11번가 인턴의 카탈로그 리뷰 API 개선기
안녕하세요. 11번가 PDP개발팀 신치용입니다.
작년 11월 중순부터 5주가량 진행된 인턴 기간동안 과제를 진행하면서 느낀 경험을 담은 글입니다.
많이 부족하지만 짧은 인턴 기간 동안 진행한 과제라는 점을 고려해주시면서 읽어주시면 감사하겠습니다! 😄
목차
인턴 과제
저의 인턴 과제는 카탈로그 리뷰 API를 개선하는 것이었습니다.
아래 사진은 2022년 그랜드 십일절 당시 카탈로그 리뷰 API로 인해 DB에 부하가 생긴 모습입니다.
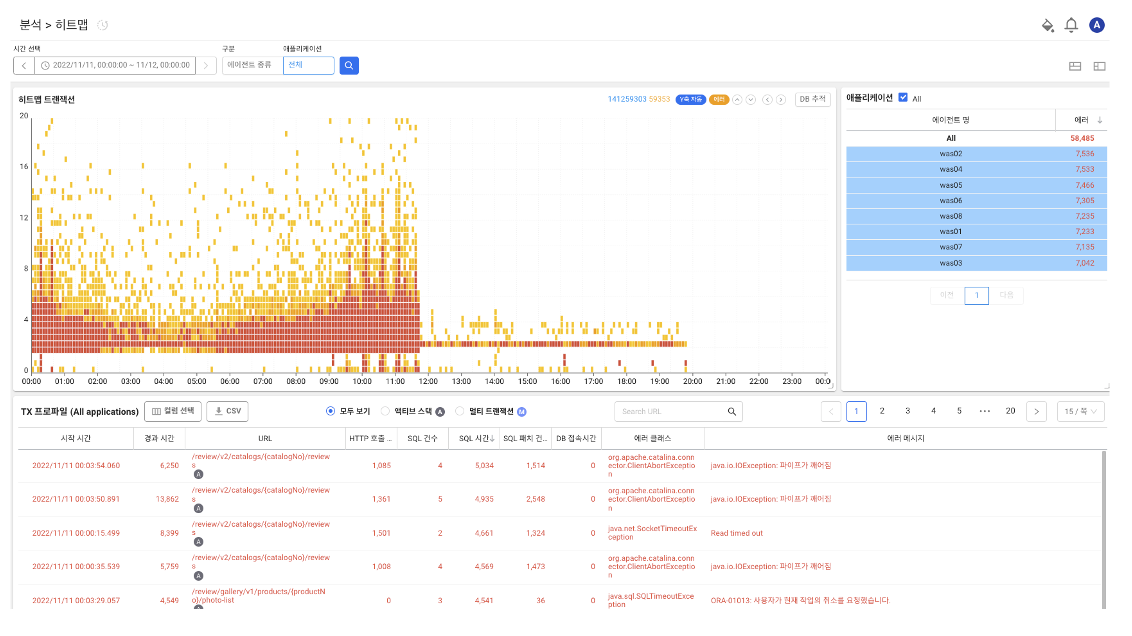
카탈로그 리뷰 API, 너 왜 문제 있어?
카탈로그 리뷰 API는 어떤 이유로 DB에 부하를 가하는 문제점을 가지고 있을까요?
API의 문제점을 분석하기 이전에 먼저 “카탈로그 리뷰” 에 대해 이해해야 한다고 생각했습니다.
먼저, 카탈로그란 11번가의 상품들이 고객에게 잘못 노출되는 경우를 없애기 위해 자체적으로 가격 비교를 할 수 있는 정제된 데이터를 말합니다.
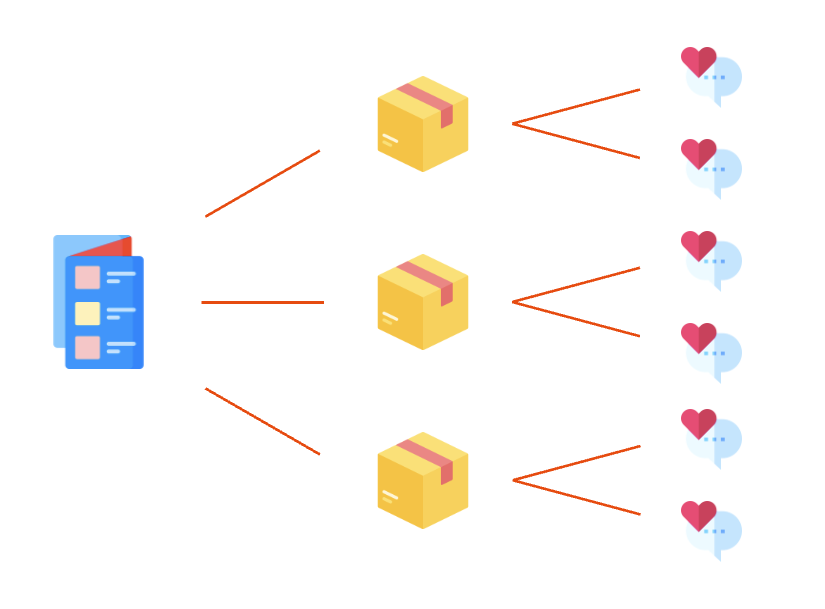 카탈로그는 상품과
카탈로그는 상품과 1대N 의 관계를 가집니다. 상품과 리뷰도 1대N 의 관계를 가집니다.
따라서, 카탈로그와 리뷰는 1대N^2 관계이기 때문에 제대로 성능이 나올 수 없는 구조입니다.
카탈로그와 리뷰는 각각의 도메인으로 존재하고 데이터양이 매우 많은 시스템이어서 구조적인 개선이 어렵습니다.

문제점을 개선하기 위해
- 첫 번째로 글로벌 캐시를 도입하고,
- 두 번째로 호출이 빈번한 카탈로그 캐시의 TTL 만료 전 능동적으로 캐시 최신화 작업을 수행하기로 결정했습니다.
글로벌 캐시 도입
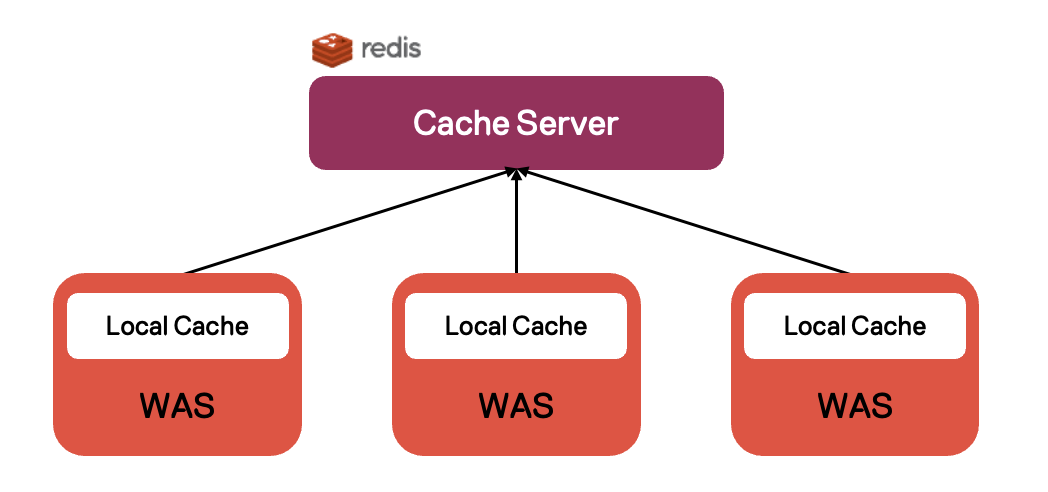
기존 구조 - Only 로컬 캐시
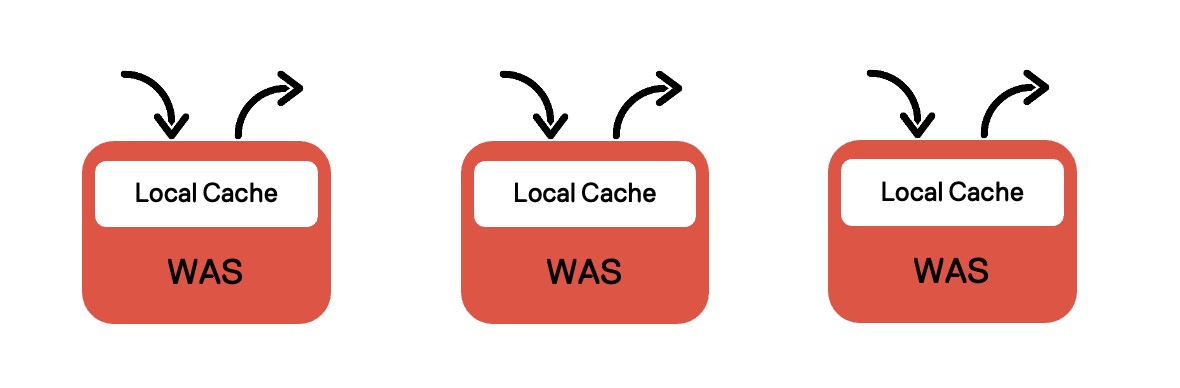
카탈로그 리뷰의 쿼리는 top-query이지만 1대N^2 구조로 인해 성능이 좋지 않습니다.
