한계에 도달한 전시 서버, 그리고 우리의 해답
java , MongoDB , spring-boot , gc , cache , monitoring
늘어나는 트래픽, 늘어나는 서버: 한계를 돌파하다
안녕하세요. 11번가 전시서비스개발팀에서 백엔드를 담당하고 있는 서장원입니다.
이번 글에서는 고객이 11번가에 처음 진입하는 관문인 전시서비스를
더 비용 효율적으로, 그리고 대량 트래픽 환경에서도 안정적으로 운영하기 위해
전시서비스개발팀의 김민교 님과 함께 고민하고 풀어나갔던 과정에서 다뤘던 주요 개선 포인트를 중심으로 소개합니다.
목차
미리보기: 핵심 개선 포인트
들어가기 전에, 최적화 작업에서 핵심적으로 다룬 3가지 개선 포인트를 미리 소개하면 다음과 같습니다.
- CPU 스파이크 분산: MongoDB 커넥션 재생성 시간 분산으로 CPU 부하 안정화
- 지연 트랜잭션 병목 개선: 재시도 정책 조정 및 커넥션 풀 확충
- 서버 리소스 관리 개선: 캐시 최적화 및 대량 조회 제한
이제 각 개선 포인트에 대해 상세히 살펴보겠습니다.
들어가며
트래픽의 꾸준한 증가 - 전시API 서버(DPWAS)


그래프에서 볼 수 있듯이 매년 전시 API 서버(DPWAS)의 트래픽이 꾸준히 증가해왔습니다.
MSA 환경 속 여러 영역에서 전시API 호출하는 횟수와 비중이 매년 증가해옴에 따라 트래픽 또한 증가했습니다.
특히 행사 시즌과 이벤트, 라이브 방송도 잦아지면서 이용자들의 관심도에 따라 버스트 트래픽(Burst Traffic)이 발생하는 크기와 빈도가 늘었습니다.
예상 가능한 시간대(ex, 십일절 행사, 라이브 방송 등)의 버스트 트래픽(Burst Traffic)에 대해서는 미리 서버를 늘려(Scale-out) 대응하거나,
수동 트래픽 제어를 통해 전시 API 서버의 트래픽을 제한하여 안정적인 서비스가 가능하도록 조절해왔습니다.
이렇게 늘어가는 트래픽에 즉각 대응하기 위해 일시적인 방안들을 적용해왔지만,
더 나은 운영환경을 위해, 사전적 성능관리 측면에서 전체 점검 및 개선정비는 도움이 됩니다.
“마치 집을 매일 청소하더라도, 어느 시점에는 대청소가 필요하듯 지금이 바로 그 대청소의 타이밍.”
운영방식의 한계와 새로운 전략
그동안 대용량 트래픽에 대응해왔던 대표방법인 Scale-out 은 트래픽 증가 대응에 권장하는 방법이지만,
추가된 서버 수만큼 경제적인 비용과 운영비용도 증가하는 문제점이 있습니다.
바로 체감할 수 있었던 문제 중 한 가지는 배포 시간이 점점 늘어나고 이슈로 인한 롤백 시간에도 부담이 생기기도 했습니다.
최적화를 통해 더 적은 서버 수로 운영할 방법 모색이 필요했습니다.
인프라팀에서 CPU 코어 수를 늘리고 서버를 줄이는 대안을 제안해 주셨고,
개발팀에서는 서버를 줄였을 때 안정적인 운영이 가능하도록 어플리케이션 효율을 끌어올리는 방법을 찾게 되었습니다.
협업 전략: 구조 개선과 최적화
비용 효율과 안정성이라는 두 마리 토끼를 잡기 위해, 인프라팀과 전시서비스 개발팀은 각자의 영역에서 최적의 전략을 수립했습니다.
- 인프라팀: Scale Up + Scale In 전략
인프라팀에서 CPU 코어를 증설(Scale-up) 하고 서버를 축소(Scale-in) 하여 성능을 확보하는 작업을 진행했습니다.
CPU 코어의 Scale-up/down은 상대적으로 유연하게 조치 가능하고, 실제로 비용적인 측면에서도 서버 비용보다는 저렴한 장점이 있었습니다.
즉, 피지컬을 줄이고 뇌지컬을 높인다.
- 서버축소 110대 → 70대 (기존대비 65%로 운영)
- CPU 코어 증설(scale-up) 8코어 → 16코어
- 전시서비스개발팀: Tune Up + Fix in 전략
전시서비스개발팀에서는 줄어든 서버(Scale-in) 환경에서도 대량의 트래픽을 안정적으로 처리하기 위해,
어플리케이션 레벨에서의 병목을 제거하고 성능을 끌어올릴 수 있는 튜닝에 집중했습니다.
- 리소스 병목 탐지 및 해소: CPU, Memory 리소스 효율화
- 트랜잭션처리 효율화: 지연 유발 포인트 개선
- 시스템 안정성 확보: 메모리 사용량 제어 및 대량 조회 최적화를 통한 리소스 안정화
개선과정(Tune Up + Fix in!)
