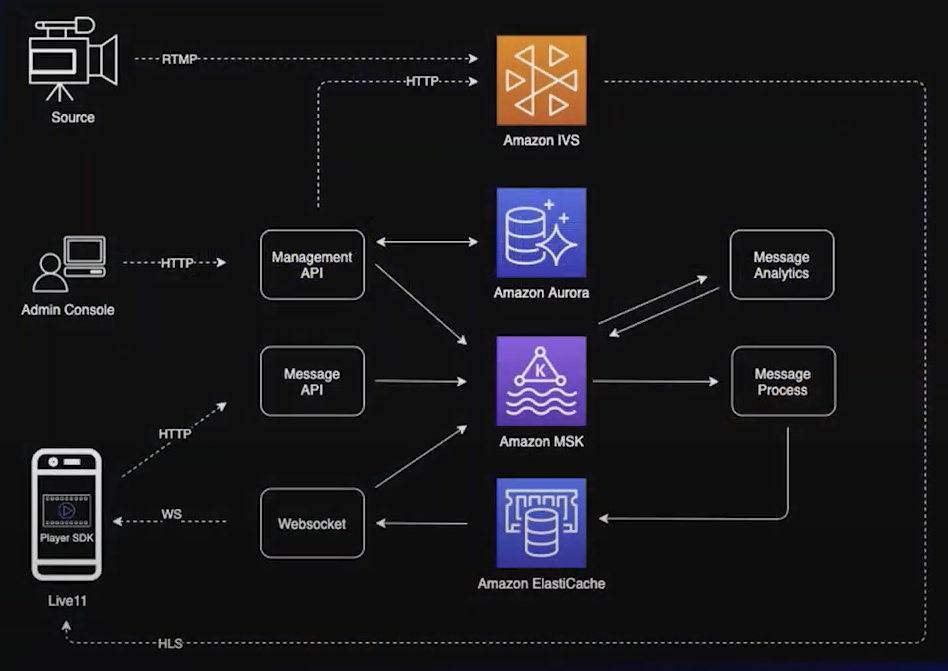
AWS re:Invent 2021 - Amazon IVS를 이용한 11번가 라이브 커머스 플랫폼 구축 영상에서 소개하고 있지만 라이브 방송을 구성하고 있는 많은 요소들 (채팅, 좋아요, 통계, Admin 에서의 변경사항 등) 이 Kafka 를 거치게 됩니다.
즉, 여러개의 Producer 와 Consumer 를 가지게 되는데 이로 인해 Producer 가 전달한 메시지를 Consumer 가 해석할 수 없으면 정상적인 서비스를 할 수 없습니다.
Kafka topic 으로 전달되는 데이터 타입을 정의한 DTO 클래스들을 모아둔 공통의 jar 를 Producer 앱과 Consumer 앱에서 각각 가지고 있는 형태로 사용할 수 있을 것 같습니다.
DTO 의 필드가 변경되면 어떻게 될까요?
필드의 타입이나 이름이 변경된다면 Consumer 에서 해석하지 못하는 메시지를 Producer 가 전송하게 될 수도 있는데 막을 수 있는 방법은 조심하는 방법밖에는 없습니다.
DTO 에 변경사항이 발생해서 적용할때 배포는 Producer 쪽을 먼저해야 하나요? Consumer 를 먼저 해야 하나요?
어떤 변경이 어떤 영향을 주게 될지 잘 모르겠습니다. 변경이 생길때 마다 영향범위를 체크하고 이상이 없을지 충분히 테스트하고 배포해야합니다.
Producer 가 json 포맷으로 메시지를 serialize 해서 Kafka topic 에 전달하면 topic 에는 json 프로퍼티의 key 값을 반복적으로 저장하게 될텐데 디스크 낭비 아닌가요?
낭비입니다.
Producer 는 Consumer 가 해석할 수 있는 메시지만을 전달하도록 할 수는 없을까요?
이러한 고민들을 하고 있다면 Schema Registry 도입을 고려 해볼만 합니다.
Schema Registry 도입
Schema Registry 를 사용하면 Producer 와 Consumer 간에 주고받을 수 있는 포맷을 schema 로 정의하고, 호환 가능한 형태의 메시지만을 주고 받도록 제한 할 수 있습니다.
변경사항이 반영된 새로운 schema 가 등록될때 호환성 여부를 체크하여 호환이 되지 않는 schema 는 아예 등록이 되지 않도록 막을 수 있기 때문입니다.
이러한 schema 들을 관리하고, Producer 와 Consumer 에게 제공하는 기능을 하는 것이 Schema Registry 의 역할 중 하나입니다. schema 가 외부로 분리되기 때문에 실제 Kafka topic 에 기록되는 메시지는 schema 에 대한 식별자와, (동일한 schema 에서도 달라지는) ‘값’만 저장하게 됩니다. json 을 기반으로 전송할 때와 비교했을때 디스크 사용량을 줄일 수 있습니다.
디스크 사용량을 줄일 수 있다는 것은 큰 장점입니다. 수많은 로그데이터를 Kafka 로 보내는 구조를 가지는 데이터 엔지니어링 플랫폼이라면 schema 를 외부로 분리하여 ‘값’만 저장해서 디스크 사용량을 줄이는게 큰 도움이 될 것 같습니다. (하지만, Live11 에서 Schema Registry 도입을 결정할때에는 호환성을 보장하기 위한 것이 주된 이유였고 디스크 사용량을 줄이는 것은 부수적인 이득이었습니다.)
Schema Registry 가 어떻게 사용 되는지를 보면 조금 더 이해가 쉬울 것 같습니다.
Schema Registry 는 어떻게 동작?
핵심이 되는 내용은 Kafka 를 개발한 사람들이 쓴 책 “Kafka: The Definitive Guide” 에 짧고 굵게 설명되어 있습니다.
(2021 년 11월에 2nd edition 이 출간되었고 Confluent 공식 사이트에서 무료로 PDF 파일을 다운
받을 수 있습니다.)
책에 언급된 설명 (p66, 2nd edition) 을 요약하면 아래와 같습니다.