따라서, A 상품의 카탈로그 리뷰를 처음 호출 시 Read Timeout이 발생할 수 있습니다.
이를 해결하고자 기존 구조에서는 Caffeine 캐시를 사용하여 로컬 캐싱을 적용하고 있었습니다.
로컬 캐시는 속도가 빠르지만 캐시 동기화를 할 수 없다는 단점을 가지고 있어 서버마다 데이터의 차이가 존재할 수 있습니다.
만약, WAS 3대 중 A 상품에 대한 로컬 캐싱이 1대에만 적용되어 있는 상황이라면 다른 2개의 WAS로 A 상품에 대한 카탈로그 리뷰 호출 시 무거운 쿼리가 실행되는 것입니다.
성능이 좋지 않은 쿼리 실행은 쌓이고 쌓여 속도가 더 느려지며 이로인해 카탈로그 리뷰 페이지를 새로고침 시 카탈로그 리뷰가 간헐적으로 노출되지 않는 현상이 존재했습니다.
글로벌 캐시 로직 구현
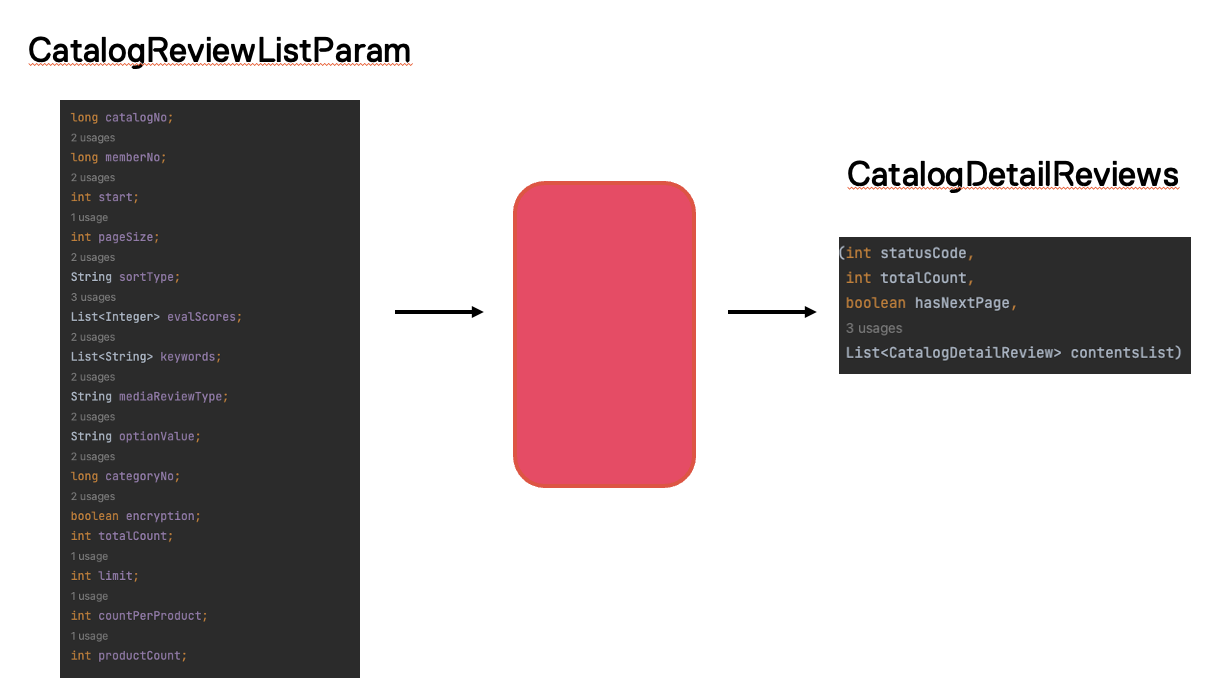
카탈로그 리뷰 API는 CatalogReviewListParam이라는 클래스를 argument로 사용하며 카탈로그 리뷰 데이터인 CatalogDetailReviews를 반환합니다.
CatalogReviewListParam에는 여러 필드들이 존재합니다.
각각의 필드들에 의해 카탈로그 리뷰 데이터 결과가 달라지고 카탈로그 리뷰 관련 서비스 코드들이 CatalogReviewListParam 자체를 인자로 많이 사용하고 있어 일부 필드들로 캐시 key로 구성했습니다.
public class CatalogGlobalCache {
private CatalogReviewListParam cacheKey;
private CatalogDetailReviews cacheValue;
...
}
이를 토대로 CatalogReviewListParam을 Cache의 Key로, CatalogDetailReviews를 Cache의 Value로 가지는 CatalogGlobalCache를 만들었습니다.
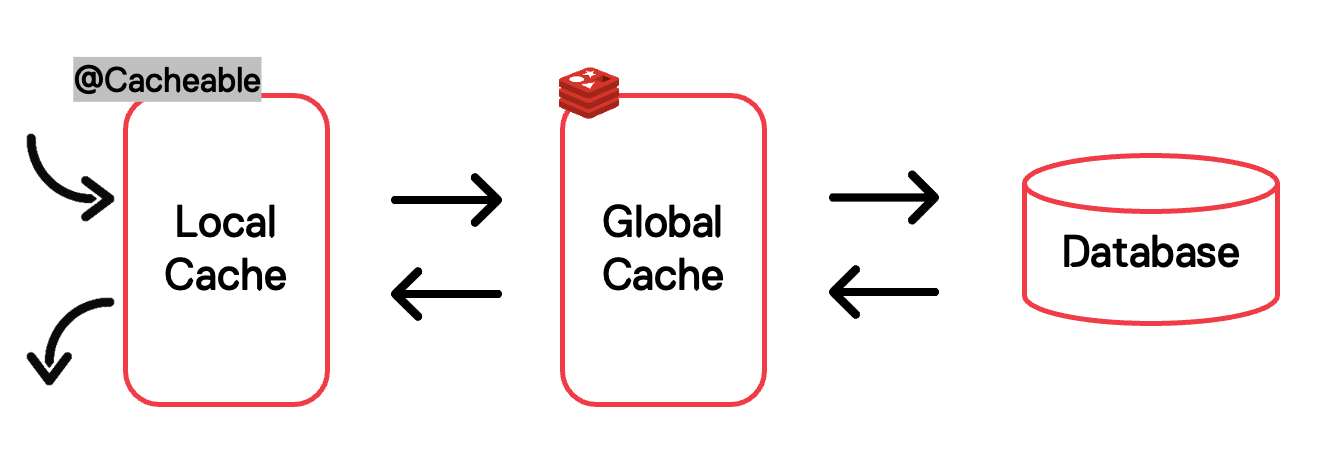
기존 로컬 캐시 제거하지 않고, 로컬 캐시와 글로벌 캐시, 2가지 캐시 레이어를 모두 사용했습니다.