1) 원인불명의 CPU Spike 발생: MongoDB 커넥션 재생성 부하
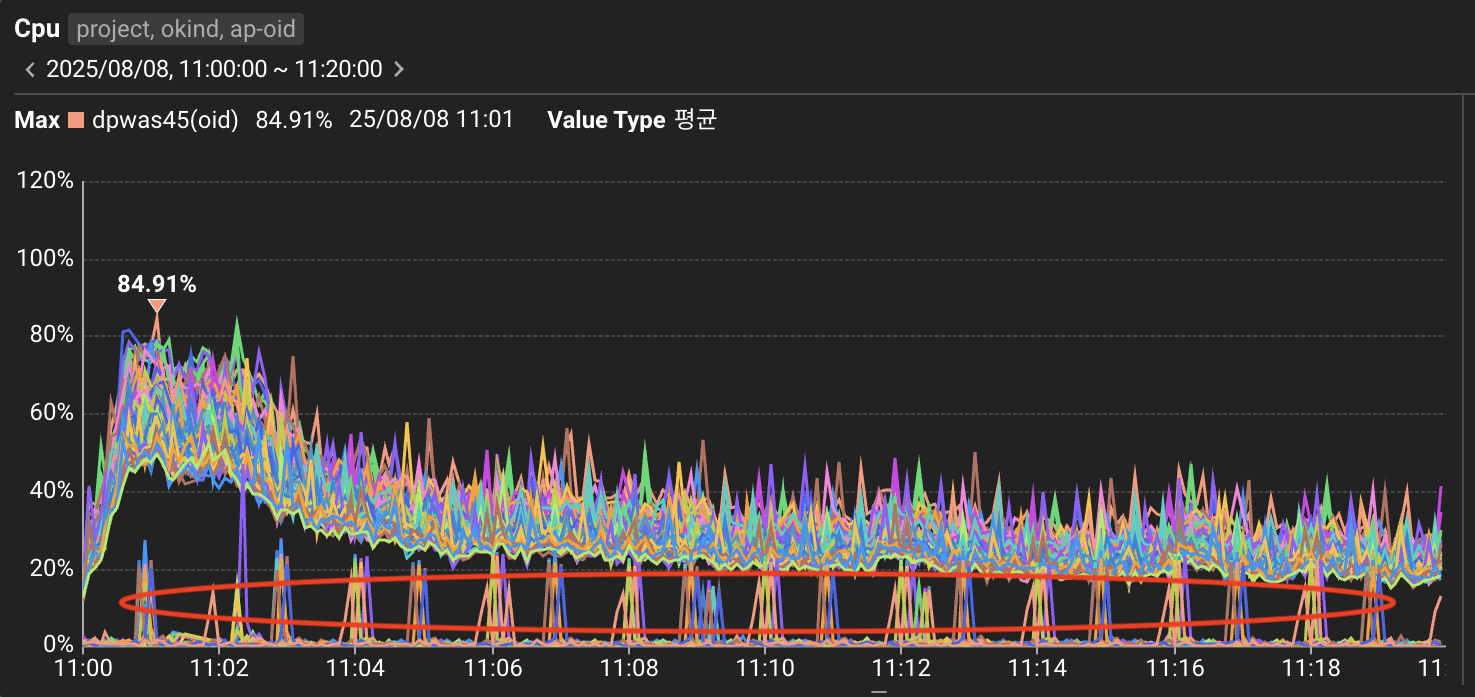
붉은 동그라미 부분은 트래픽을 차단한 일부 서버입니다. 2분마다 CPU Spike 현상이 두드러집니다.
Scale-in 작업을 위해 일부 서버의 트래픽을 차단하고 모니터링을 했을 때,
2분마다 주기적으로 CPU 사용률이 25% 이상 급증하는 현상이 발견되었습니다.
트래픽이 없는 상태라면 CPU가 25%까지 솟을 일이 없어야 정상인데, 이렇게까지 솟는다는 것은 비정상적이었습니다.
일반적으로 프로메테우스와 같은 모니터링 툴의 스크랩 작업이라도 25% 이상의 Spike는 그 범위를 크게 넘어서는 수준이었습니다.
평시에는 실제 트래픽에 의한 CPU 사용률과 합쳐져서 발견되지 않았던 히든 케이스였지만, 트래픽을 제거한 순간 이 현상이 명확히 드러난 상황입니다.
이러한 주기적인 CPU Spike가 서버 전체 CPU 사용률에 지속적으로 영향을 미치고 있었고,
버스트 트래픽 상황에서는 더욱 치명적일 수 있다고 판단했습니다.
원인을 파악하기 위해 가능성이 있는 지점들을 리스트업하고, 차례대로 검증하는 방법으로 접근했습니다.
CPU Spike 발생 원인 예상지점 리스트업
| No. | 영향 | 의심 지점 | 관련 증상 | 확인 방법(트래픽제거후 확인) | 확인 결과 |
|---|---|---|---|---|---|
| 1 | △ | 노후 서버 | 장비별 다른 다른 양상 | 노후/신규 장비 간 성능 비교 분석 | 신규 서버보다 더 민감한 CPU 반응 |
| 2 | × | 서버내 Redis 커넥션 문제 | 주기적인 커넥션 생성/해제 시 CPU 스파이크 | Redis 커넥션 로그 분석, 커넥션 설정 변경 | 레디스 커넥션 풀 구성을 적용했지만 여전히 스파이크 발생 |
| 3 | × | 가비지 컬렉션(GC) | 주기적인 CPU 스파이크, 메모리 사용량 변동 | GC 설정확인, GC 로그 분석, 힙 덤프 | 로그상으로 원인을 알기는 어려움 |
| 4 | × | 스레드 | 데드락 또는 스레드 경합 시 CPU 사용률 증가 | 스레드 덤프 분석 | 스레드 dump로 뚜렷한 원인성 로그는 보이지않음 |
| 5 | × | 모니터링 툴 스크랩 | 데이터 수집 시 일시적 CPU 사용량 증가 | 모니터링 툴 스크랩 주기 확인 및 제거후 스파이크 확인 | 스크랩을 제거해봤지만 여전히 CPU Spike 발생 |
| 6 | ○ | MongoDB 커넥션 관리 | 커넥션 풀 재구성 시 CPU 부하 집중 | MongoDB 커넥션 풀 설정 확인, 프로파일링 | 커넥션 생성 집중분산 후 스파이크 현상 제거됨 |
| 7 | × | 기타 주기성을 가진 어플리케이션 설정 | 서버내 주기성을 가진 설정에 의한 CPU 사용율 증가 | 관련설정값 조정 전후 cpu 스파이크 비교 | 주기성 설정을 변경했지만 여전히 CPU Spike 발생 |
리스트업된 예상 지점을 차례로 확인해보니 2개의 원인이 보였습니다.