- Kafka 로 데이터를 write 하는데 사용되는 모든 schema 들을 registry 에 저장 (저장된 schema 들은 고유한 identifier 를 가짐)
- produce 할때는 schema 의 identifier 를 record 에 달아서 produce
- consumer 는 그 identifier 를 가지고 Schema Registry 에서 schema 를 가져와서 deserialize
- 이 과정은 serializer/deserializer 에서 이루어진다는 것이 핵심
- 위 과정을 표현한 것이 아래 그림

이 과정은 serializer, deserializer 에서 이루어진다는 것이 핵심이라고 하는데
Confluent 에서 제공하는 KafkaAvroSerializer, KafkaAvroDeserializer 나
AWS Glue Schema Registry 에서 제공하는 AWSKafkaAvroSerializer, AWSKafkaAvroDeserializer 나
모두 org.apache.kafka.common.serialization 패키지의 Serializer, Deserializer 인터페이스를 구현하고 있습니다.
Live11 에서는 AWS Glue Schema Registry 를 사용하고 있으니 AWSKafkaAvroSerializer, AWSKafkaAvroDeserializer 구현을 한번 보겠습니다. (schema-registry-serde library 1.0.2 기준)
AWSKafkaAvroSerializer (produce)
serializer 는 schema 정보를 캐싱하고 있습니다. 그러므로 record 를 produce 할때마다 Schema Registry 와 통신을 해야하는 것은 아닙니다. producer 가 Kafka 로 데이터를 전송할때 serializer 내부에서 캐싱하고 있는 schema 가 있으면 Schema Registry 와의 통신을 하지 않고 캐싱된 schema 의 identifier 를 사용합니다. serializer 가 캐싱하고 있는 schema 가 아니라면 Schema Registry 와 통신하여 schema 를 등록하고 identifier 를 받아옵니다. 이 identifier 를 record 에 달아서 produce 하게 됩니다.
- serialize 시작: Serializer 인터페이스 구현 메서드. schemaVersionId 가 없으면 registerSchema 를 호출.
- registerSchema: getOrRegisterSchemaVersion 를 호출하기만 함.
- getOrRegisterSchemaVersion 시작
- Avro schema 를 가지고 Schema 라는 자바객체를 생성해서 cache 를 먼저 조회.
- 사용하고 있는 AWSCache: Key 는 Schema 객체. Value 는 UUID (identifier). 즉, cache 에서 Schema 로 identifier 를 찾음.
- cache 에서 serialize 하려는 데이터의 schema 로 identifier 를 찾을 수 있으면 반환.
- cache 에서 해당 schema 를 찾을 수 없을 경우 getORRegisterSchemaVersionId 를 호출.
- getORRegisterSchemaVersionId
- AWSSchemaRegistryClient 클래스에 있는 메서드로, Schema Registry 와 네트워크 통신을 하는 부분.
- 해당 schema 에 대한 버전이 존재하지 않거나, schema 자체가 존재하지 않을 경우 Schema Registry 에 등록하고 identifier 를 반환함.
- getOrRegisterSchemaVersion 종료: identifier 를 가져왔으니 cache 에 추가하고 identifier 를 반환.
- serialize 종료: identifier 정보를 가지고 data 와 함께 serialize 하여 byte[] 를 반환.
AWSKafkaAvroDeserializer (consumer)
deserializer 또한 schema 정보를 캐싱하고 있습니다. 그러므로 record 를 consume 할때마다 Schema Registry 와 통신을 해야하는 것은 아닙니다. consumer 는 Kafka 로부터 record 를 읽어와서 identifier 부분을 record 에서 떼어냅니다. 이 identifier 에 해당하는 schema 가 deserializer 내부 캐시에 존재하면 Schema Registry 와의 통신을 하지 않고 캐싱해둔 schema 를 사용합니다. identifier 에 해당하는 schema 가 deserializer 내부 캐시에 존재하지 않으면 Schema Registry 와 통신해서 해당 identifier 에 맞는 schema 를 받아와서 deserialize 작업을 진행하게 됩니다.
(아래 1~3은 부수적인 처리 과정이어서 4번만 참고하셔도 됩니다.)
- deserialize 시작
- header version byte 를 가지고 오는데 secondary deserializer 를 사용할 것인지에 대한 정보를 담고 있는 것으로, identifier 정보는 아님.
- deserializeByHeaderVersionByte 를 호출.
- deserializeByHeaderVersionByte
- secondaryDeserializer 를 별도로 지정하지 않았으므로 AWSDeserializer 의 deserialize 호출.
- AWSDeserializer#deserialize 시작
- getAwsDeserializerSchema(4번) 에서 UUID 와 Schema 를 가지는 AwsDeserializerSchema 를 반환.
- getAwsDeserializerSchema
- getSchemaVersionId: consume 해온 byte[] 로 부터 UUID (identifier) 를 추출.
- retrieveSchemaRegistrySchema
- identifier 로 cache 조회.
- 사용하고 있는 AWSCache: Key 는 UUID (identifier). Value 는 Schema 객체. 즉, cache 에서 identifier 로 Schema 를 찾음.
- 해당 identifier 를 가진 Schema 객체가 cache 에 있으면 바로 반환.
- cache 에 없으면 identifier 로 Schema Registry 를 조회 (네트워크 통신) 하여 Schema 를 받아옴.
- AWSDeserializer#deserialize 종료: identifier 정보를 가지고 byte[] 를 Object 로 변환해서 호출스택을 타고 반환하면서 종료됨.
캐싱하는 부분을 제외하고 보면 produce 할때는 (Schema Registry 에서 관리하는) schema 를 식별할 수 있는 identifier 를 record 에 달아서 produce 하고, consumer 는 그 identifier 를 가지고 Schema Registry 에서 schema 를 가져와서 deserialize 하며, 이 과정은 serializer/deserializer 에서 이루어진다는 설명과 동일하게 동작합니다. AWS Glue Developer Guide - How the Schema Registry Works 에서도 같은 설명을 하고 있습니다.
Schema Registry 가 어떻게 동작하는지는 확인해 보았습니다. 그러면 이 Schema 는 어떻게 만드는 것일까요?