2가지 캐시 레이어를 사용하기 때문에 캐시 히트율을 높일 수 있습니다.
글로벌 캐시를 추가한 후 흐름
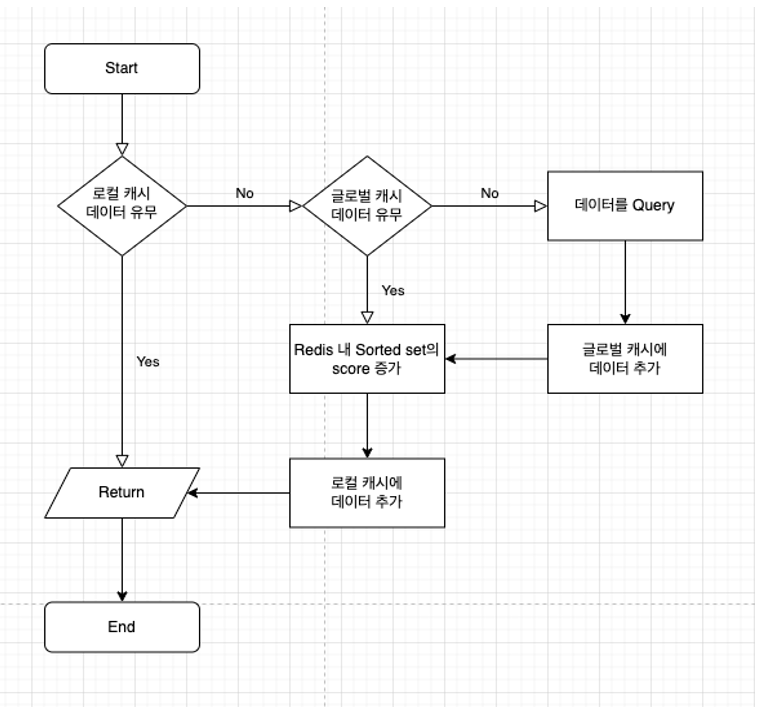
글로벌 캐시를 추가한 후 카탈로그 리뷰 API의 흐름은 다음과 같습니다.
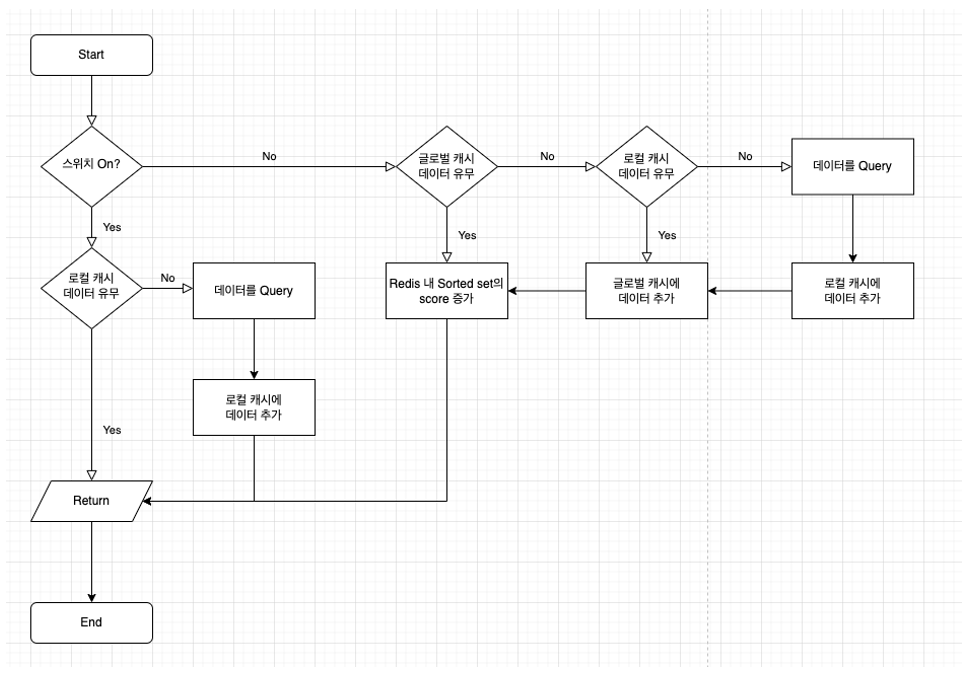
- 로컬 캐시에서 해당 요청에 맞는 데이터를 우선적으로 탐색합니다.
- 만약, 로컬 캐시에 원하는 데이터가 있다면 반환하고, 없다면 글로벌 캐시 로직으로 넘어갑니다.
- 글로벌 캐시에서 로컬 캐시로부터 넘어온 요청에 맞는 데이터를 탐색합니다.
- 만약, 글로벌 캐시에 원하는 데이터가 있다면 반환하고, 없다면 데이터 쿼리 로직을 수행합니다.
추가로, 글로벌 캐시가 도입된 순서도입니다.
캐시 자동 최신화
글로벌 캐시를 도입하더라도 첫 호출과 만료된 캐시에 대해서는 개선이 되지 않아 호출이 실패하게 됩니다.
호출이 빈번한 카탈로그 리뷰 데이터를 능동적으로 최신화하여 개선하기로 결정했습니다.
호출이 빈번한 카탈로그 리뷰 데이터를 능동적으로 최신화하기 위해서는 호출이 빈번한 카탈로그가 어떤 카탈로그인지 알아야 합니다.
이를 위해 Redis의 Sorted Set을 사용하기로 결정했습니다.
Redis의 Sorted Set은 Leaderboard와 같이 순위가 필요한 곳에 사용할 수 있는 자료구조입니다.
카탈로그 리뷰 데이터가 호출될 때마다 Score를 증가시켜 호출 횟수를 기록합니다.
하지만, 호출이 빈번한 카탈로그 정보를 추출하기 위해 Redis의 Sorted Set Score 데이터를 확인해보니 로직의 문제점을 발견했습니다.
Sorted Set Score가 로컬 캐시에 데이터가 없을 때에만 증가되는 것이었습니다.
대부분의 데이터가 로컬 캐시에서 히트되어 나가기 때문에 Redis의 Sorted Set Score를 증가시킬 수 없었고 글로벌 캐시로 사용하는 Redis까지 요청이 거의 도착하지 않았습니다.
이렇게 만들어진 Score 정보는 호출이 빈번한 카탈로그를 알아내기 위한 유의미한 정보가 아니라고 판단했습니다.
따라서, 로컬 캐시와 글로벌 캐시의 순서를 변경하였습니다.