CPU Spike 원인 1 : 노후장비 서버
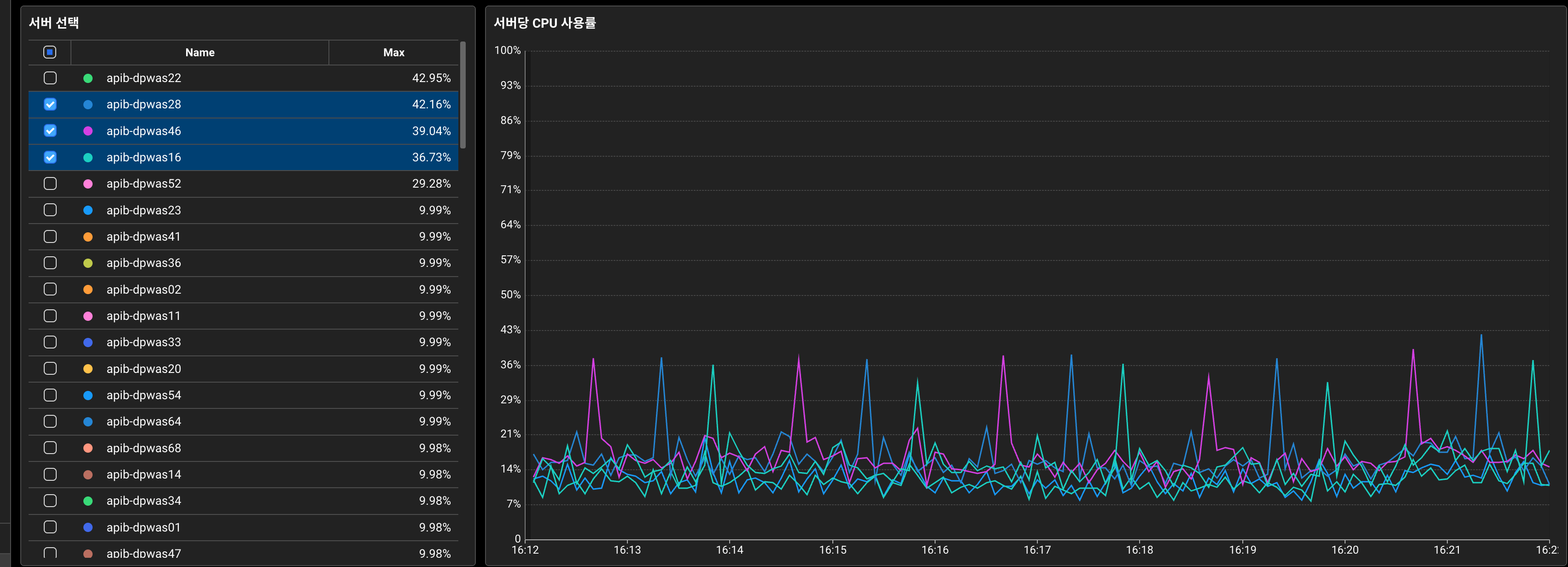
노후 장비 서버에서 CPU 사용률 Spike 현상이 두드러집니다. 즉, 더 예민하게 CPU가 반응합니다.
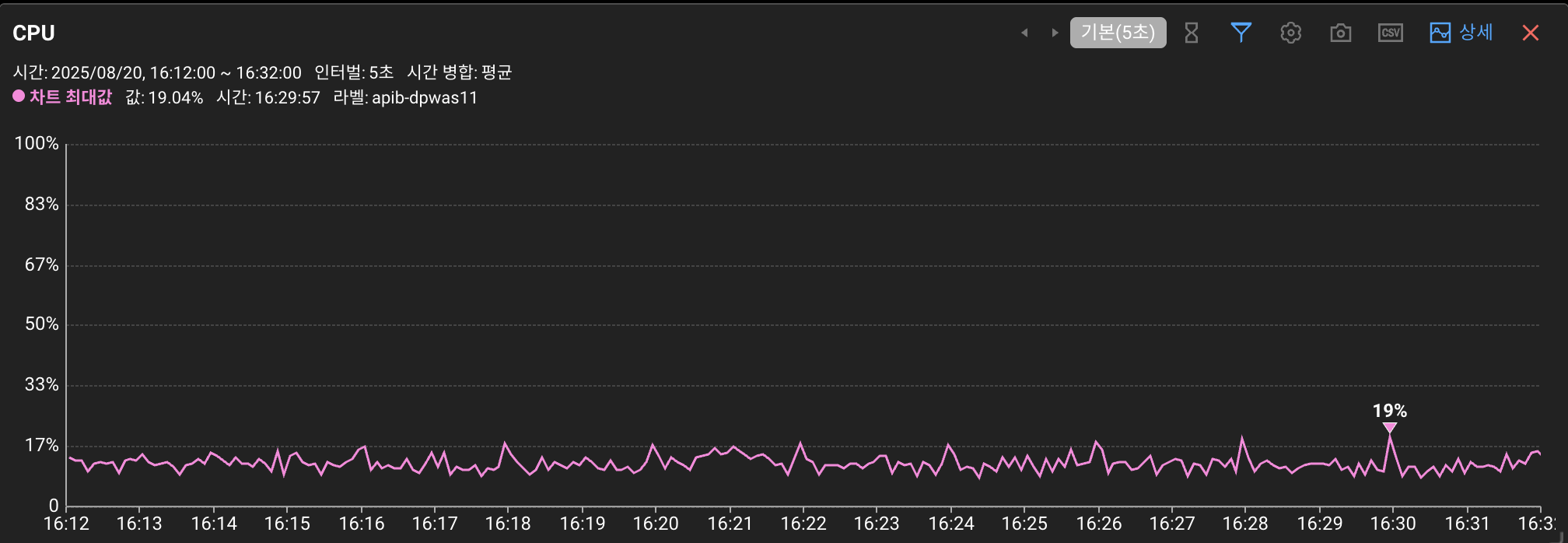
신규 장비 서버에서도 2분마다 주기적으로 상승하는 점이 보입니다.