Schema 정의는 어떻게?
schema 를 정의하는데에는 Avro, JSON Schema, Protobuf, Parquet 등 다양한 포맷이 사용될 수 있고, Live11 에서는 Avro 를 사용하고 있습니다. 이 글도 Live11 에서 사용하고 있는 Avro 를 기준으로 작성하였습니다.
개발당시 Live11 에서 사용하고 있는 AWS Glue Schema Registry 에서는 Avro, JSON Schema 만을 지원하고 있었습니다. 2022년 2월 부터 Protobuf 도 지원합니다. Live11 에서 JSON Schema 가 아닌 Avro 를 선택한데에 특별한 이유가 있지는 않습니다. 다만, Confluent 문서나 Kafka: The Definitive Guide (Kafka 개발한 사람들이 쓴 책) 에서 Avro 를 기준으로 설명하는 내용이 많아서 Avro 를 사용하게 되었습니다.
아래는 Avro 를 사용한 schema 정의의 예시인데, 이 글에서는 Avro 에 대해서는 자세히 다루지 않습니다. Schema 를 정의하는 포맷 중 하나로 json 과 같은 형태이다 정도만 기억하면 될 것 같습니다. Avro 에 대한 자세한 내용은 Apache Avro™ 1.11.0 Specification 참고 부탁드립니다.
{
"name": "live11.message.schema.avro.User",
"type": "record",
"fields": [
{"name": "id", "type": "string"},
{"name": "address", "type": ["null", "string"], "default": null}
]
}
Java Class 자동 생성
Avro 포맷에 맞게 schema 파일을 정의했지만 자바 애플리케이션에서 사용하기 위해서는 자바 객체로 serialize/deserialize 하는 과정이 결국 필요합니다. Schema Registry 를 사용해도, java 객체를 기반으로 serialize/deserialize 하기 위해서는 Producer 와 Consumer 에서 같은 클래스를 가지고 있어야 하는 것은 동일합니다.
작성한 *.avsc 파일을 기반으로 자바 클래스를 자동 생성해주는 plugin 이 있습니다.
- Maven 을 사용중이라면 Apache Avro™ 1.11.0 Getting Started (Java) 에서 가이드 하고 있는 Schema Registry Maven Plugin 을 사용할 수 있습니다.
- Gradle 을 사용중이면 gradle-avro-plugin 을 사용할 수 있습니다.
- Gradle 을 사용중이고 Confluent Schema Registry 를 사용한다면 ImFlog/schema-registry-plugin 을 사용할 수 있습니다.
(글을 작성중인 2022년 6월 기준, 공식적으로 지원하는 gradle plugin 은 없는 것 같습니다.)
Live11 에서는 AWS Glue Schema Registry 를 사용하고 있고, Gradle 로 빌드하고 있어서 gradle-avro-plugin 를 사용하고 있습니다. 위에서 예시로 본 schema 를 기반으로 gradle-avro-plugin 을 사용해서 자동 생성된 자바 클래스의 일부입니다.
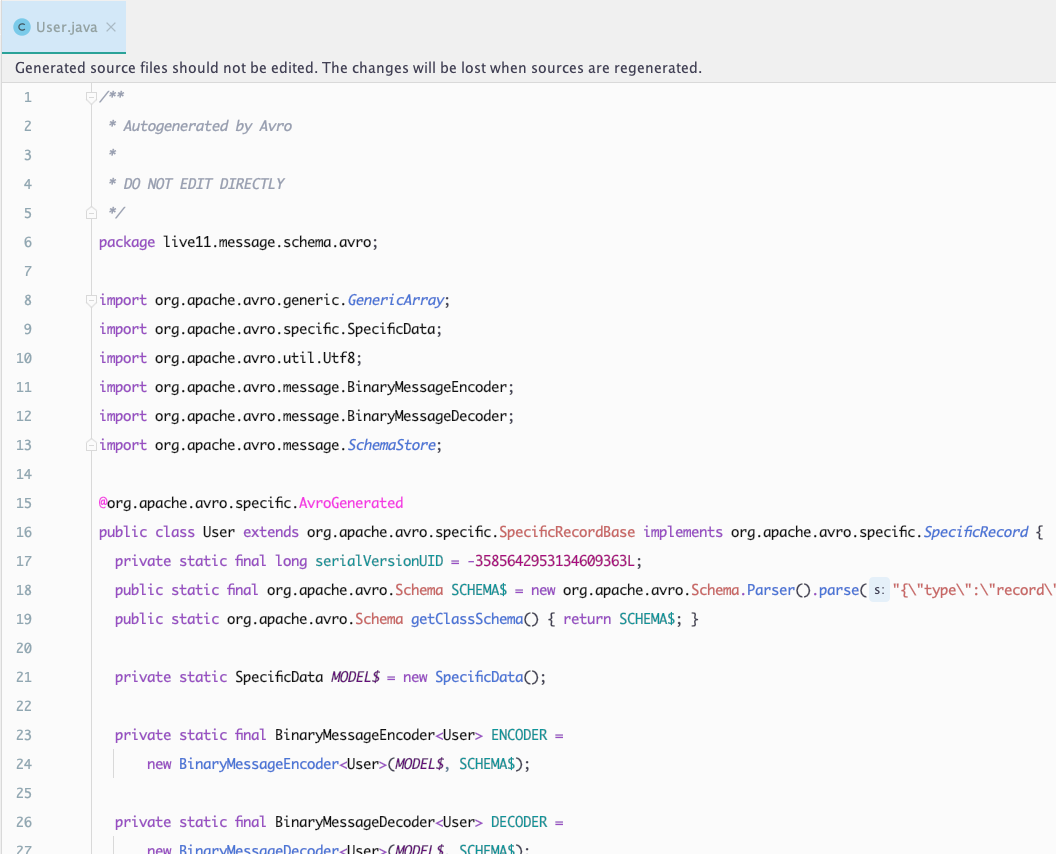
지금까지 Schema Registry 가 어떤 경우에 필요한지, 어떻게 동작하는지, Schema 는 어떻게 정의하고 자바 애플리케이션에서는 어떻게 사용할 수 있는지 살펴보았습니다.
