Service Discovery DR 구성 1부 - Eureka 서버를 지역 분산시켜 안정성을 높이자
spring , cloud , eureka , msa , service-discovery
안녕하세요. 11번가 Core플랫폼개발팀에서 MSA 플랫폼 Vine의 개발과 운영을 담당하고 있는 전지원입니다.
이번 Article에서는 Spring Cloud의 Service Discovery 컴포넌트인 Eureka 의 Disaster Recovery를 구성을 위해 내부 코드를 분석하여 어떻게 동작하는지 파악하고, 이에 따라 어떻게 구성하였는지 내용을 공유드리고자 합니다.
Background
11번가는 서비스의 높은 확장성과 간단한 통합 및 배포, 그리고 운영을 위해 2016년 거대한 Monolithic 서비스를 Microservice Architecture로 전환하는 프로젝트를 진행하였으며, 그 결과 Spring Cloud 기반의 Vine 플랫폼이 개발되어 현재 약 600여 개 인스턴스와 60여 개의 애플리케이션 서비스가 Vine 플랫폼 위에서 성공적으로 운영되고 있습니다.
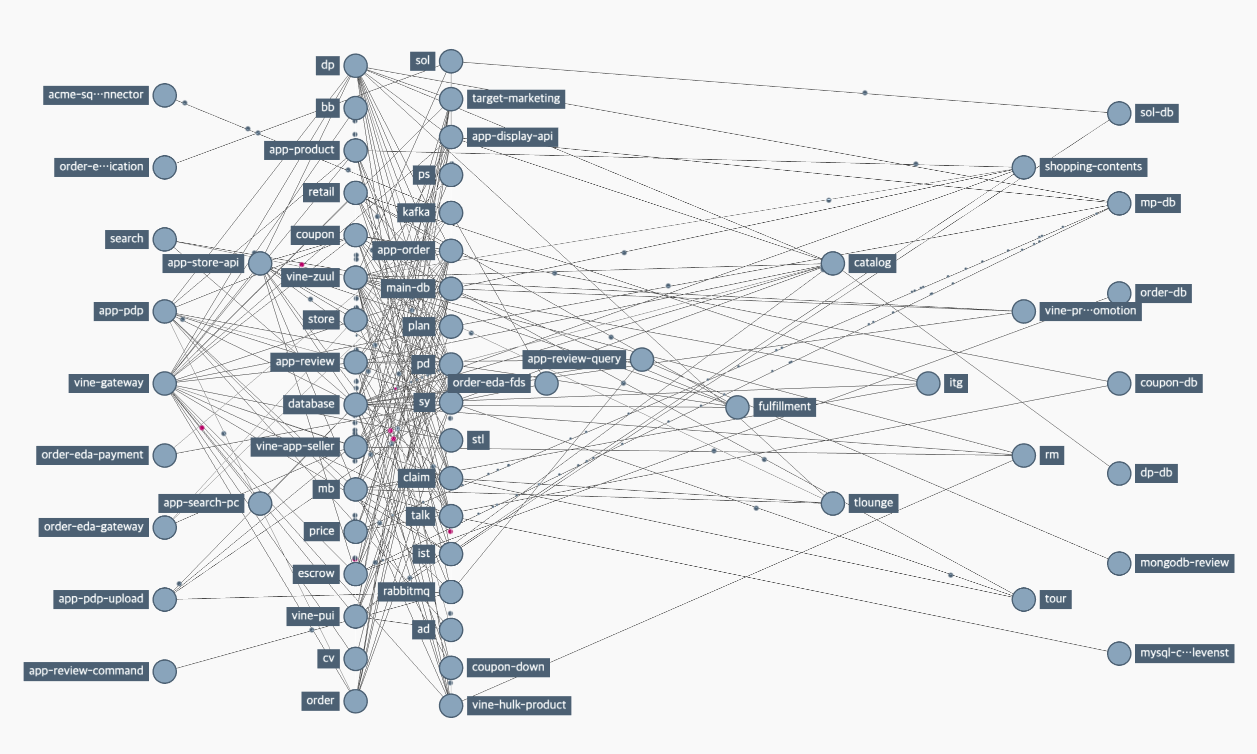
생성과 소멸을 반복하는 마이크로서비스가 서로를 인식하고 통신할 수 있도록, 인스턴스 자신의 동적으로 변화하는 주소를 등록하고 다른 인스턴스 정보를 검색할 수 있는 레지스트리가 필요한데, MSA 플랫폼 컴포넌트인 Service Discovery가 해당 역할을 담당하고 있습니다.
Spring Cloud ecosystem에서는 Netflix OSS 인 Eureka를 Service Discovery로 제공하고 있습니다. 11번가는 IDC 내에 Eureka 서버를 Peering하여 구축해두었고, 각 애플리케이션에 포함된 Eureka Client가 서버 Peer와의 통신을 통해서 개별 인스턴스 정보를 받아와 통신하는 과정을 거치게 됩니다.
아래 설명드리는 내용은 Spring Cloud Netflix 2021.0.X를 기준으로 합니다. 버전에 따라 일부 property 혹은 구현이 상이할 수 있으니 참고 부탁드립니다. 🙂
Client-side Service Discovery 동작 방식
Eureka는 Client-side Service Discovery 방식입니다. 서비스 클라이언트가 서비스 레지스트리로부터 다른 서비스의 위치를 찾아서 호출하는 방식입니다. 각 서비스 인스턴스는 실행될 때 할당받는 자신의 주소를 Service Registry에 Register하고, 통신하고자 하는 다른 서비스가 있을 때 해당 인스턴스 정보를 서비스 레지스트리에 Query하여 수신받습니다.