하지만, 덜 예민한 신규 장비 서버에서도 여전히 2분마다 CPU 가 상승하는 현상이 보였기 때문에,
원인을 알아내고 정상적인 현상인지, 비정상적인 현상인지 확인해야 할 필요성이 있었습니다.
CPU Spike 원인 2: MongoDB 커넥션 재생성 부하 집중
: 왜 CPU Spike 현상이 보이는 거죠?
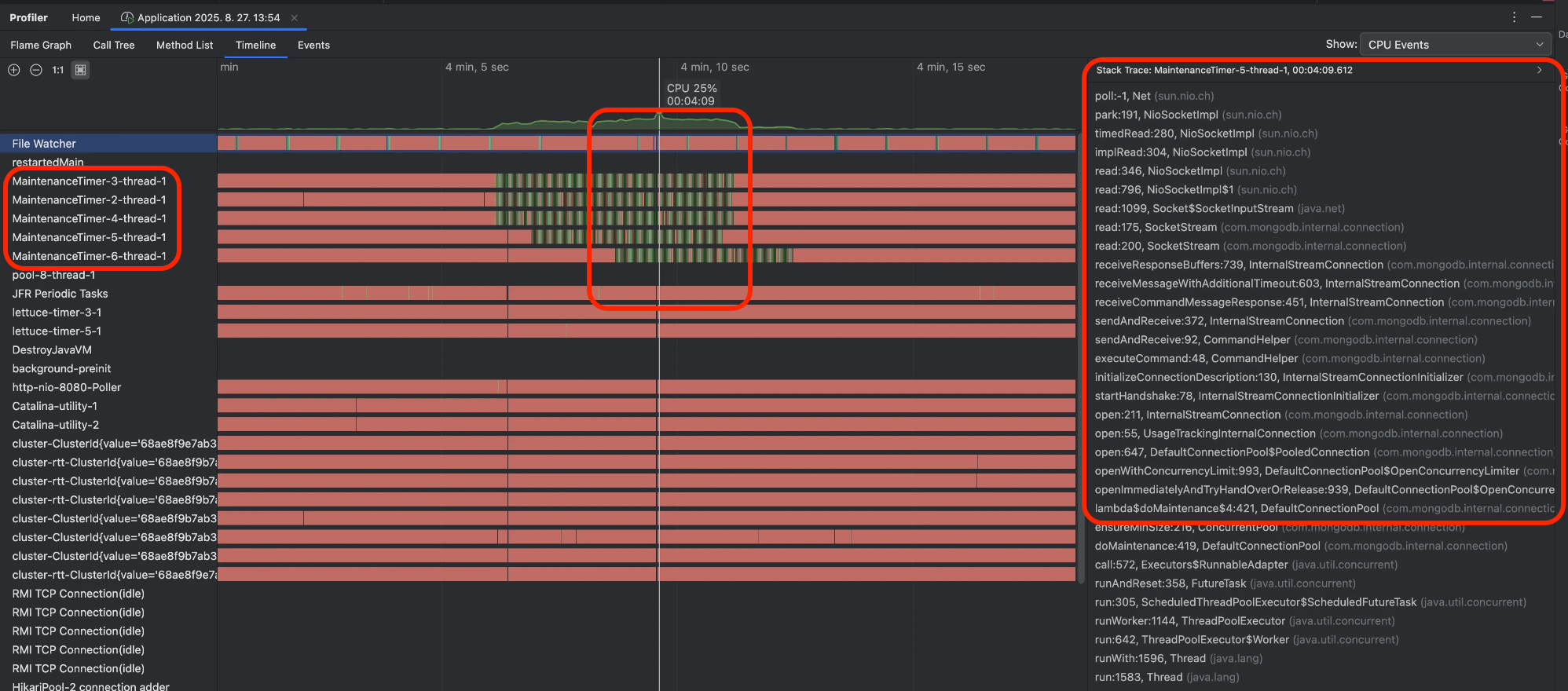
Intellij 의 Profiling 기능 실행시 Timeline 탭 CPU 점유 집중 화면. 왼쪽 목록은 프로세스목록. 오른쪽은 StackTrace.
- 원인은 MongoDB 커넥션 풀의 커넥션 대량 재생성 작업이었습니다.
- MaintenanceTimer-X-thread-1(=커넥션 풀 유지 보수 스레드)이 비슷한 시점(가운데 붉은 박스)에 CPU를 집중적으로 점유하고 있습니다.
- 해당 시점의 Stack Trace를 관찰하면 대부분 MongoDB 커넥션 생성 작업 중입니다.
- 즉, 커넥션 풀의 대량 커넥션 생성이 동시에 집중되면서 CPU 사용률이 급증한 것이 원인이었습니다.

"CPU 스파이크 원인은 MongoDB의 커넥션 재생성 작업이라는 사실이 더욱 명확해졌다."
이 문제를 해결할 핵심 키워드는 maxConnectionIdleTime 입니다.
커넥션의 최대 유휴 시간 지정 옵션(default: 무제한)을 조절하여 커넥션 재생성 작업을 분산(Spread) 시킬 수 있습니다.