Schema Evolution
schema 는 처음 사용한 형태로 계속 사용될 수도 있지만 요구사항이 변함에 따라 다양한 형태로 변화(진화)할 수 있는데 이것을 Schema Evolution 이라고 합니다. 이렇게 변경이 생겨서 완전히 일치하지는 않는 두개의 서로 다른 schema 로 write/read 가 발생할때 어떻게 resolve 되는지에 대한 내용이 Avro Documentation - Schema Resolution 에 자세히 설명되어 있습니다.
schema 를 변경할때 (Schema Evolution) 어떤점을 주의해야 하는지에 대해서 Getting Started with Oracle NoSQL Database Key/Value API 의 Chapter 7. Avro Schemas - Schema Evolution 내용을 보니 조금 더 직관적으로 이해할 수 있었습니다.
슬쩍 읽어보니 default value 가 있으면 필드의 추가/제거가 자유로운 것 같습니다.

“Rules for Changing Schema” 섹션에서는 항상 default value 를 추가하라고 하기도 합니다.

왜 default value 가 그렇게 중요한가요?
이유를 알기 위해서 Compatibility 개념에 대한 내용을 짚고 넘어가면 좋을 것 같습니다.
Compatibility
Schema Registry 를 사용하지 않는 상태에서 schema 가 변경되었고 변경된 schema 를 가지고 producer 가 produce 하면 consumer 가 해석하지 못하는 (deserialize 할 수 없는) 메시지를 전달하게 될 수도 있습니다. 이런 일이 발생하지 않도록 Schema Registry 를 사용하여 애초에 schema 가 변경될때 이전 버전의 schema 와 호환이 되는지 확인하고, 호환 가능한 schema 만 등록하여 produce 하도록 제한 할 수 있습니다. Schema Registry 에서는 schema 를 변경할때 어떠한 변경사항을 제한할 것인지 Compatibility Type 을 지정해서 그 규칙을 정할 수 있습니다.
이 주제에 대해서 Confluent 문서 Schema Evolution and Compatibility - Compatibility Types 에 잘 설명이 되어 있는데 어려운 내용이 아닌 것 같으면서도 많이 헷갈려서 이해하기까지 생각보다 시간이 오래 걸렸습니다.
먼저 문서에 나와있는 표를 한번 보겠습니다.
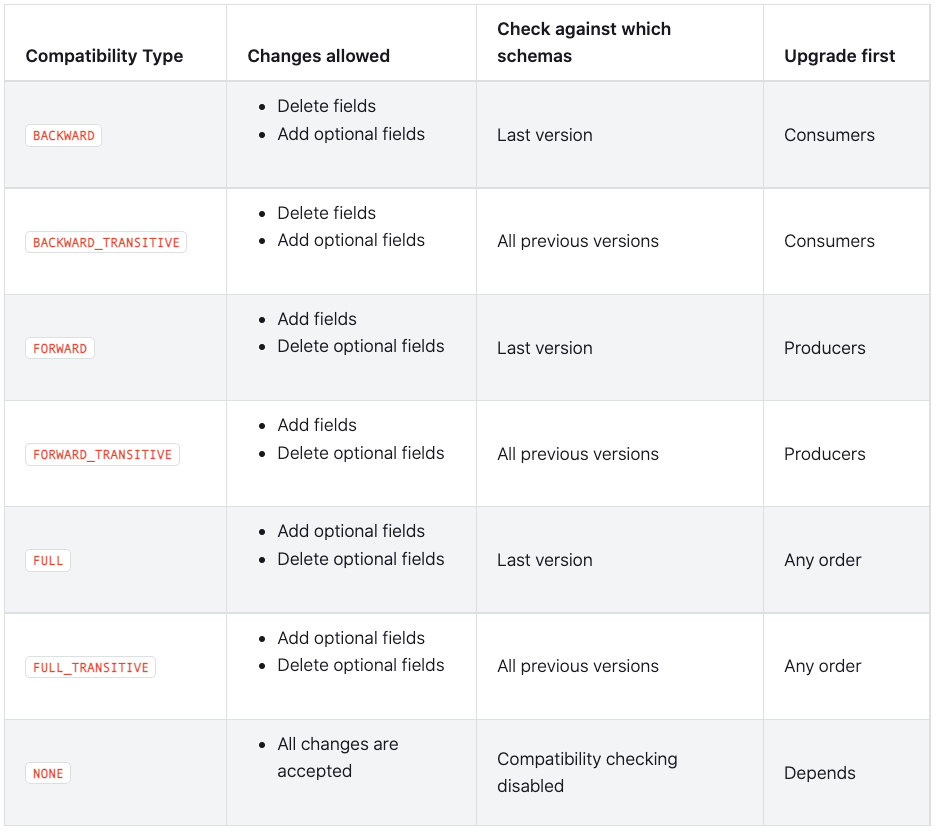
컬럼의 의미를 간략히 설명하면 아래와 같습니다.
- Compatibility Type: 호환성 타입
- Changes allowed: 각 Compatibility Type 에서 허용 되는 Schema Evolution (즉, 새로운 schema 를 등록 가능한 경우)
- Check against which schemas: schema 를 등록할때 어떤 버전과의 호환성을 체크하는지
- Upgrade first: producer, consumer 중 어느쪽에 먼저 새로운 schema 를 적용해야 하는지
Compatibility Type 에는 여러가지가 있는데 이 중에서 BACKWARD, FORWARD 에 대한 개념만 이해하면 다른 타입도 이해할 수 있기 때문에 이 두가지에 대해 자세히 살펴보겠습니다.
Compatibility Type 을 BACKWARD 로 지정하면 BACKWARD Compatible Schema Evolution 의 경우에만 schema 를 등록할 수 있다는 의미이고, Compatibility Type 을 FORWARD 로 지정하면 FORWARD Compatible Schema Evolution 의 경우에만 schema 를 등록할 수 있다는 의미입니다.
그렇다면 BACKWARD Compatible Schema Evolution 은 무엇인지, FORWARD Compatible Schema Evolution 은 무엇인지 알아야 할 것 같습니다.
Confluent 문서에서 BACKWARD, FORWARD 에 대해서 각각 아래와 같이 설명하고 있습니다.
(이 글에서는 Schema 로는 Avro 포맷을 사용한다고 가정하고, old schema (last schema) 를 말할때는 v1, new schema 를 말할때는 v2 라고 하겠습니다.)