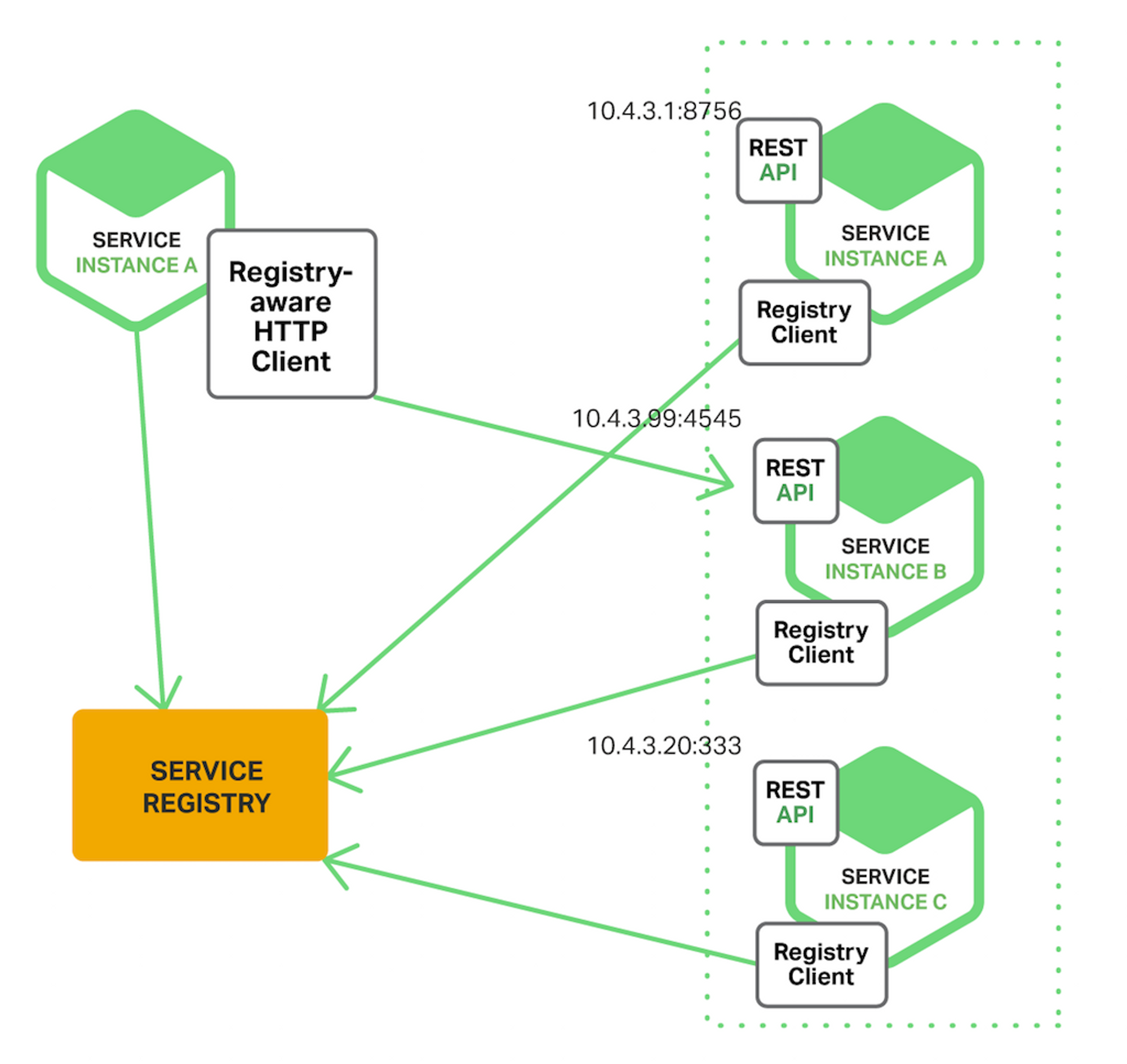
서버 / 클라이언트 Property 구성
서버와 클라이언트는 아래 코드와 같이 초기 Property를 구성해야 합니다. 서버의 경우 클라이언트와 다르게 Register나 registry를 fetch할 필요가 없으므로 해당 설정을 OFF하고, 클라이언트는 연결할 서버의 주소를 명시해야 합니다.
# 최소 구성
## Eureka Server Configuration
eureka:
client:
register-with-eureka: false # No needs to register itself
fetch-registry: false # No needs to fetch registry
## Eureka Client Configuration
eureka:
client:
service-url:
# Eureka Server URLs below:
defaultZone: http://11streetEureka:8761/eureka/
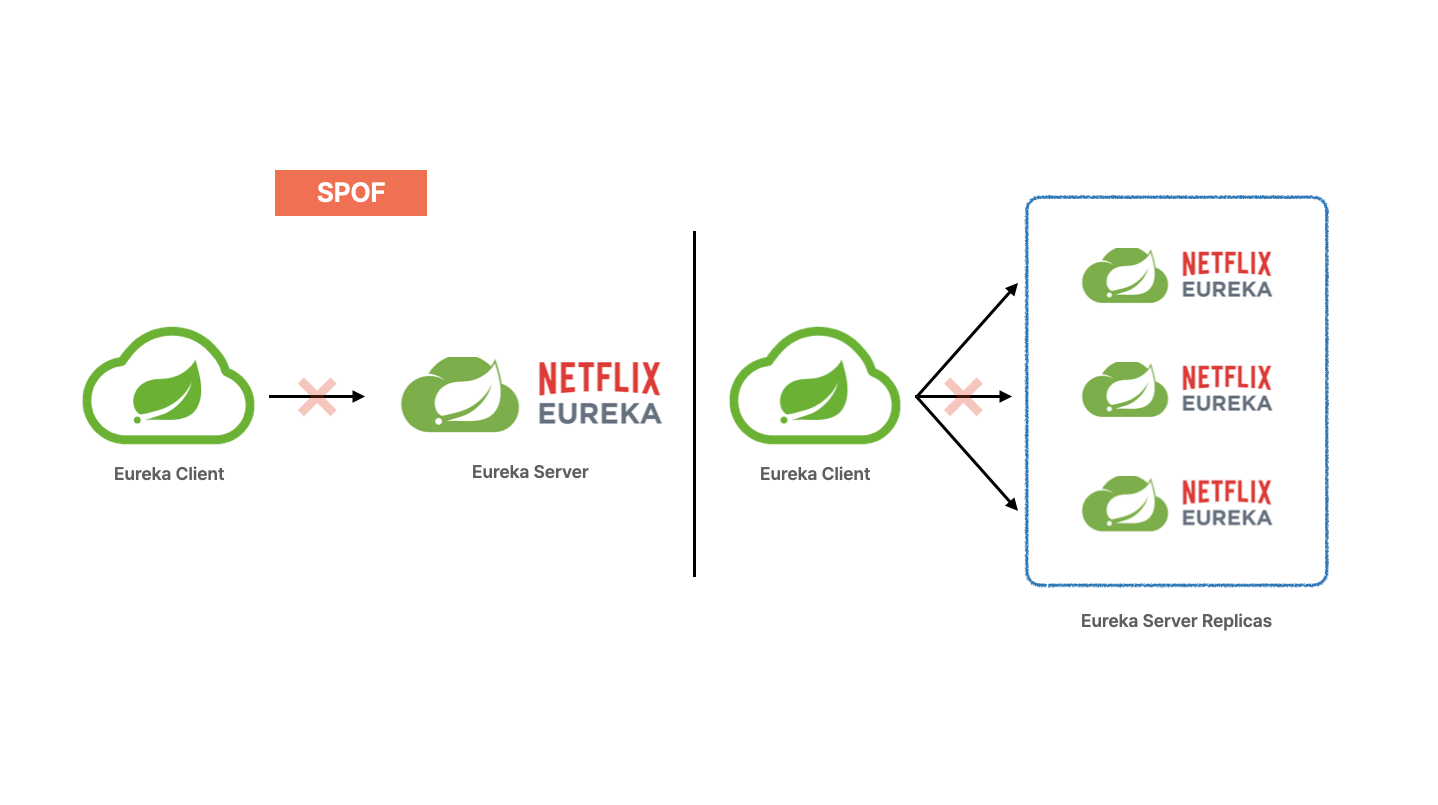
SPOF (Single Point Of Failure)
위의 이미지에서 확인할 수 있는 Eureka Server는 이중화가 되어 있지 않은 단일 장애점입니다. 단일 장애점이란 시스템에서 하나의 구성요소가 동작하지 않으면 시스템 전체가 중단되는 요소를 의미합니다. 각 서비스 클라이언트는 다른 서비스 클라이언트와 통신하기 위해서 인스턴스 주소 정보를 알고 있어야하고, 이 정보를 Service Registry에서 가져올 수 있습니다. Eureka Server가 단일 구성으로 이루어져 있을 때 해당 서버가 특정 원인으로 인해서 중단된다면, 서비스 클라이언트 간에 정상적인 통신을 할 수 없는 상황에 이르게 될 수 있습니다.