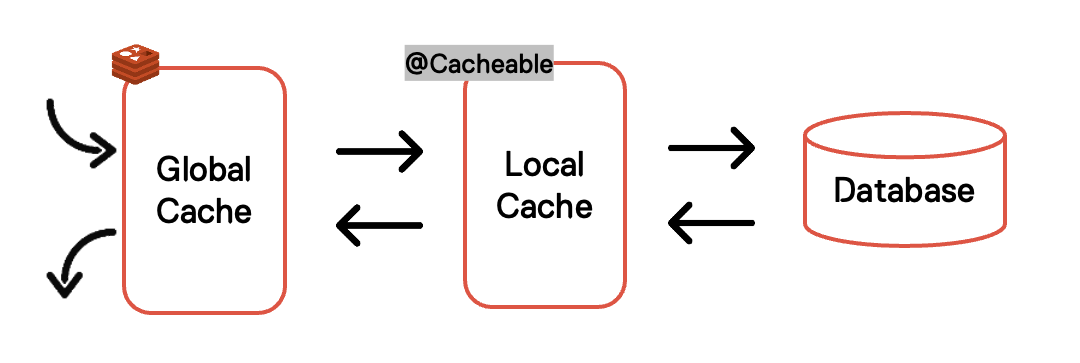

글로벌 캐시의 순서가 앞으로 조정되면서 혹시 모를 서비스 장애에 대비하여 컨트롤러단에 스위치를 배치했습니다.
스위치를 통해 상용 서비스 도중 문제 발생 시 기존 서비스로 빠르게 롤백할 수 있습니다.
다음은 로컬 캐시와 글로벌 캐시의 위치를 변경한 후의 순서도입니다.
글로벌 캐시의 단점
글로벌 캐시에도 네트워크 통신으로 인해 응답속도가 느리다는 단점이 존재합니다.
카탈로그 리뷰 API의 목적은 카탈로그 리뷰 데이터를 조회하여 반환하는 것입니다.
Redis에 데이터를 추가하거나 Sorted Set Score를 올리는 작업이 해당 API 내에서 동기적으로 작업되어야할 필요가 없다는 것이죠.
따라서, 해당 작업들을 비동기로 전환할 계획을 세웠습니다.
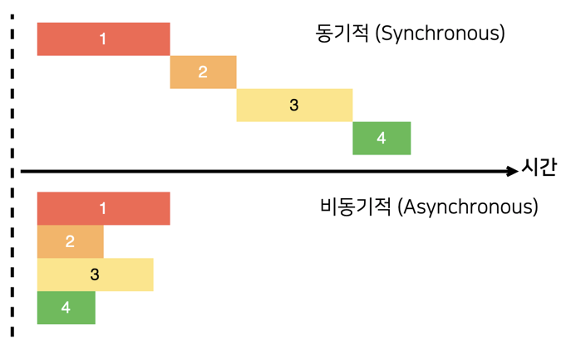
동기 or 비동기 무엇이 더 좋을까?
비동기로의 전환이 유의미한 개선이 될 수 있을 지 판단하기 위해 테스트를 진행했습니다.
- 기존 로컬 캐시를 타는 로직
- 글로벌 캐시는 먼저 타는 동기 로직
- 글로벌 캐시 로직을 먼저 타지만, 일부 작업이 비동기인 로직
위와 같이 3가지 경우로 나누어 테스트를 진행했습니다.
Test 1. 로컬 캐시에 데이터가 존재하지 않는 경우
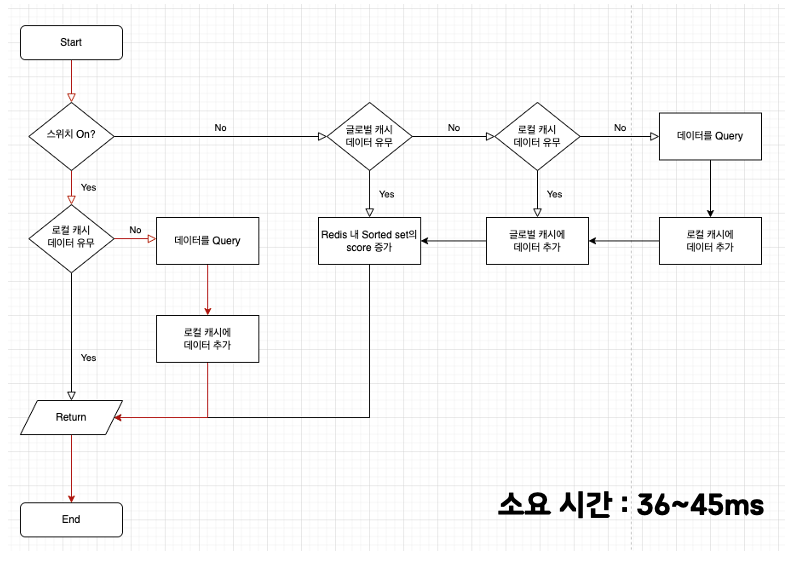
1번 테스트는 기존 로컬 캐시를 타는 로직이며, 로컬 캐시에 데이터가 존재하지 않는 경우입니다.
- 로컬 캐시에서 데이터를 탐색
- 로컬 캐시에 데이터가 존재하지 않아 데이터를 쿼리
- 쿼리한 데이터를 로컬 캐시에 추가
- 반환
순서로 이루어지고, 36~45ms가 소요되었습니다.
Test 2. 로컬 캐시에 데이터가 존재하는 경우
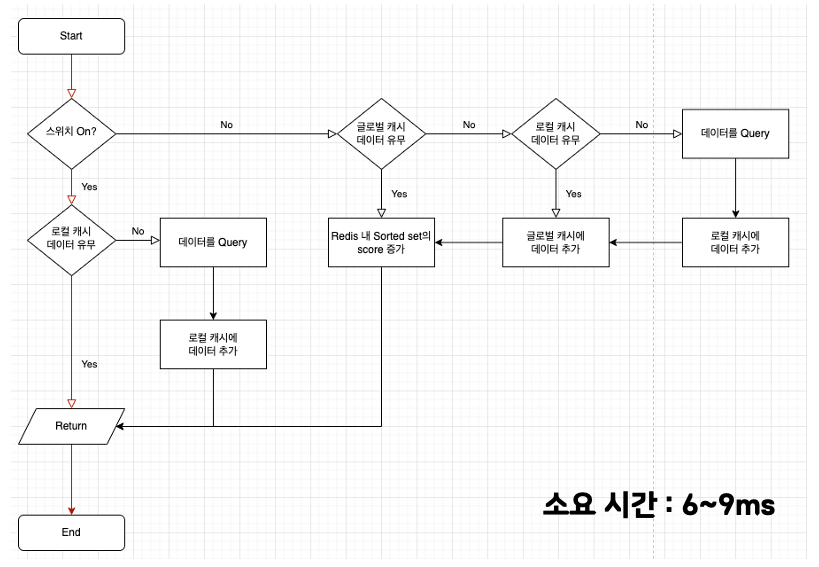
2번 테스트는 기존 로컬 캐시를 타는 로직이며, 로컬 캐시에 데이터가 존재하는 경우입니다.
- 로컬 캐시에서 데이터 탐색
- 반환
순서로 이루어지고, 6~9ms가 소요되었습니다.