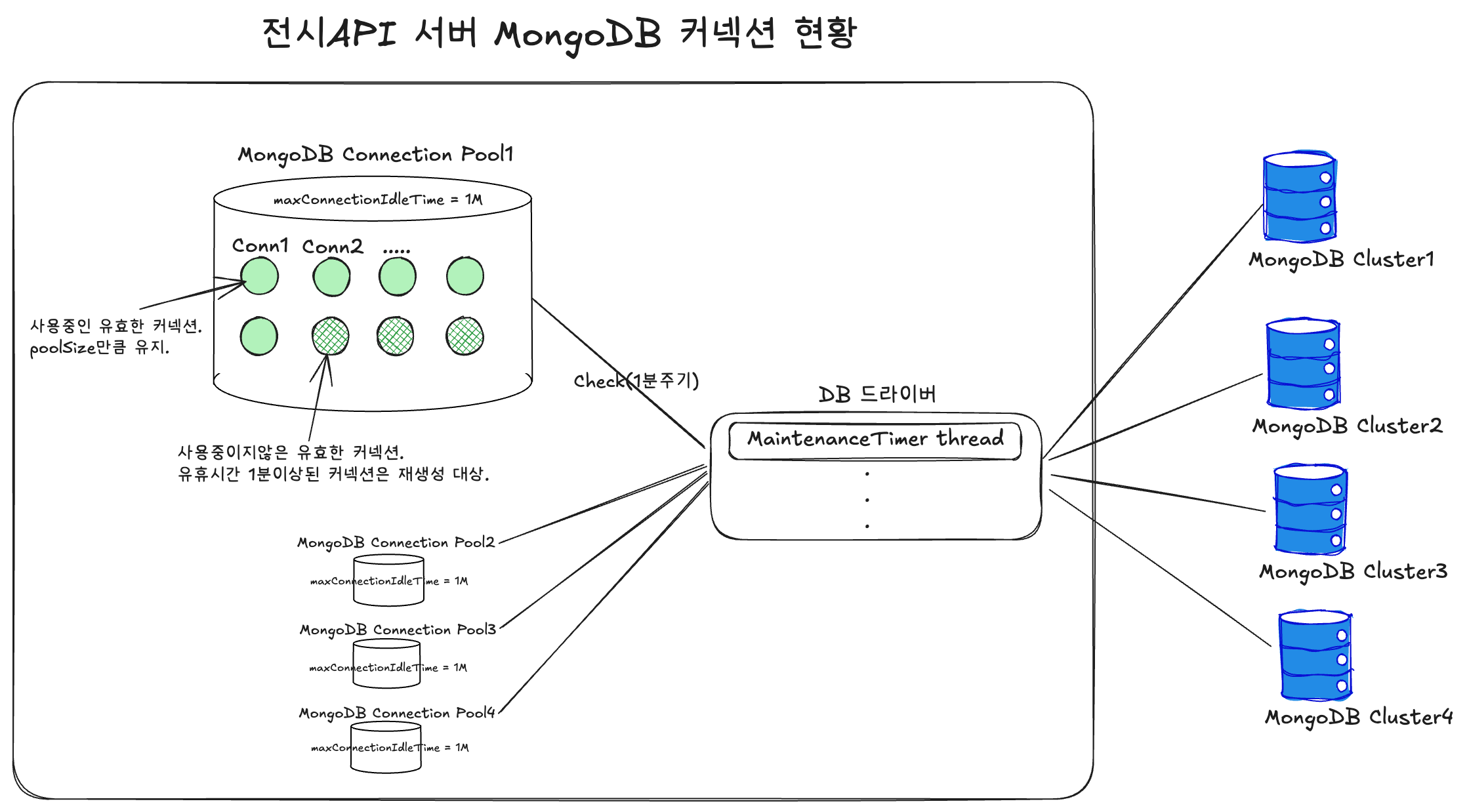
전시 API 서버 - MongoDB Driver - MongoDB Cluster 구조도. MaintenanceTimer Thread 가 1분주기로 커넥션을 체크한다
질문1. 그런데 왜 커넥션 생성 작업이 집중되었을까?
- 전시 API 서버에서 연결 중인 서로 다른 4개 MongoDB(A, B, C, D)의 인스턴스 드라이버 연결 설정은 maxConnectionIdleTime = 1분으로 모두 동일하게 설정되어 있었습니다.
- 유휴시간이 1분 이상 경과된 커넥션은 MaintenanceTimer에 의해 모두 재생성하는 작업을 합니다.
- 재생성 작업이 4개 인스턴스에서 동시에 이루어지면서 CPU 사용량이 집중됩니다.
질문2. 커넥션 연결이 CPU 리소스를 많이 차지하는 이유는?
- 전시 API 서버는 대량의 트래픽과 대량 버스트 트래픽에 원활한 DB 자원 사용을 위해, 가능한 많은 커넥션을 유지합니다.
- 그 결과, MaintenanceTimer에 의해 이 많은 커넥션이 동시에 재생성되면서 CPU 자원을 순간적으로 많이 사용하게 됩니다.
질문3. 가장 궁금했던, 1분 주기가 아닌 2분 주기로 CPU 스파이크 현상이 발생하는 이유?
- MaintenanceTimer는 커넥션 풀의 건강한 상태 유지/보수를 위해, 1분마다 유휴 커넥션을 체크하고 재생성 작업을 합니다.
- 즉, '체크 주기(1분)'와 커넥션 풀의 '최대 유휴 시간(1분)'이 일치하여, 1분 체크 시점에는 아직 1분 미만으로 간주되어 살아남고, 다음 1분 체크 시점에야 1분 초과로 제거되어 총 2분 주기로 동작합니다.
타임라인
00:00초: 커넥션 생성 및 사용(ex. 사용시간 1초)
00:01초: 커넥션 유휴상태 확정
01:00초: MaintenanceTimer의 유휴 커넥션 1분 주기 check → 아직은 유휴상태로 전환된지 59초 경과 → 유휴 대기시간 1분 미만이므로 커넥션 유지
01:01초: 커넥션의 유휴상태 1분 초과 확정
02:00초: MaintenanceTimer의 1분 주기 check → 유휴 1분 초과 커넥션 발견 → 초과 커넥션 모두 닫음 → min 커넥션풀만큼 모두 새 연결
2분마다 위 과정 반복. 커넥션 대량 동시 재연결 -> CPU Spike 발생
질문4. 그렇다면 maxConnectionIdleTime 설정이 반드시 필요한가? (=제거하면 어때?)