안정성 확대를 위한 방법 1 - 서버 복제 구성 (Replication)
SPOF를 제거하기 위해서 두 대 이상으로 서버를 복제 구성하여 하나의 서버가 중단되더라도 다른 서버 인스턴스로 대신 접근해 마이크로서비스 인스턴스 정보를 가져올 수 있어야 합니다. Eureka는 Replication을 Support하고 있어서 해당 설정을 활성화하여 SPOF 요소를 제거할 수 있습니다.
eureka.instance.registry.default-open-for-traffic-count: 0 으로 지정하면 서버 Replication을 활성화할 수 있습니다. eureka.client.service-url.defaultZone에 서버 인스턴스 목록을 명시하면 서버 인스턴스가 실행될 때 defaultZone 내에 명시된 모든 서버 인스턴스에 클라이언트 정보 복제가 진행됩니다.
eureka:
instance:
registry:
# Value used in determining when leases are cancelled,
# default to 1 for standalone.
# Should be set to 0 for peer replicated eurekas
default-open-for-traffic-count: 0
client:
service-url:
defaultZone: http://11streetEureka01:8761/eureka/,http://11streetEureka02:8761/eureka/
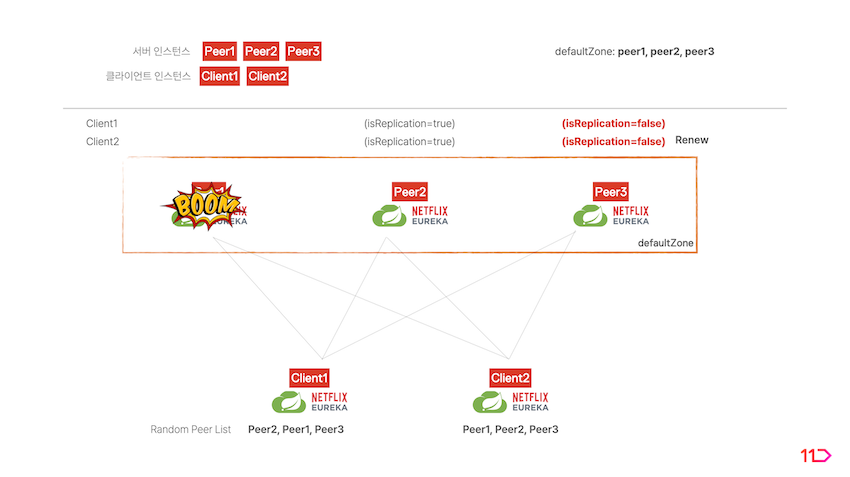
서버 복제 환경이 구성되면 서버와 클라이언트 간에 다음과 같이 동작하게 됩니다.
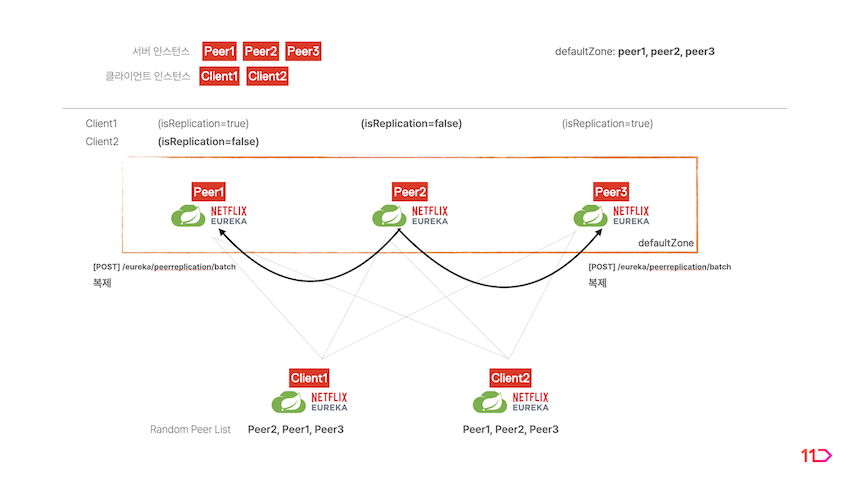
- 클라이언트에서 Property에 명시된 서버 리스트를 랜덤하게 정렬합니다.
- index 0의 서버를 선택하고 자기 자신을 register합니다.
- 클라이언트의 선택을 받은 서버는 해당 클라이언트의
isReplication=false플래그를 가지게 됩니다. 클라이언트는 해당 서버와 정보를 주고 받습니다.