BACKWARD compatibility means that consumers using the new schema can read data produced with the last schema.
(v1 의 스키마로 produce 된 메시지를 v2 의 스키마를 가진 consumer 에서 read 가능)
FORWARD compatibility means that data produced with a new schema can be read by consumers using the last schema.
(v2 의 스키마로 produce 된 메시지를 v1 의 스키마를 가진 consumer 에서 read 가능)
문서를 차근차근 읽으면 이해가 될 것 같으면서도 참 헷갈리는 것 같습니다. 이것을 조금 더 쉽게 이해할 수 있도록 제가 이해한 방식을 적어 보겠습니다.
모든것을 read 를 기준으로 생각합니다.
BACKWARD, 뭔가 단어에서 뒤쪽으로(BACK) 호환이 되어야 할 것 같은 느낌입니다.
BACKWARD 를 아래와 같이 표현할 수 있을 것 같습니다.
v1 ← (read) v2
- v2 가 v1 을 read 가능. (consumers using the new schema can read data produced with the last schema.)
- 뒤쪽으로 읽을 수 있으니 BACKWARD.
FORWARD, 뭔가 단어에서 앞쪽으로(FORE) 호환이 되어야 할 것 같은 느낌입니다.
FORWARD 는 아래와 같이 표현할 수 있을 것 같습니다.
v1 (read) → v2
- v1 이 v2 를 read 가능. (produced with a new schema can be read by consumers using the last schema.)
- 앞쪽으로 읽을 수 있으니 FORWARD.
“읽을 수 있다” 라는 표현이 좀 모호한데, “Deserialize Exception 이 발생하지 않는다” 는 의미입니다.
참 쉽죠?
표로 돌아가서 BACKWARD, FORWARD 만 따로따로 한번 보겠습니다.
BACKWARD
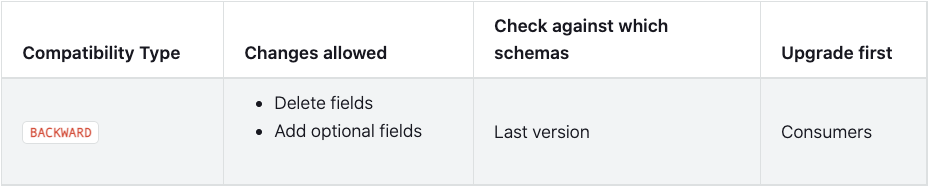
BACKWARD 에서는 왜 어떤 필드든 제거할 수 있고 (Delete fields), optional field 만 추가할 수 있을까요?
(optional field 로 여겨지는 필드는 더 다양하지만, 지금은 default 값이 지정되어 있는 필드만을 이야기 하겠습니다.)
아래와 같은 v1, v2 schema 가 있다고 가정해 보겠습니다.

그리고 BACKWARD 는 아래와 같이 표현할 수 있었습니다.
v1 ← (read) v2
BACKWARD compatibility 를 만족 하기 위해서는 v2 로 v1 을 읽을 수 있어야 합니다. 위 예시에서는 v2 로 v1 을 읽을 수 있습니다. v2 로 v1 을 읽을때 “name” 필드가 누락이 되기는 하겠지만 Deserialize Exception 이 발생하지는 않습니다. v2 에 정의되지 않은 필드가 들어오면 그냥 누락시키면 그만이기 때문입니다.
즉, v1 schema 를 가지고 produce 한 메시지를 v2 schema 를 가지는 consumer 가 Deserialize Exception 을 발생시키지 않고 처리가 가능합니다. (하지만 누락되는 필드는 생길 수 있습니다.)
그러면 반대는 어떻게 될까요? v1 으로 v2 를 읽을 수 있을까요? 그렇지 않습니다.
v1 이 v2 를 읽을때 “name” 필드는 default 값이 지정되어 있지 않습니다. default 값이 지정되어 있지 않은 필드는 반드시 값이 채워져서 들어와야 합니다. 그런데 v2 는 “name” 필드를 가지고 있지 않기 때문에 “name” 필드는 값이 채워져서 전달될 수가 없습니다. 즉, v2 schema 를 가지고 produce 한 메시지를 v1 schema 로 deserialize 하려고 하면 Deserialize Exception 이 발생하게 됩니다.
(이 내용을 기억하고) 표의 마지막 컬럼 Upgrade first 를 다시 보면, Compatibility Type 이 BACKWARD 일때는 Consumer 를 먼저 upgrade 하라고 나옵니다. 왜 일까요? Producer 를 먼저 upgrade 할 경우 v2 schema 로 produce 를 하게되고, 이는 v1 schema 를 가진 consumer 가 v2 를 읽어야 하는 상황이 됩니다. 이 상황은 Deserialize Exception 이 발생하는 상황이었습니다. 그렇기 때문에 Compatibility Type 이 BACKWARD 일 경우에는 Consumer 를 먼저 upgrade 해야 Deserialize Exception 없이 Schema Evolution 을 할 수 있습니다.
하나의 예시를 보았으니 다시 질문으로 돌아와 보겠습니다.
BACKWARD 에서는 왜 어떤 필드든 제거할 수 있고 (Delete fields), optional field 만 추가할 수 있을까요?
위 예시에서 v1 에서 v2 로 변경될때 “name” 필드를 제거했는데 “name” 필드는 default 값이 없었음에도 제거가 가능했습니다.
default 값이 있는 필드를 제거하면 어떻게 될까요?
v2 로 v1 을 읽을 수 있으므로 BACKWARD Compatible Schema Evolution 이며 v2 schema 를 등록할 수 있습니다.

default 값이 있는 필드를 추가하면 어떻게 될까요?
이것도 가능합니다. “email” 필드가 v2 에는 정의되어 있고 v1 에는 정의되어 있지 않아서 v1 으로 produce 할때 email 값은 채워지지 않지만, v2 schema 에 default 값이 정의되어 있으므로 default 값이 사용되어 Deserialize Exception 이 발생하지 않습니다. 즉, v2 로 v1 을 읽을 수 있으므로 BACKWARD Compatible Schema Evolution 이며 v2 schema 를 등록할 수 있습니다.