커넥션이 유지된 채로 두면 재사용에 유리한 게 아닐까? 라는 의문이 생길 수 있습니다 → 서버 사이드 단절(Half-Open Connection), 메모리 파편화
💡 maxConnectionIdleTime 설정의 필요성
-
Half-Open Connection 문제
- 주기적으로 Client-Side에서 유휴 커넥션을 끊어주지 않으면 Half-Open Connection 상태로 전환되어 요청은 모두 실패(에러 응답)합니다.
- 즉, Half-Open Connection 상태가 되면 재사용할 수 없는 죽어있는 커넥션으로 이해 할 수 있습니다.
- 필요성에 대한 자세한 설명은 아래 그림과 함께 설명을 넣어두었습니다.
-
힙 메모리 파편화 이슈
- Half-Open Connection(stale connection)이 메모리를 할당한 채로 유지한다면,
신규 작업을 위한 연속적인 메모리 할당이 불가능해질 가능성이 높습니다. - 하지만, 전시 서버는 ZGC를 사용하고 있어, 객체 이동과 컴팩션이 모두 동시(Concurrent) 수행됩니다.
객체의 이동과 동시에 빈 공간이 큰 연속된 메모리 공간으로 컴팩션되기 때문에
어플리케이션의 중지 없이 지속적으로 메모리 파편화가 해소됩니다.
그 결과 메모리가 조각날 여지가 거의 없어, 힙 파편화가 사실상 거의 발생하지 않는 정도의 안정성이 확보되어 있습니다.
- Half-Open Connection(stale connection)이 메모리를 할당한 채로 유지한다면,
아래 그림에서 Server-Side와 Client-Side 간에 Half-Open Connection이 발생하는 과정을 3단계로 요약해서 살펴볼 수 있습니다.
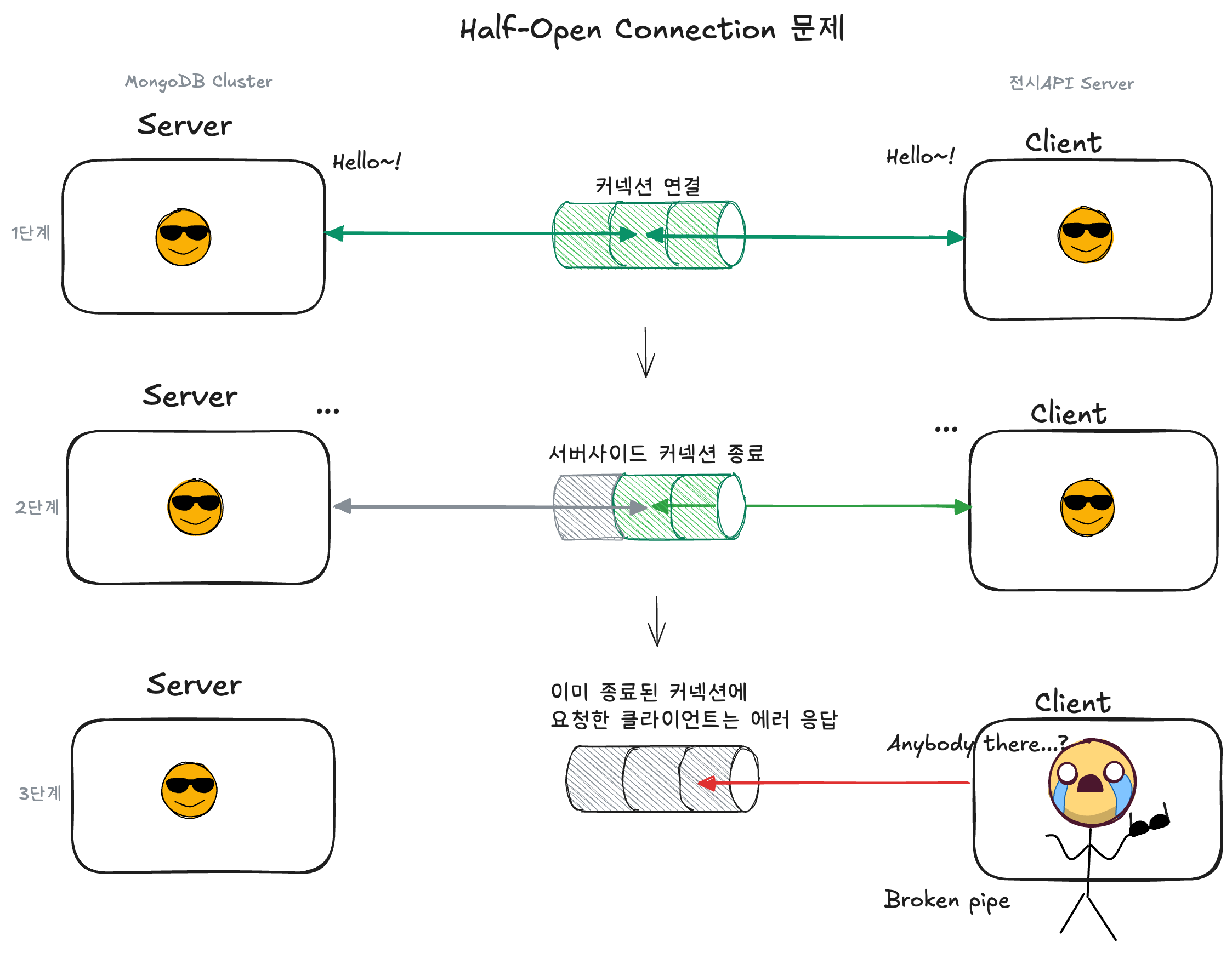
Half-Open Connection 이해를 돕기위한 3단계(연결-종료-에러) 형태의 단계별 커넥션 스냅샷
1단계: 커넥션 연결
- Server와 Client 간 정상적인 커넥션이 연결되어 통신 중인 상태입니다.