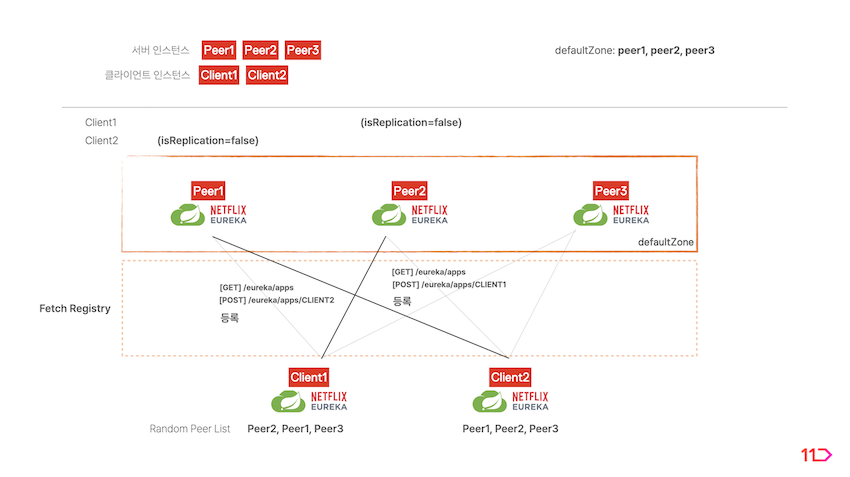
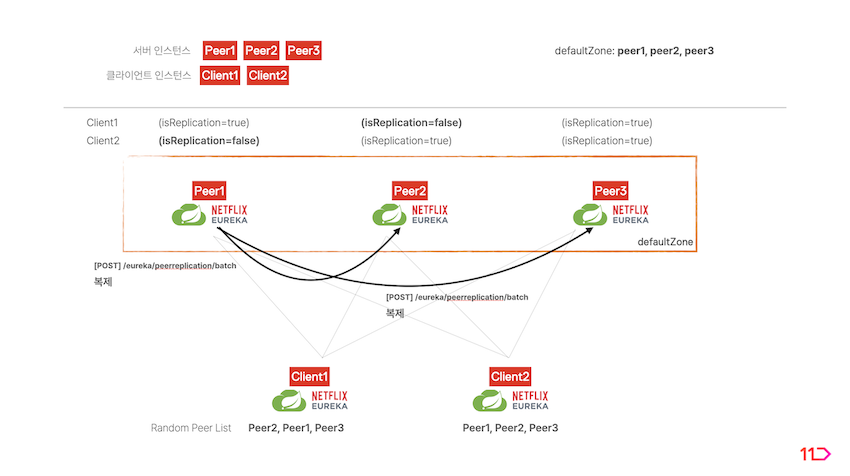
- 해당 서버가 나머지 서버 피어에 클라이언트의 정보를 복제합니다. 복제받는 서버 피어들은
isReplication=true플래그를 가지게 됩니다.
-
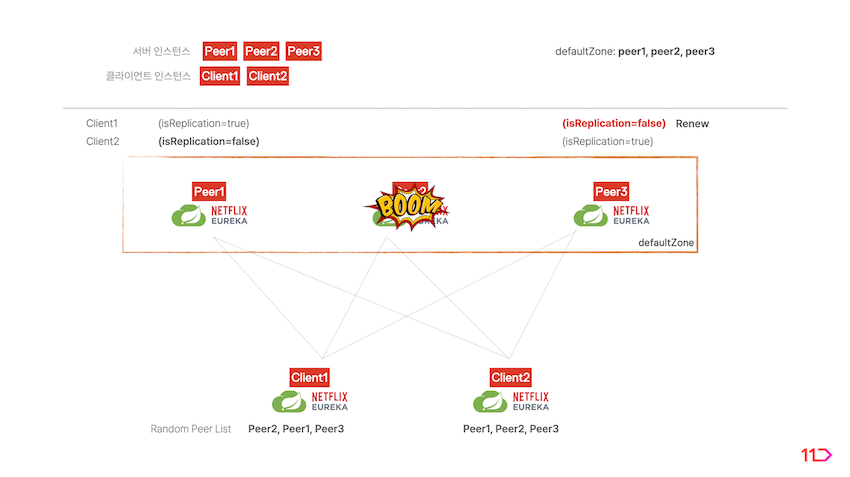
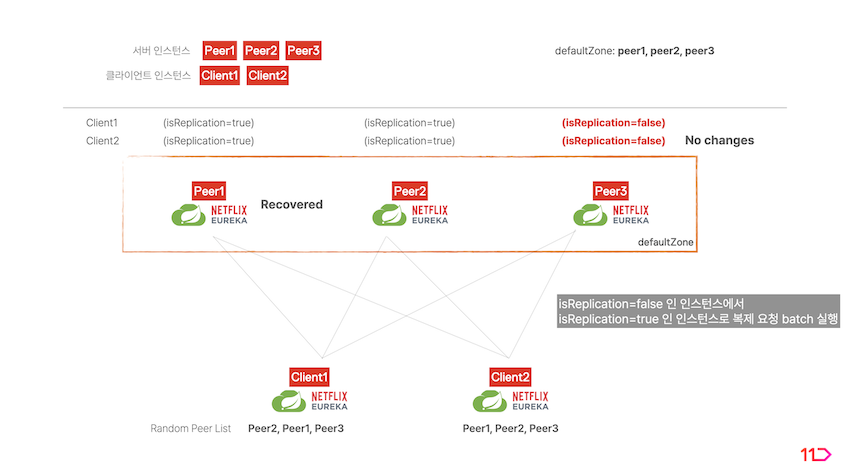
isReplication=false플래그를 가지는 서버가 만약 중단된다면 클라이언트는 해당 서버와 통신이 불가하게 됩니다. 이 때isReplication=true플래그를 가지는 서버 중 하나가isReplication=false플래그로 변경되면서 중단된 서버의 역할을 대체합니다. -
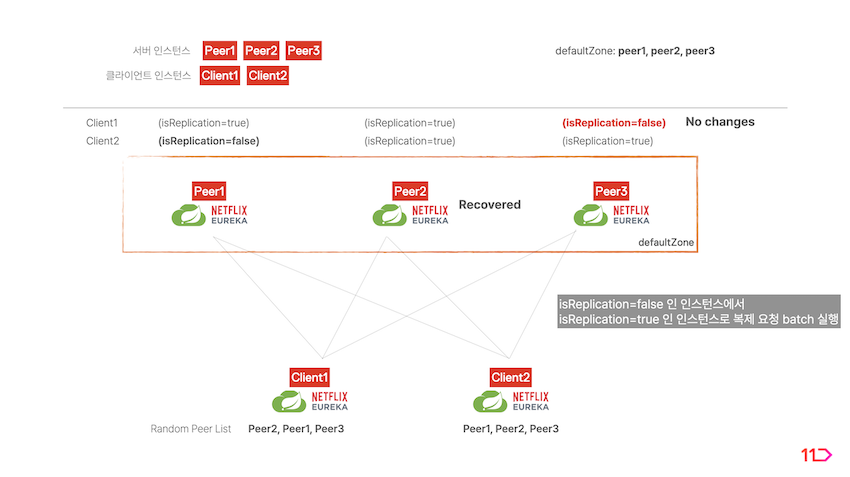
중단된 서버가 복구되더라도 역할을 건네받은 서버가 계속 역할을 수행합니다.