Test 3. 로컬과 글로벌 캐시 모두 데이터가 존재하지 않는 경우
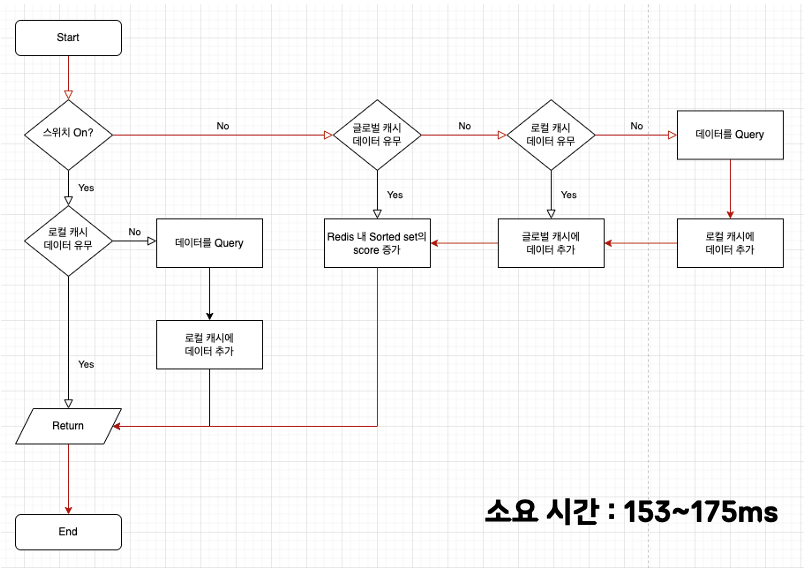
3번 테스트는 글로벌 캐시를 먼저 타는 동기 로직이며, 로컬 캐시와 글로벌 캐시 모두 데이터가 존재하지 않는 경우입니다.
- 글로벌 캐시에서 데이터를 탐색
- 글로벌 캐시에 데이터가 존재하지 않아 로컬 캐시에서 데이터를 탐색
- 로컬 캐시에 데이터가 존재하지 않아 데이터를 쿼리
- 쿼리해온 데이터를 로컬 캐시에 추가
- 쿼리해온 데이터를 글로벌 캐시에 추가
- Redis Sorted Set Score 증가
- 반환
순서로 이루어지고, 153~175ms가 소요되었습니다.
Test 4. 로컬과 글로벌 캐시 모두 데이터가 존재하는 경우
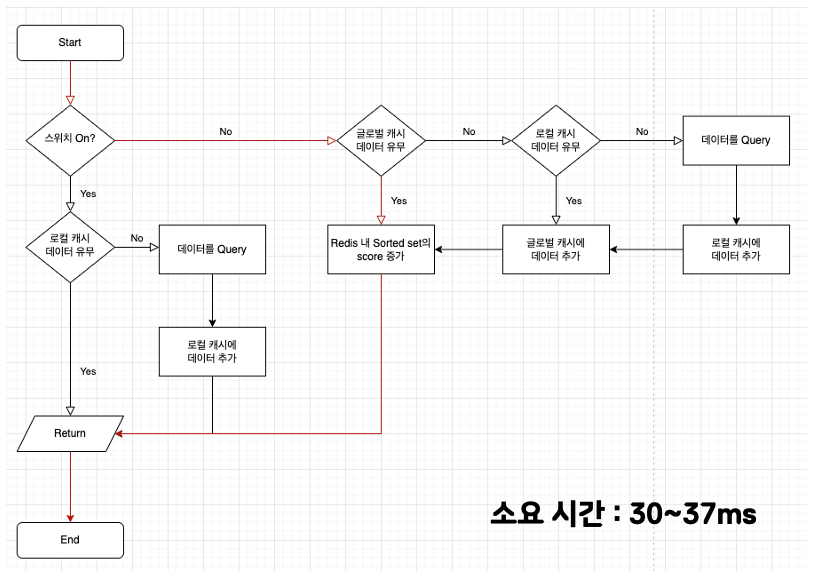
4번 테스트는 글로벌 캐시를 먼저 타는 동기 로직이며, 로컬과 글로벌 캐시에 모두 데이터가 존재하는 경우입니다.
- 글로벌 캐시에서 데이터를 탐색
- Redis Sorted Set Score 증가
- 반환
순서로 이루어지고, 30~37ms가 소요되었습니다.
Test 5. 로컬과 글로벌 캐시 모두 데이터가 존재하지 않는 경우
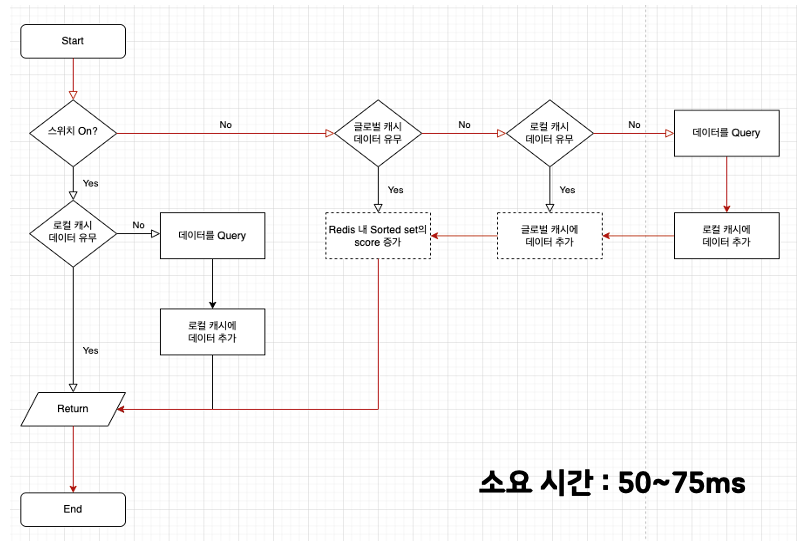
글로벌 캐시를 먼저 타지만, 일부 작업이 비동기인 로직입니다.
5번 테스트는 로컬과 글로벌 캐시 모두 데이터가 존재하지 않는 경우입니다.
3번 테스트와 조건은 동일하지만, 글로벌 캐시에 데이터를 추가하는 작업과 Sorted Set Score를 증가시키는 작업을 비동기로 처리합니다.
- 글로벌 캐시에서 데이터를 탐색
- 글로벌 캐시에 데이터가 존재하지 않아 로컬 캐시에서 데이터를 탐색
- 로컬 캐시에 데이터가 존재하지 않아 데이터를 쿼리
- 쿼리해온 데이터를 로컬 캐시에 추가
- 쿼리해온 데이터를 글로벌 캐시에 비동기로 추가
- Redis Sorted Set Score를 비동기로 증가
- 반환
순서로 이루어지며, 50~75ms가 소요되었습니다.
Test 6. 로컬과 글로벌 캐시 모두 데이터가 존재하는 경우
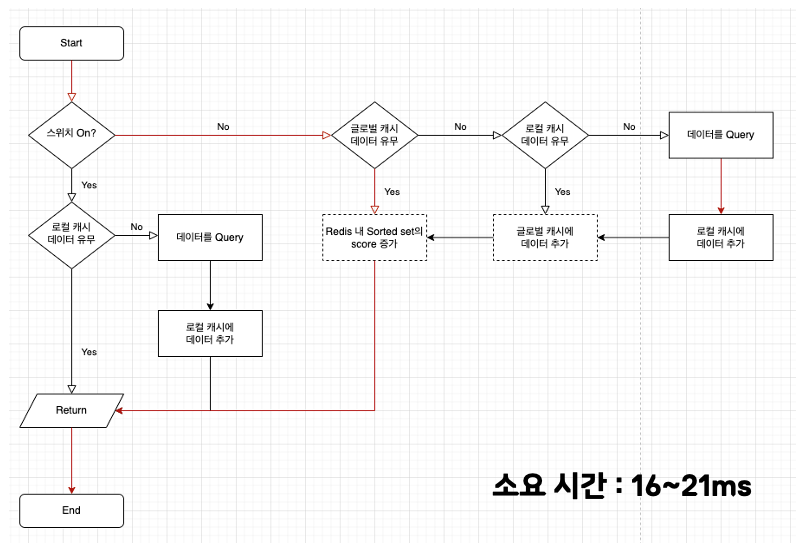
6번 테스트는 로컬과 글로벌 캐시 모두 데이터가 존재하는 경우입니다.