2단계: Server-Side 커넥션 종료
- 시간이 지나면서 Server는 유휴 커넥션을 자동으로 종료합니다.
- 하지만 Client는 이 사실을 전혀 알지 못하고, 커넥션 풀에 여전히 “사용 가능”한 상태로 보관 중입니다.
3단계: 이미 종료된 커넥션에 요청 → Broken Pipe 등 에러 발생
- Client가 커넥션 풀에서 해당 커넥션을 꺼내어 요청을 보내는 순간 “Anybody there…?” 응답이 없습니다!
- 이미 닫힌 커넥션이므로 ‘Broken Pipe’ 등 에러가 발생합니다.
이처럼 Half-Open Connection은 Client-Side에서 요청을 보내야만 커넥션이 끊겼다는 사실을 알 수 있어,
실제 트래픽이 유입되는 순간 에러가 터지게 되므로 사용자 경험에 직접적인 영향을 미칩니다.
이를 예방하기 위해 반드시 maxConnectionIdleTime 설정을 통해
클라이언트가 서버보다 먼저 주기적으로 유휴 커넥션을 정리하고 재생성하도록 하여 최대한 사용 가능한(available) 커넥션을 유지하도록 합니다.
CPU Spike 해결책: 집중된 CPU 부하를 분산시키자
- minPoolSize=maxPoolSize 유지
- 전시 API 서버는 짧은 시간에 최대한 많은 트래픽(요청)을 받아낼 수 있도록 가능한 많은 커넥션을 유지하도록 합니다.
- 이를 위해 minPoolSize와 maxPoolSize를 동일하게 설정합니다.
- 커넥션이 최대로 유지되어 있어야 모든 요청을 즉시 처리할 수 있고, 커넥션 부족으로 인한 오류를 최소화 할 수 있기 때문입니다.
- minPoolSize를 maxPoolSize보다 작게(minPoolSize < maxPoolSize) 설정할 경우,
버스트 트래픽 발생 시 커넥션 재생성으로 인한 비용과 지연이 발생할 수 있습니다.
- 각 MongoDB 인스턴스별 커넥션 재생성 시간 분산
- maxConnectionIdleTime을 인스턴스별 5분 단위로 분산시킵니다.
- 50분, 55분, 60분, 65 분으로 분산설정 (CPU 사용률이 Spread 됩니다)

MongoDB Driver 설정에 커넥션 최대유휴시간 설정방법
- 결과 및 효과(노후 장비)
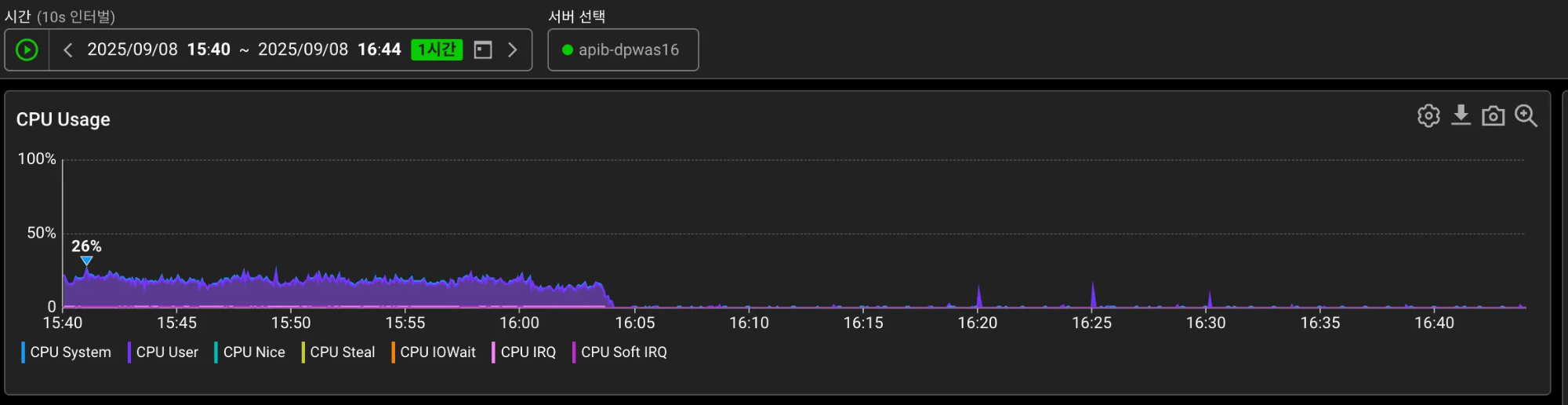
외부 변인을 제거하기 위해 노후 장비 서버 트래픽 차단 후 모니터링(약 16:05분)
- 노후장비(CPU Spike 25%)의 트래픽 분산 결과는 트래픽 차단 시점부터 25% → 9%로 감소하여 5분 단위로 분산되었습니다.
- 노후장비(CPU Spike 25%)의 트래픽 분산 결과는 트래픽 차단 시점부터 25% → 9%로 감소하여 5분 단위로 분산되었습니다.