안정성 확대를 위한 방법 2 - Zone Failover 구현
위의 방법처럼 Replication 구성을 활성화하면 하나의 서버 인스턴스가 DOWN되더라도 다른 서버 인스턴스가 역할을 대체할 수 있습니다. 만약에 데이터센터 내 모든 서버 인스턴스가 DOWN되는 상황이 발생한다면 어떨까요? 이 경우 최소 하나 이상의 서버 인스턴스가 복구되기 전까지 서비스 클라이언트는 서비스 레지스트리를 정상적으로 사용할 수 없게 됩니다.
따라서 물리적으로 분리된 영역에도 추가적으로 서버를 구성해서 한쪽 데이터센터가 불능에 빠졌을 때 다른 데이터센터로 서비스를 전환하여 서비스가 중단되는 상황을 막아야 할 필요가 있습니다.
11번가는 운영 중인 Vine 플랫폼의 유연함과 확장성 증대를 위해 AWS를 도입하여 IDC와 Cloud 리소스를 함께 사용하는 Hybrid Cloud 형태로의 고도화를 진행하고 있는데요. 따라서 현재 사용되고 있는 EKS에 추가적인 Eureka Server를 생성할 신규 Zone을 구성하는 작업을 진행했습니다. 이러한 결과로서 하나의 Zone이 중단되더라도 다른 Zone으로 서비스 클라이언트가 바라보는 서버 참조를 이동해 무중단 Service Registry를 구현할 수 있었습니다.
Region / AZ(Availability Zone)
11번가의 EKS는 Seoul Region ap-northeast-2를 사용하고 있고, IDC 또한 서울에 위치해 있어 동일 Region으로 취급하고 각각을 별개의 Zone으로 설정하였습니다. Property는 아래와 같이 구성됩니다.
eureka:
client:
region: [REGION_NAME] # default: us-east-1 (if not be explicitly defined)
service-url:
idc: [SERVERS]
eks: [SERVERS]
availability-zones:
[REGION_NAME]: idc,eks # Comma Separated (no spaces)
일반적으로 단일 Zone 구성에서는 해당 Zone을 defaultZone으로 지정하여 서버 인스턴스 주소를 명시하는데, Zone이 여러 개로 증가한 구성에서는 개별 Zone에 Custom한 명칭을 부여하고 각 Zone에 소속되는 서버 인스턴스 주소 목록을 명시합니다.
eureka.client.availability-zones는 Client가 Region 내에서 사용할 수 있는 모든 Zone의 이름을 Comma로 구분된 리스트 형태로 입력받습니다. 해당 property는 특정 Zone이 중단되었을 때 다른 Zone으로의 Failover를 위해서 필요한 값입니다. Client가 우선적으로 참조해야하는 Zone이 가장 앞에 위치해야 합니다.
내부 동작 분석
아래 Client의 내부 동작은 서버 Replication과 Multi-AZ 구성을 한 경우를 기준으로 설명합니다.
DiscoveryClient
DiscoveryClient 는 Spring Cloud에서 Service Registry와 관련된 부분을 추상화한 인터페이스입니다. 이를 구현한 다양한 구현체가 존재하며, Eureka 또한 해당 인터페이스를 구현하고 있습니다.
Eureka Client가 DiscoveryClient 클래스를 통해서 Eureka Server와 상호작용을 하는데, 크게는 다음과 같은 Task가 있습니다.
- 서비스 클라이언트가 처음 실행될 때 Eureka Server에 자기 자신을 등록
register - 서비스 클라이언트가 살아있음을 주기적으로 서버에 알림
renew (혹은 Heartbeat) - 서비스 레지스트리로부터 받아온 애플리케이션 정보를 서비스 클라이언트에 주기적으로 캐시
fetchRegistry (혹은 cacheRefresh) - 서비스 클라이언트 프로세스가 종료될 때 Eureka Server에 등록되어 있던 자기 자신의 정보를 제거
unregister
이 중 Heartbeat Task와 CacheRefresh Task는 특정 간격으로 반복 실행되기 때문에 ThreadPool, ThreadPoolExecutor 를 생성해 별도의 스레드에서 실행하게 됩니다.

DiscoveryClient 생성자에서 Eureka Server와 상호작용하기 위한 객체인 EurekaHttpClient를 구성하고 (scheduleServerEndpointTask 메서드), 예정된 스케줄 (heartbeat와 cacheRefresh Task)를 실행합니다 (initScheduledTasks 메서드).
Spring Cloud Netflix에서는 RestTemplate (내부 통신에 Apache HttpClient 사용)을 TransportClient의 Default로 사용합니다.
// DiscoveryClient constructor
transport = new EurekaTransport();
scheduleServerEndpointTask(transport, args);
...
initScheduledTasks();
// DiscoveryClientOptionalArgsConfiguration
@Bean
@ConditionalOnClass(name = "org.springframework.web.client.RestTemplate")
@ConditionalOnMissingClass("com.sun.jersey.api.client.filter.ClientFilter")
@ConditionalOnMissingBean(value = { AbstractDiscoveryClientOptionalArgs.class }, search = SearchStrategy.CURRENT)
@ConditionalOnProperty(prefix = "eureka.client", name = "webclient.enabled", matchIfMissing = true,
havingValue = "false")
public RestTemplateDiscoveryClientOptionalArgs restTemplateDiscoveryClientOptionalArgs(TlsProperties tlsProperties,
EurekaClientHttpRequestFactorySupplier eurekaClientHttpRequestFactorySupplier)
throws GeneralSecurityException, IOException {
logger.info("Eureka HTTP Client uses RestTemplate.");
RestTemplateDiscoveryClientOptionalArgs result = new RestTemplateDiscoveryClientOptionalArgs(
eurekaClientHttpRequestFactorySupplier);
setupTLS(result, tlsProperties);
return result;
}
DiscoveryClient#scheduleServerEndpointTask 메서드 내부를 살펴보면, Eureka Server와 관련된 정보를 Resolver 객체에 담아 구성하고 이 Resolver 객체를 매개변수로 하여 Server와 상호작용하기 위한 EurekaHttpClient 객체를 생성합니다.
우선, Resolver 객체가 서버 정보를 어떻게 구성하는지 다음과 같은 다이어그램과 함께 설명드리겠습니다.