글로벌 캐시에서 데이터를 찾고 Redis Sorted Set Score 증가 작업을 비동기로 처리하고 데이터를 반환합니다.
- 글로벌 캐시에서 데이터를 탐색
- Redis Sorted Set Score를 비동기로 증가
- 반환
순서로 이루어지며, 16~21ms가 소요되었습니다.
테스트 결과
테스트 케이스 정리 및 결과입니다.
기존 로컬 캐시를 타는 구조
- T1 : 로컬 캐시에 데이터가 없는 경우
- T2 : 로컬 캐시에 데이터가 있는 경우
글로벌 캐시 데이터 X -> 로컬 캐시 데이터 X -> 데이터 쿼리
- T3 : 로컬 & 글로벌 캐시 모두 데이터가 없는 경우
- T4 : 로컬 & 글로벌 캐시 모두 데이터가 있는 경우
데이터 반환과 관계없는 작업들은 모두 비동기 전환
- T5 : 로컬 & 글로벌 캐시 모두 데이터가 없는 경우
- T6 : 로컬 & 글로벌 캐시 모두 데이터가 없는 경우
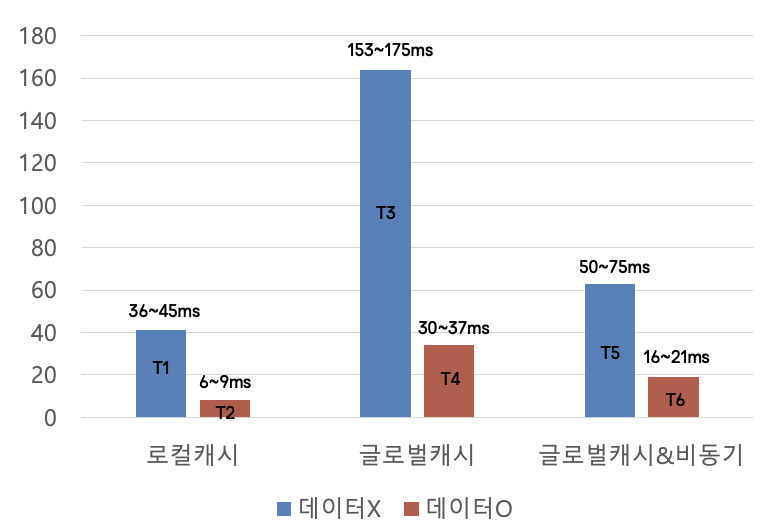
로컬과 글로벌 캐시 모두 데이터가 없는 경우에는 동기에서 비동기로 일부 작업을 전환하면서 응답시간이 61% 감소했습니다.
모두 데이터가 있는 경우에는 응답시간이 44% 감소한 것을 알 수 있었습니다.