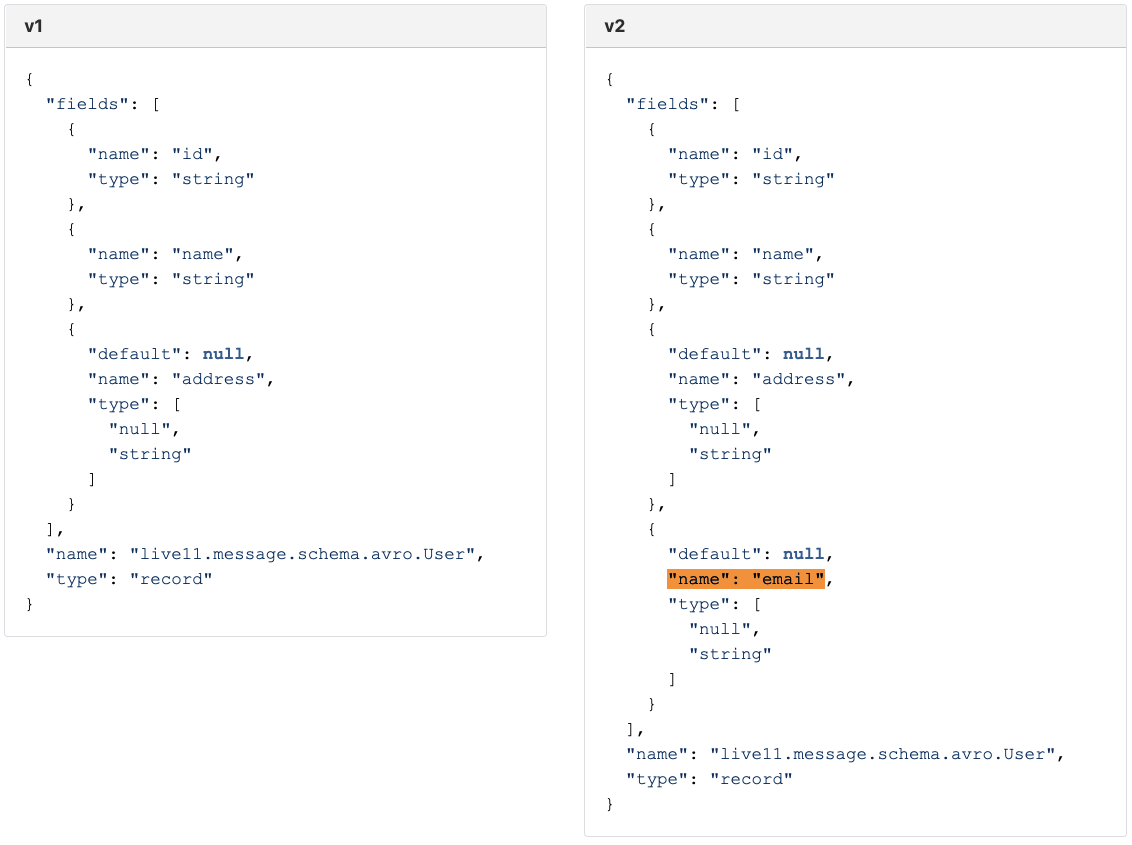
그러면 default 값이 없는 필드를 추가하면 어떻게 될까요?
v2 로 v1 을 읽을 수 없기 때문에 BACKWARD Compatible Schema Evolution 이 아니므로 v2 schema 를 등록할 수 없습니다. (하지만 이것은 FORWARD Compatible Schema Evolution 이므로 Compatibility Type 이 FORWARD 로 지정되어 있다면 등록이 가능합니다.)

막 어렵다기 보다는 헷갈리는데 그래도 여기까지 이해했으면 거의 다 왔습니다.
FORWARD
FORWARD 는 BACKWARD 와 반대라고 생각하면 됩니다.
아래 설명을 읽다보면 아시겠지만 BACKWARD 내용과 데칼코마니 같은 설명입니다.

FORWARD 에서는 왜 어떤 필드든 추가할 수 있고 (Add fields), optional field 만 제거할 수 있을까요?
아래와 같은 v1, v2 schema 가 있다고 가정해 보겠습니다.
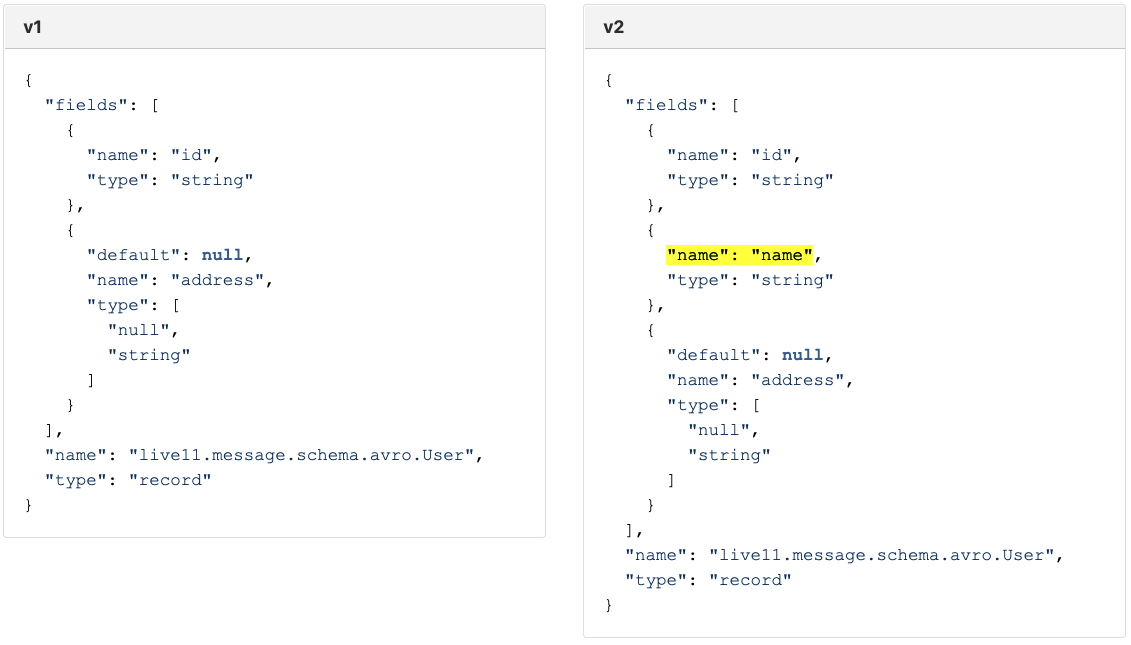
그리고 FORWARD 는 아래와 같이 표현할 수 있었습니다.