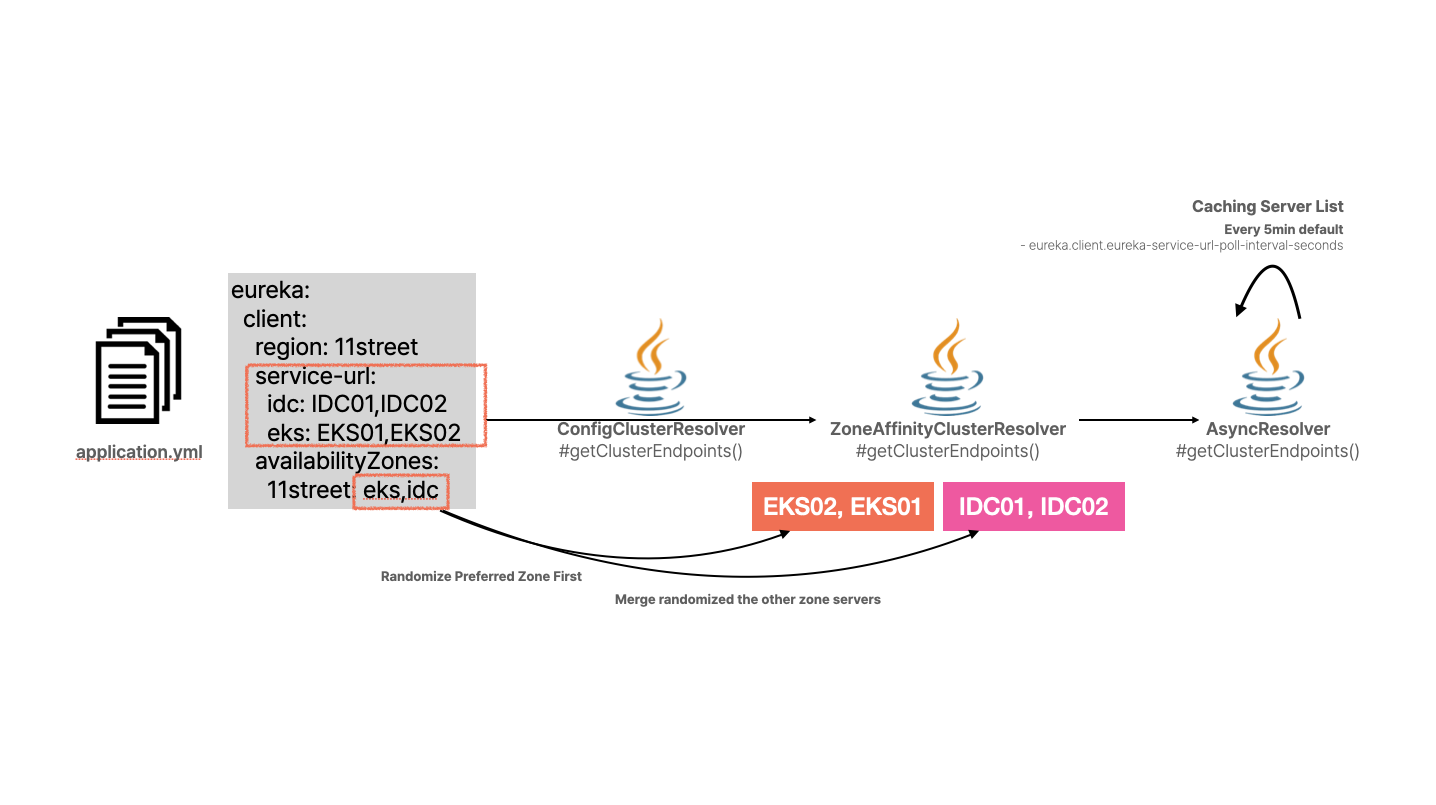
ConfigClusterResolver가 application.yml에서 서버 구성 정보를 읽어옵니다. 이 정보를 ZoneAffinityClusterResolver에서 단일 리스트 객체로 변환합니다. 이 때 서비스 클라이언트가 우선 참조하게 되는 Zone(eureka.client.availability-zones[0])의 서버 리스트가 가장 앞에 오게 되고, 나머지 Zone의 서버 리스트가 이어집니다. AsyncResolver에서 해당 리스트를 5분 단위로 새롭게 캐시하여 반환합니다.
이렇게 구성된 CompositeResolver는 EurekaHttpClient 객체를 생성하는 팩터리 메서드의 매개변수로 전달되며, 이 때 EurekaHttpClient의 구현체 클래스로 다음 클래스가 사용됩니다.
SessionedEurekaHttpClient- 주기적으로 새로운 세션을 생성해 서비스 클라이언트가 특정 서버로 연결이 sticking되는 것을 방지하는 로직이 포함되어 있습니다.
- 하나의 세션이 유지되는 시간은 20 ± [0, 20 / 2] 분입니다.
- 관련 Property :
eureka.client.transport.sessioned-client-reconnect-interval-seconds
RetryableEurekaHttpClient- 서버와의 연결 실패에 따른 Retry 로직이 포함되어 있습니다.
- 관련 Property :
eureka.client.transport.retryable-client-quarantine-refresh-percentage
RedirectingEurekaHttpClientMetricsCollectingEurekaHttpClient
여기서는 RetryableEurekaHttpClient가 가장 중요한 구현체 클래스입니다. 서버로의 연결이 실패했을 때 Retry를 하는 관련 로직이 포함되어 있습니다.
// RetryableEurekaHttpClient#execute(RequestExecutor<R> requestExecutor)
@Override
protected <R> EurekaHttpResponse<R> execute(RequestExecutor<R> requestExecutor) {
List<EurekaEndpoint> candidateHosts = null;
int endpointIdx = 0;
for (int retry = 0; retry < numberOfRetries; retry++) {
EurekaHttpClient currentHttpClient = delegate.get();
EurekaEndpoint currentEndpoint = null;
if (currentHttpClient == null) {
if (candidateHosts == null) {
candidateHosts = getHostCandidates();
if (candidateHosts.isEmpty()) {
throw new TransportException("There is no known eureka server; cluster server list is empty");
}
}
if (endpointIdx >= candidateHosts.size()) {
throw new TransportException("Cannot execute request on any known server");
}
currentEndpoint = candidateHosts.get(endpointIdx++);
currentHttpClient = clientFactory.newClient(currentEndpoint);
}
try {
EurekaHttpResponse<R> response = requestExecutor.execute(currentHttpClient);
if (serverStatusEvaluator.accept(response.getStatusCode(), requestExecutor.getRequestType())) {
delegate.set(currentHttpClient);
if (retry > 0) {
logger.info("Request execution succeeded on retry #{}", retry);
}
return response;
}
logger.warn("Request execution failure with status code {}; retrying on another server if available", response.getStatusCode());
} catch (Exception e) {
logger.warn("Request execution failed with message: {}", e.getMessage()); // just log message as the underlying client should log the stacktrace
}
// Connection error or 5xx from the server that must be retried on another server
delegate.compareAndSet(currentHttpClient, null);
if (currentEndpoint != null) {
quarantineSet.add(currentEndpoint);
}
}
throw new TransportException("Retry limit reached; giving up on completing the request");
}
CompositeResolver 에서 전달받은 서버 목록을 순차적으로 꺼내 통신을 하는데, 해당 서버에 연결이 실패하면 quarantineSet 이라는 변수에 해당 서버를 담고 다른 서버에 연결을 시도합니다.