일부 작업을 비동기로 전환하여 글로벌 캐시의 단점인 느린 응답속도를 개선했습니다.
글로벌 캐시 도입으로 카탈로그 리뷰 API 개선 결과
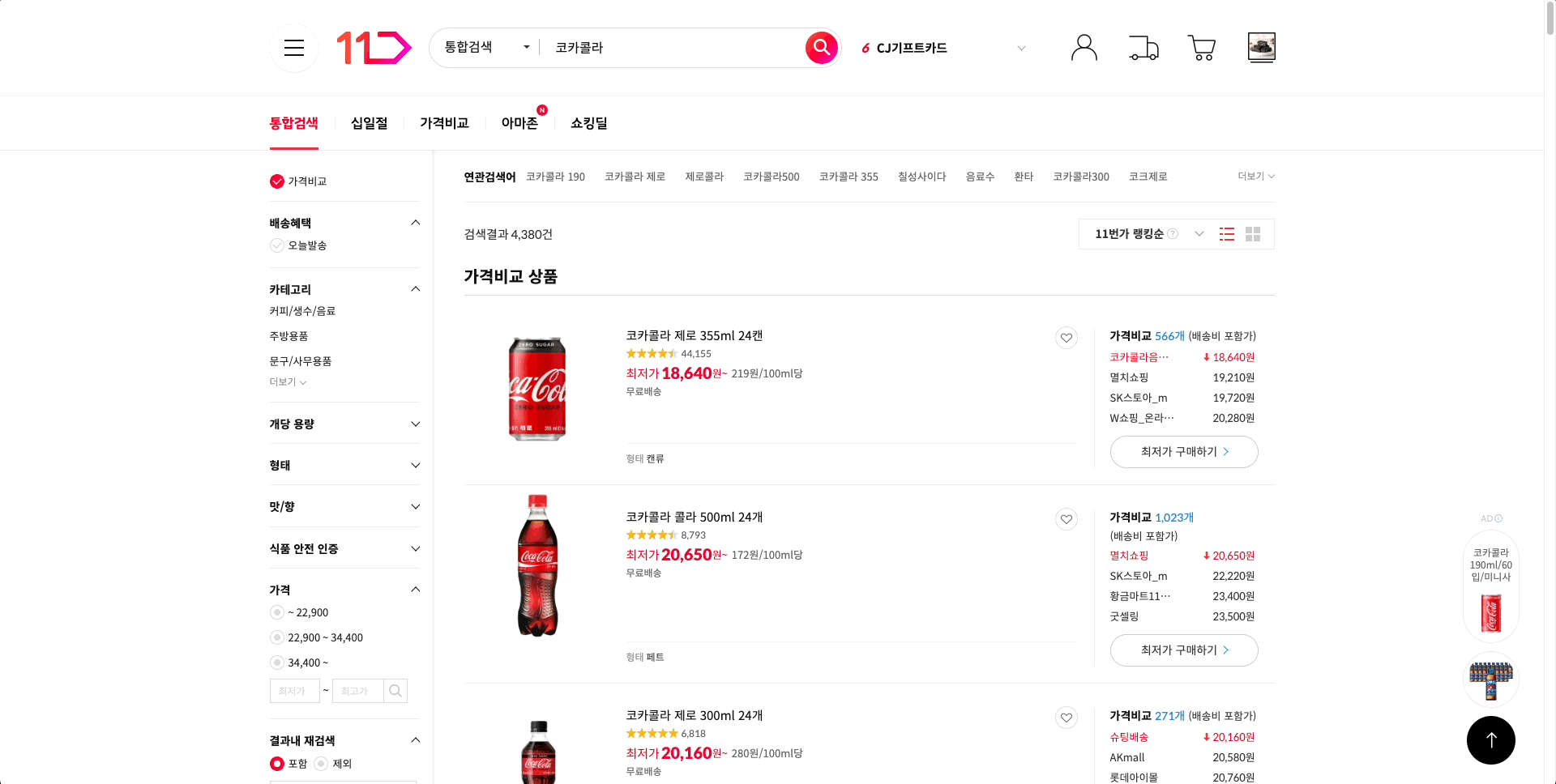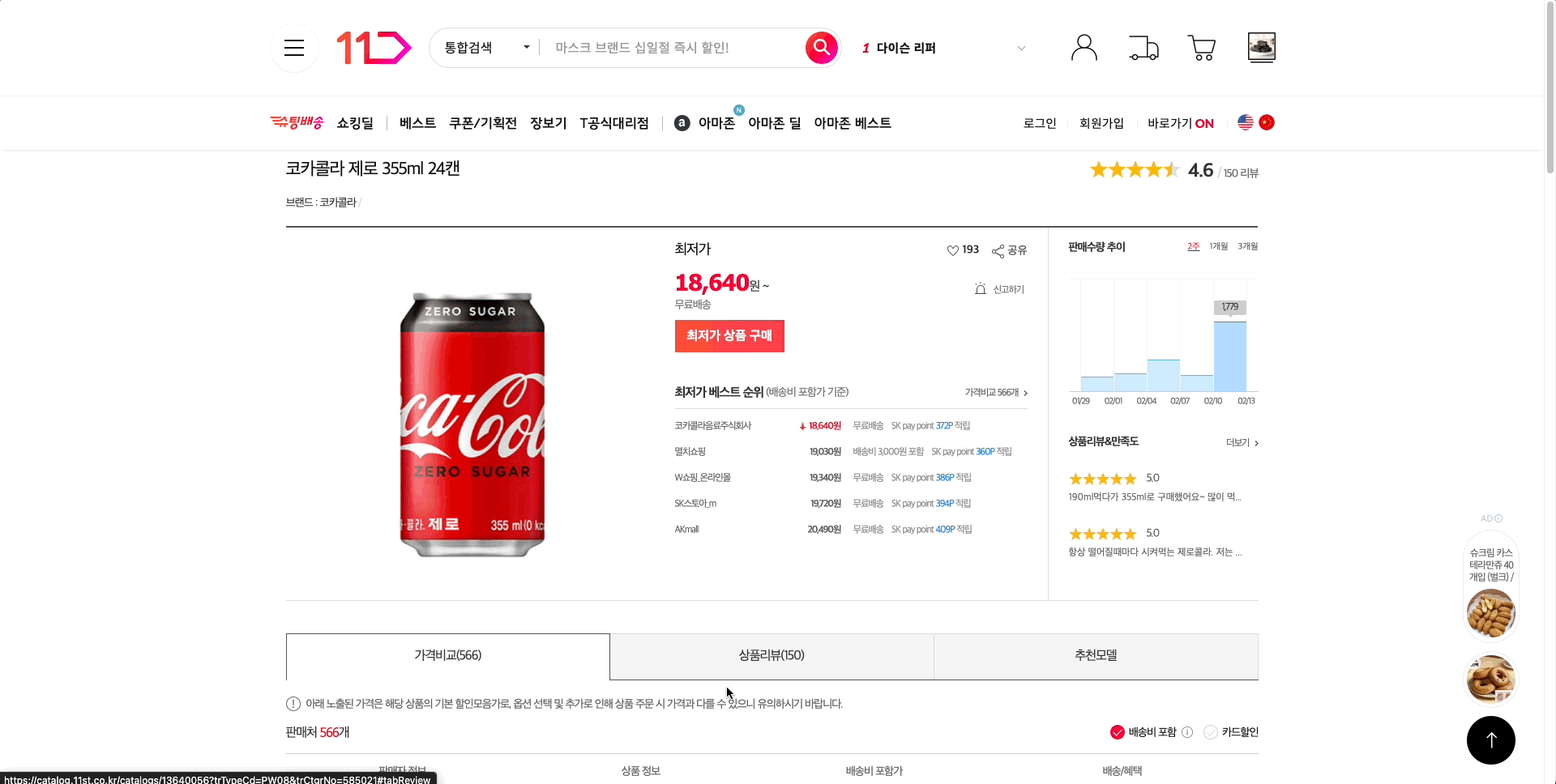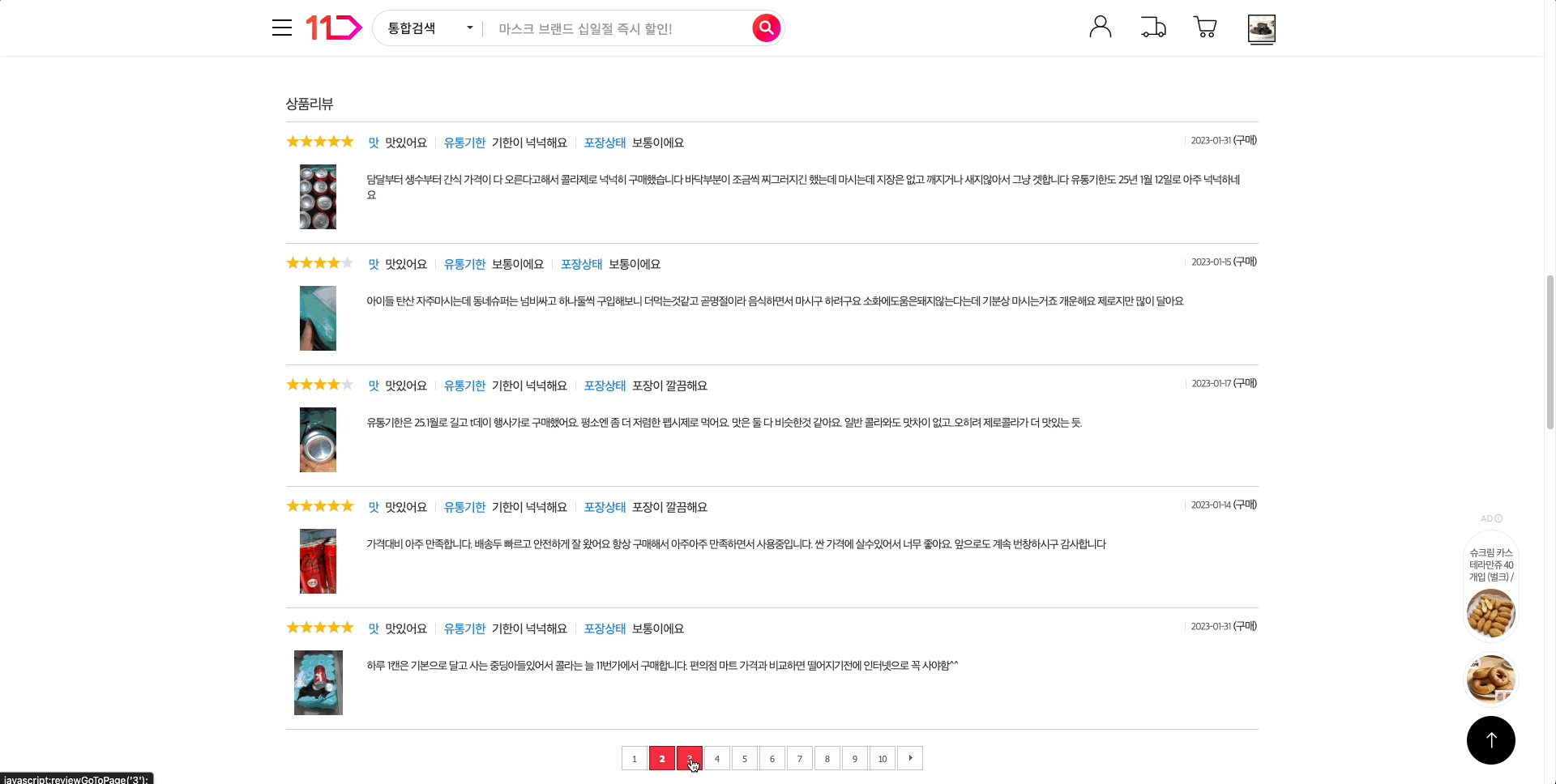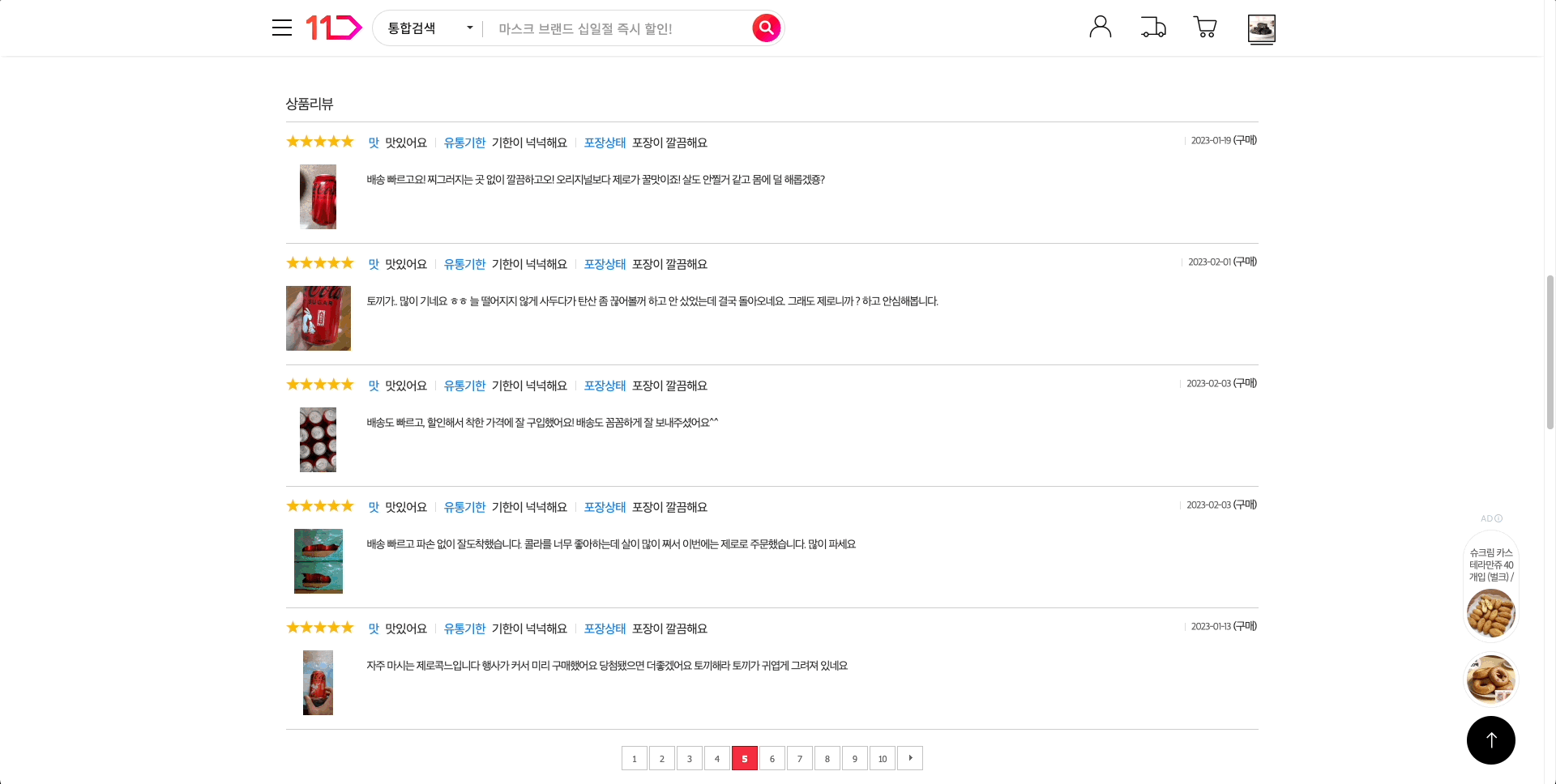
카탈로그 리뷰 페이지를 새로고침 시 데이터가 간헐적으로 나오지 않았던 현상을 해결하고 카탈로그 리뷰를 빠르게 보여주고 있습니다.
사용자들이 느낄 수 있는 부정적인 경험을 개선하고, 150개로 제한하고 있던 카탈로그 리뷰 개수 또한 더 늘릴 수도 있게 되었습니다.
카탈로그 리뷰 API 개선 이전과 이후의 히트맵 트랜잭션 사진입니다.
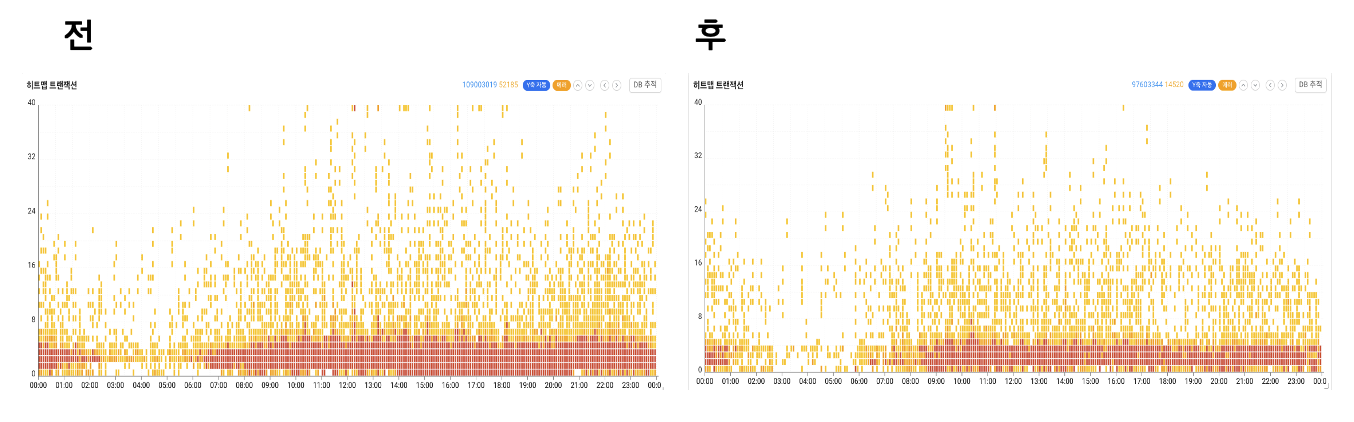
카탈로그 리뷰 API 개선 후로 에러가 줄어든 것을 확인할 수 있습니다.
글로벌 캐시 도입과 호출 빈도가 높은 카탈로그 리뷰 데이터 자동 최신화로 로컬 캐시의 만료로 발생하는 무거운 쿼리의 실행빈도가 WAS 인스턴스 수에 비례하여 감소했습니다.
그로인해, DB 역시 부하가 감소한 것을 알 수 있습니다.