v1 (read) → v2
FORWARD compatibility 를 만족 하기 위해서는 v1 으로 v2 를 읽을 수 있어야 합니다. 위 예시에서는 v1 으로 v2 를 읽을 수 있습니다. v1 으로 v2 을 읽을때 “name” 필드가 누락이 되기는 하겠지만 Deserialize Exception 이 발생하지는 않습니다. v2 에 정의되지 않은 필드가 들어오면 그냥 누락시키면 그만이기 때문입니다.
즉, v2 schema 를 가지고 produce 한 메시지를 v1 schema 를 가지는 consumer 가 Deserialize Exception 을 발생시키지 않고 처리가 가능합니다. (하지만 누락되는 필드는 생길 수 있습니다.)
그러면 반대는 어떻게 될까요? v2 로 v1 을 읽을 수 있을까요? 그렇지 않습니다.
v2 가 v1 을 읽을때 “name” 필드는 default 값이 지정되어 있지 않습니다. default 값이 지정되어 있지 않은 필드는 반드시 값이 채워져서 들어와야 합니다. 그런데 v1 은 “name” 필드를 가지고 있지 않기 때문에 “name” 필드는 값이 채워져서 전달될 수가 없습니다. 즉, v1 schema 를 가지고 produce 한 메시지를 v2 schema 로 deserialize 하려고 하면 Deserialize Exception 이 발생하게 됩니다.
(이 내용을 기억하고) 표의 마지막 컬럼 Upgrade first 를 다시 보면, Compatibility Type 이 FORWARD 일때는 Producer 를 먼저 upgrade 하라고 나옵니다. 왜 일까요? Consumer 를 먼저 upgrade 할 경우 v1 schema 로 produce 를 한 메시지를, v2 schema 를 가진 consumer 가 읽어야 하는 상황이 됩니다. 이 상황은 Deserialize Exception 이 발생하는 상황이었습니다. 그렇기 때문에 Compatibility Type 이 FORWARD 일 경우에는 Producer 를 먼저 upgrade 해야 Deserialize Exception 없이 Schema Evolution 을 할 수 있습니다.
하나의 예시를 보았으니 다시 질문으로 돌아와 보겠습니다.
FORWARD 에서는 왜 어떤 필드든 추가할 수 있고 (Add fields), optional field 만 제거할 수 있을까요?
위 예시에서 v1 에서 v2 로 변경될때 “name” 필드를 추가했는데 “name” 필드는 default 값이 없었음에도 추가가 가능했습니다.
default 값이 있는 필드를 추가하면 어떻게 될까요?
“email” 필드가 v2 에는 정의되어 있고 v1 에는 정의되어 있지 않아서 v1 으로 consume 할때 email 값은 채워지지 않지만, v1 schema 에 정의되어 있지 않은 필드이므로 무시하면 그만입니다. 즉, v1 으로 v2 를 읽을 수 있으므로 FORWARD Compatible Schema Evolution 이며 v2 schema 를 등록할 수 있습니다.

default 값이 있는 필드를 제거하면 어떻게 될까요?
이것도 가능합니다. v1 으로 v2 를 읽을 수 있으므로 FORWARD Compatible Schema Evolution 이며 v2 schema 를 등록할 수 있습니다.
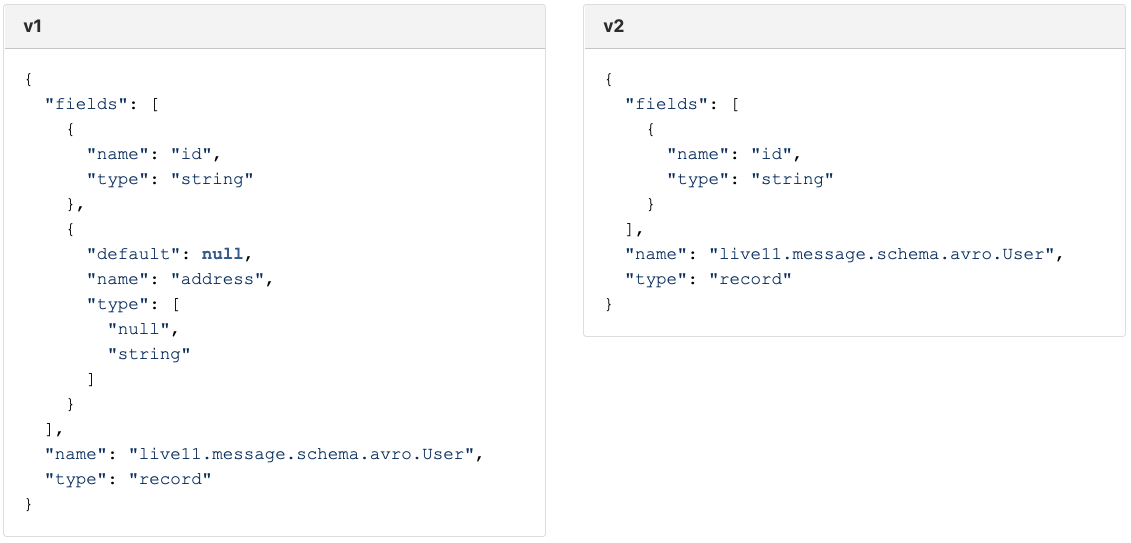
그러면 default 값이 없는 필드를 제거하면 어떻게 될까요?
v1 으로 v2 를 읽을 수 없기 때문에 FORWARD Compatible Schema Evolution 이 아니므로 v2 schema 를 등록할 수 없습니다. (하지만 이것은 BACKWARD Compatible Schema Evolution 이므로 Compatibility Type 이 BACKWARD 로 지정되어 있다면 등록이 가능합니다.)