연결 시도 대상 목록은 getHostCandidates() 메서드 호출로 전달받는데, 이 때 전체 목록에서 quarantineSet에 포함된 목록을 제외해서 반환합니다. 단, 전체 서버의 2/3이 응답하지 않는 경우 남은 서버에 재시도하지 않고 quarantineSet을 clear합니다. (모든 서버를 처음부터 재시도)
eureka.client.transport.retryable-client-quarantine-refresh-percentageproperty 값을 변경해서threshold를 결정할 수 있습니다. (기본값0.66(2/3))
// RetryableEurekaHttpClient#getHostCandidates()
private List<EurekaEndpoint> getHostCandidates() {
List<EurekaEndpoint> candidateHosts = clusterResolver.getClusterEndpoints();
quarantineSet.retainAll(candidateHosts);
// If enough hosts are bad, we have no choice but start over again
int threshold = (int) (candidateHosts.size() * transportConfig.getRetryableClientQuarantineRefreshPercentage());
//Prevent threshold is too large
if (threshold > candidateHosts.size()) {
threshold = candidateHosts.size();
}
if (quarantineSet.isEmpty()) {
// no-op
} else if (quarantineSet.size() >= threshold) {
logger.debug("Clearing quarantined list of size {}", quarantineSet.size());
quarantineSet.clear();
} else {
List<EurekaEndpoint> remainingHosts = new ArrayList<>(candidateHosts.size());
for (EurekaEndpoint endpoint : candidateHosts) {
if (!quarantineSet.contains(endpoint)) {
remainingHosts.add(endpoint);
}
}
candidateHosts = remainingHosts;
}
return candidateHosts;
}
Zone Failover를 위한 Property 계산 및 지정
Multi-AZ 구성에서 위 eureka.client.transport.retryable-client-quarantine-refresh-percentage 값이 매우 중요합니다. 전체 서버에서 특정 비율만큼 실패했을 때 나머지 서버에 대해 연결 시도를 하지 않고 모든 서버에 처음부터 재시도를 진행하도록 quarantineSet을 clear하기 때문입니다. 이는 값이 잘못 지정되었을 때 경우에 따라 특정 Zone 내 모든 서버에 접근이 실패하면 다른 Zone으로 Failover가 되지 않는 결과를 낳을 수 있습니다. 그렇다면 값을 어떻게 설정해야할까요? 아래 Case Study를 통해서 사례별로 지정해야 하는 값에 대해서 설명드리겠습니다.
Case Study 1 - IDC 3대 / EKS 3대 총 6대 구성
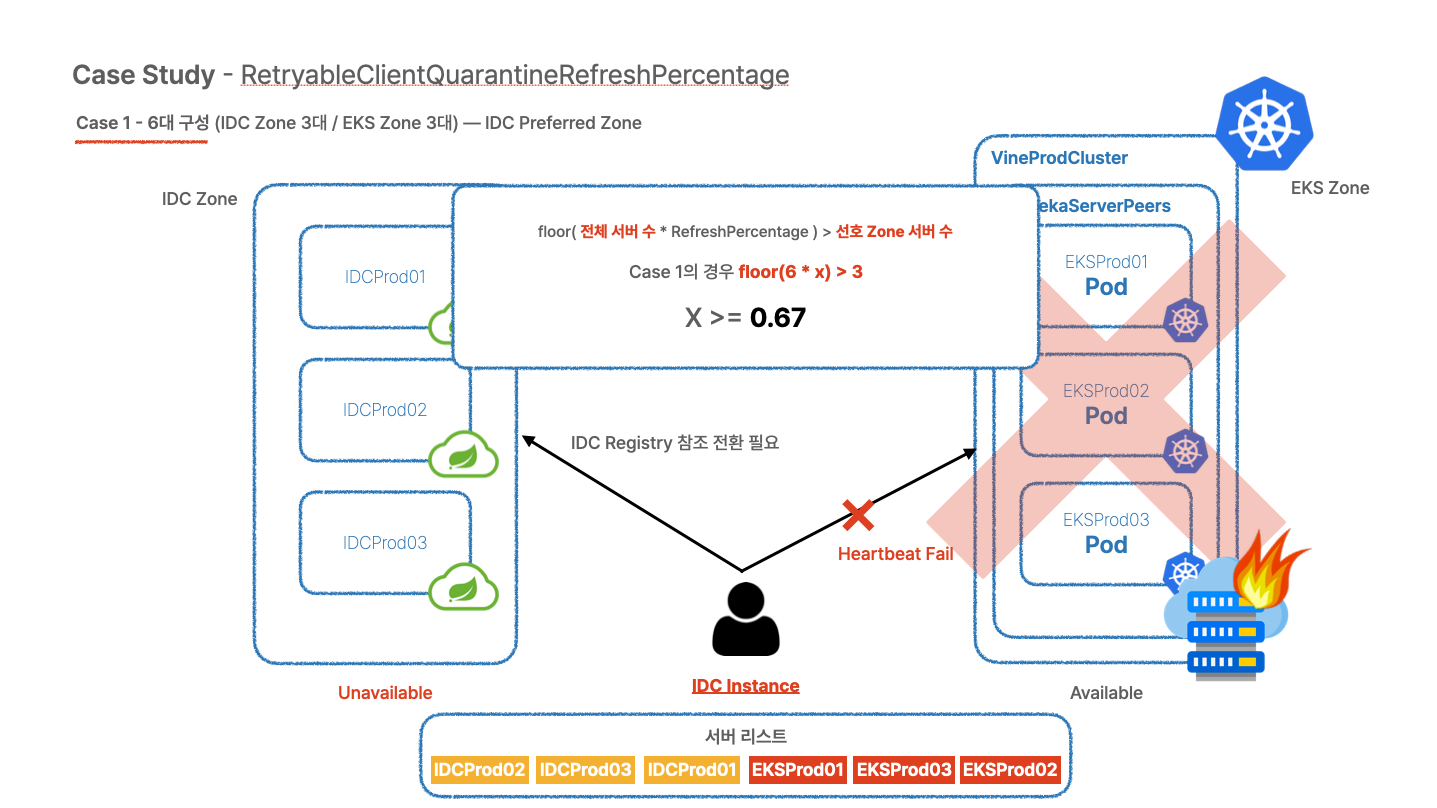
threshold 값의 소수점은 버림되기 때문에 floor((전체 서버 수) * (실패 비율)) > 선호 Zone 서버 수를 만족해야 합니다.