되돌아보며
인턴 기간동안 Cache와 Redis에 대해 고민하고 공부해가며 진행했습니다.
인턴으로 진행하는 과제가 실제 상용에 배포되어 고객들에게 서비스된다는 점이 저에겐 설렘과 두려움 모두를 느끼게 해주었습니다.
그래서 제가 생각한 방법들과 코드에 대해 더 많이 고민했던 것 같습니다.
인턴에게 상용 배포를 경험하게 해주신 저희 PDP개발팀분들에게 정말 감사합니다.
앞으로
인턴 당시에는 정말 열심히 진행하였지만 경험을 정리하면서 돌아보니 아쉬움이 남아있습니다.
글로벌 캐시가 로컬 캐시보다 앞 단에서 처리하기 때문에 로컬 캐시가 잘 사용되지 않는 구조이기 때문입니다.
당시에는 Redis Sorted Set을 사용하기 위해 이런 결정을 했지만, Spring에 존재하는 CompositeCacheManager 등을 모티브하여 Cache 자체를 구현하여 두 개의 Cache Layer를 활용하는 방법도 있는데 말이죠.
스스로 진행한 과제에서 이런 아쉬움을 뒤에 남겨두지 않기 위해 Multi-layer Cache 자체를 구현하여 상품 상세에 적용하고 있습니다.
Multi-layer Cache를 직접 구현하며 느낀 경험도 추후에 공유할 수 있도록 노력하겠습니다.
긴 긁 읽어주셔서 감사합니다. 🙇🏻