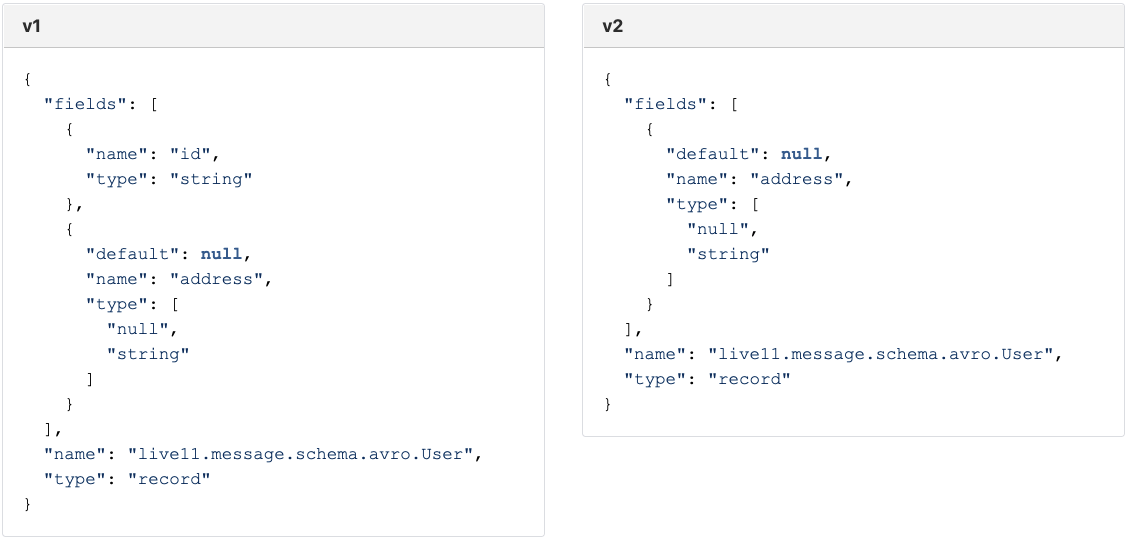
Compatibility 와 default 값
default 값이 있는 필드는 BACKWARD 나 FORWARD 나 추가/제거가 자유로웠던 반면, BACKWARD 에서는 default 값이 없는 필드를 추가할 수 없었고 FORWARD 에서는 default 값이 없는 필드를 제거할 수 없었습니다.
여기서 공통점을 찾을 수 있는데
default 값을 가지는 필드는 언제든 추가/제거가 가능하다는 것 입니다.
앞서 Chapter 7. Avro Schemas - Schema Evolution 의 Rules for Changing Schema 에서 왜 default 값을 강조했는지 알 것 같습니다.
Compatibility 표에서 설명하지 않은 부분
문서에 나와있는 표로 다시 돌아가 보겠습니다.
BACKWARD, FORWARD 를 이해했다면 다른 Compatibility Type 은 간단하게 정리됩니다.
- FULL: BACKWARD, FORWARD 를 모두 만족시키는 Schema Evolution 의 경우에만 schema 등록가능.
- NONE: Compatibility Type 사용 안함.
그런데 *_TRANSITIVE 라고 되어 있는건 뭘까요?
어떤 topic 의 schema 로 v1, v2 가 시간 순서대로 Schema Registry 에 등록되어있는 상태이고 v3 를 새롭게 추가하려고 하는 상황을 가정해보겠습니다. 이때, _TRANSITIVE 가 붙어있지 않은 Compatibility Type 들은 v3 와 v2 간에 호환성 여부만을 체크합니다. 그러나 _TRANSITIVE 가 붙어있는 Compatibility Type 들은 v3 가 v2 와 호환이 되는지도 체크하고, v3 가 v1 과 호환이 되는지도 체크하게 됩니다.
_TRANSITIVE 가 붙어있지 않은 Type 들도 v3 와 v1 간에 호환이 가능할 수도 있습니다. 그런데 불가능할 수도 있습니다. 반면, _TRANSITIVE 가 붙은 Type 은 항상 호환이 가능하다는 것을 보장할 수 있습니다. (그래야 등록이 되기 때문에)
즉, 새로운 schema 를 등록하는 시점에, _TRANSITIVE 가 없는 Type 은 직전에 등록되어 있는 latest 버전과 지금 등록하려는 schema 간에 호환이 되는지만 확인합니다. _TRANSITIVE 가 있는 Type 은 직전에 등록되어 있는 버전은 물론 그 이전에 등록되어 있었던 모든 버전들과 호환이 되어야 새로운 schema 를 등록할 수 있습니다.
(_TRANSITIVE 라는 용어는 Confluent Schema Registry 기준이고, AWS Glue Schema Registry 에서는 _ALL 이라는 용어로 사용되고 있습니다.)
그러면 표에 나오는 “Check against which schemas” 부분도 설명이 된 것 같습니다.
마무리
Live11 에서는 FULL 을 사용하고 있습니다.
Schema 에 변경이 생기면 배포하는 동안의 시간 외에는 producer 와 consumer 간에 서로 다른 schema version 을 사용하는 케이스가 거의 없을 것이기 때문에 _TRANSITIVE 까지 적용하는 것은 과하다고 판단했습니다.
그리고 배포할때 producer 와 consumer 어느쪽을 먼저하든 Deserialize Exception 이 발생하는 것을 막기 위해서 BACKWARD, FORWARD 호환성을 모두 만족시키는 FULL 을 사용하기로 결정했습니다.
FULL 을 사용하면서 필드의 추가/제거를 자유롭게 할 수 있도록 모든 필드에는 default 값을 지정하는 것 또한 컨벤션입니다.
참고한 자료
- [Confluent] Schema Registry Overview
- [Confluent] Schema Evolution and Compatibility
- Kafka: The Definitive Guide
- [AWS Glue] AWS Glue Schema Registry
- [AWS Glue] How the Schema Registry Works
- [Oracle] Getting Started with Oracle NoSQL Database Key/Value API - Chapter 7. Avro Schemas - Schema Evolution
- [Apache] Apache Avro™ 1.11.0 Specification