이번 Case에 적용할 경우 floor(6 * x) > 3 을 만족해야하므로 이 값을 만족하는 x의 최소값은 0.67이 됩니다. 따라서 eureka.client.transport.retryable-client-quarantine-refresh-percentage는 0.67 ~ 1 사이의 값이어야 합니다.
eureka:
client:
transport:
# IDC Client prefers IDC Zone
retryable-client-quarantine-refresh-percentage: 0.67
Case Study 2 - IDC 2대 / EKS 3대 총 5대 구성
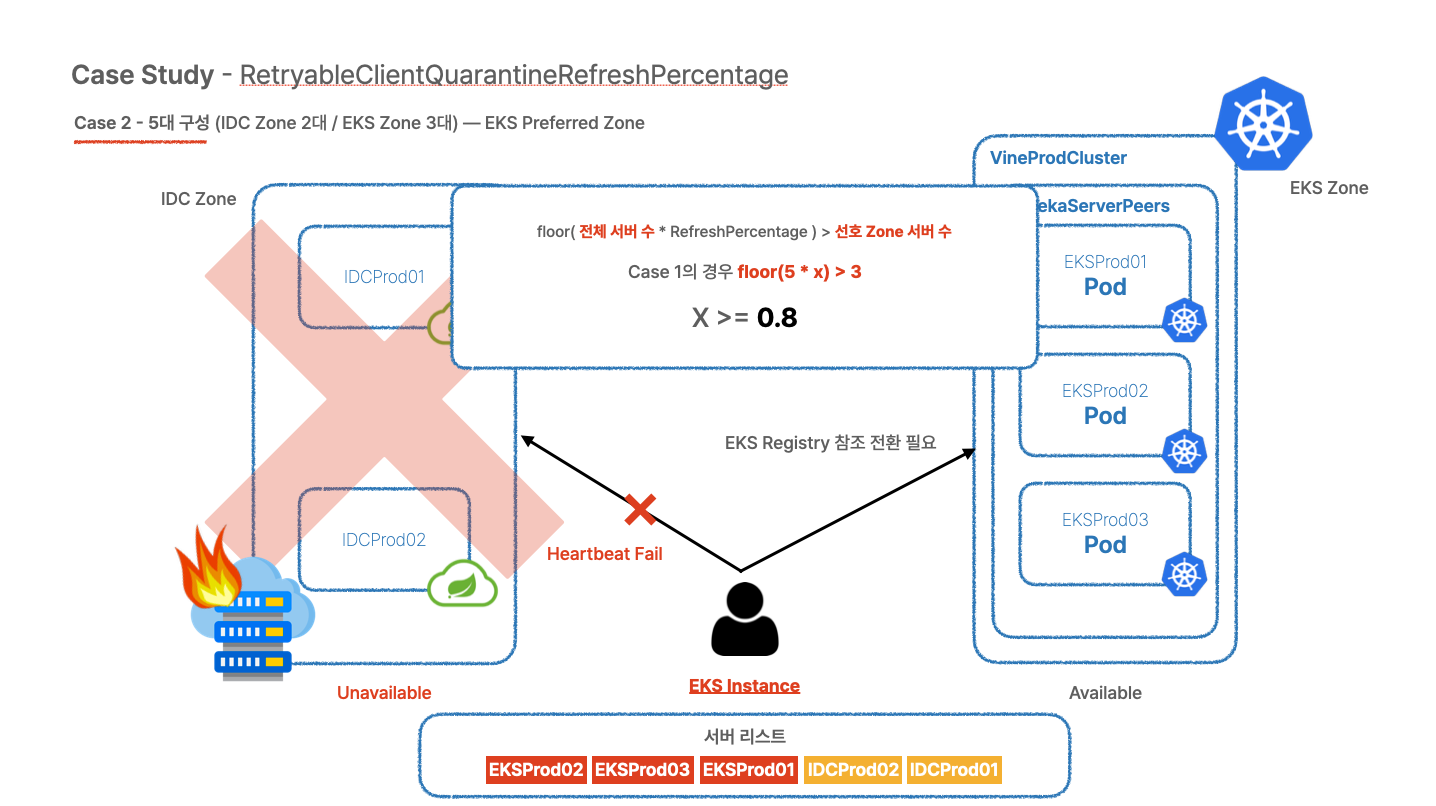
Case 1과 다르게 이번 Case는 IDC Zone의 서버 수가 한 대 적어 2대 구성을 하고 있습니다.
EKS Zone에 위치한 클라이언트가 EKS Zone이 Fail 되었을 때 IDC Zone으로 Failover가 되도록 하기 위해서는 다음 식을 만족해야합니다.
floor(5 * x) > 3
이 값을 만족하는 x 의 최소값은 0.8입니다. 따라서 eureka.client.transport.retryable-client-quarantine-refresh-percentage는 0.8 ~ 1 사이의 값이어야 합니다.
eureka:
client:
transport:
# EKS Client prefers EKS Zone
retryable-client-quarantine-refresh-percentage: 0.8
반대로 IDC가 우선 참조되는 IDC 클라이언트 인스턴스 입장에서는 다음 식을 만족해야합니다.
floor(5 * x) > 2따라서 이 값을 만족하는 x의 최소값은0.6입니다. 따라서eureka.client.transport.retryable-client-quarantine-refresh-percentage는 0.6 ~ 1 사이의 값이어야 합니다.
Conclusion
11번가는 견고하고 안정화된 시스템을 개발 / 운영하기 위한 다양한 방법을 시도하고 도입하고 있습니다. 이번 Article에서는 Service Discovery 컴포넌트 Eureka의 안정성 증대를 위해서 서버 복제 구성과 Multi-AZ 적용을 통한 Disaster Recovery를 구현한 방법에 대해 공유드렸습니다.
이렇게 구현한 Disaster Recovery는 실제 장애 상황에서 의도한대로 동작해야만 하는데요, 과연 실제 동작해야하는 순간에 잘 동작하게 될까요? 이를 증명하기 위한 Chaos Test와 관련하여 별도의 2부 아티클에서 내용을 다룰 예정입니다.
본 Article과 관련한 피드백을 언제나 환영합니다! 이상으로 Article을 마치도록 하겠습니다. 감사합니다 🙂