- 결과 및 효과(신규 장비)
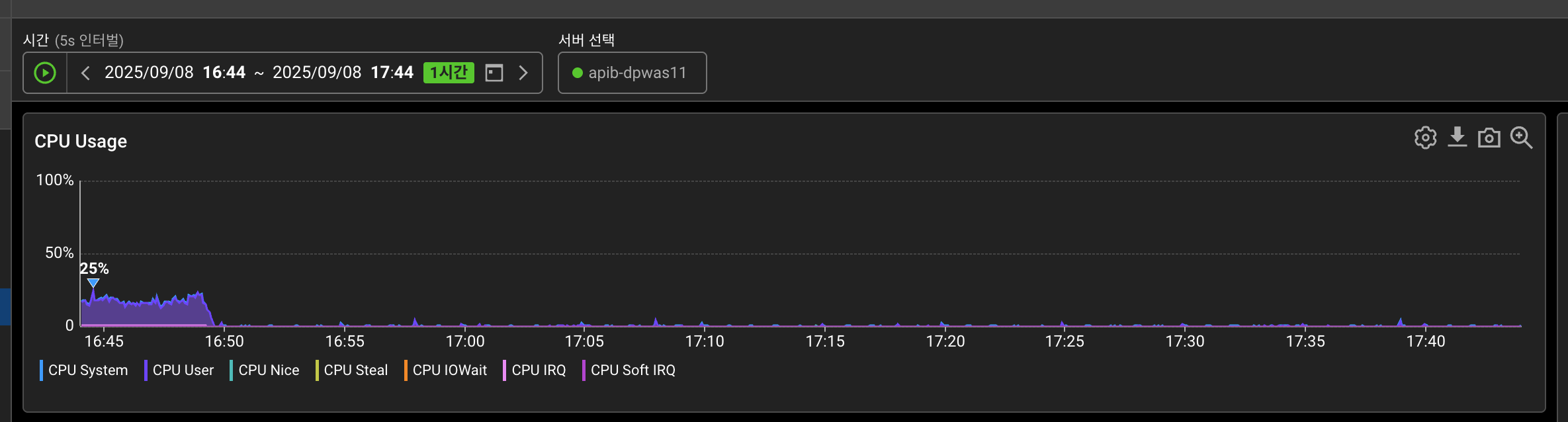
외부 변인을 제거하기 위해 신규 장비 트래픽 차단 후 모니터링(약 16:50분)
- 신규장비의 트래픽 분산 결과는 트래픽 차단 시점부터 약 8%→ 2-3%로 감소하여 사실상 Spike 현상이 거의 없어졌습니다.
- maxConnectionIdleTime을 인스턴스별 5분 단위로 분산시킵니다.
2) 지연 트랜잭션을 줄여보자

커넥션 증설 전후 TPS 50k 비교(왼쪽: 증설전, 오른쪽: 증설후)
왼쪽 증설전 히트맵을 관찰하면 12:00시에 순간적인 버스트 트래픽이 유입되면서 API 응답에 지연이 발생한 것을 볼 수 있습니다.
(*히트맵 세로줄 패턴: 트랜잭션의 일시적인 지연 발생 후 해제되면서 생기는 세로줄 패턴)
커넥션 풀 사이즈 확보
전시 API 서버 트랜잭션 중 Top-Traffic Endpoint는 최종적으로 MongoDB 조회입니다.
호출 속도에 비해 커넥션 풀 사이즈가 부족할 경우, 트랜잭션 지연과 함께 아래와 같은 에러를 확인할 수 있습니다.

이번 개선에서는 서버를 약 65%로 축소 운영하면서 서버당 트래픽은 약 1.6배 증가했습니다.
이에 따라, 커넥션 풀 사이즈를 충분하게 늘려주었습니다.
이때, 중요한 포인트는 DBA와 협의를 통해 서버사이드(DB서버) 커넥션 풀 사이즈가 클라이언트 사이드(API서버)만큼
충분히 증가되어 있는지 반드시 확인해야 합니다.

서버 사이드의 maxIncommingConnections 5k → 10k 증설후, 클라이언트 사이드의 maxConnectionPoolSize 도 10k 까지 증설가능하다.
재시도 기능 제어
추가로, 버스트 트래픽이 발생하는 경우 MongoDB SocketReadTimeout(Timeout while receiving message) 예외도 발견되었습니다.
위 히트맵에서 빨강, 주황 점으로 찍힌 에러건들입니다.
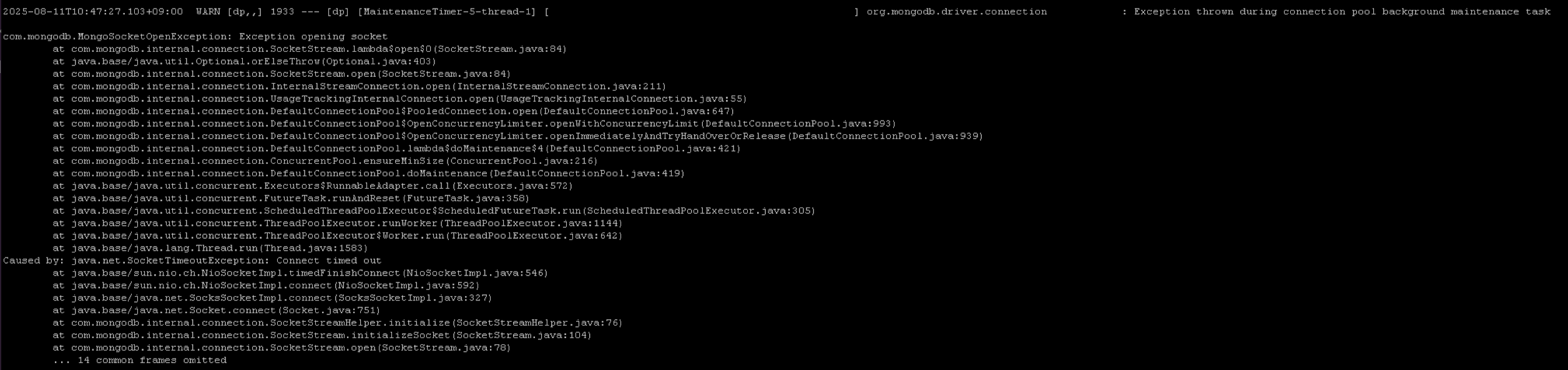

흥미로운 현상은, 예외가 발생했지만 응답 상태 코드는 200(정상 응답 상태 코드)인 경우가 있었습니다.
이는 MongoDB 자바 드라이버의 재시도 설정으로 인해, 동일 트랜잭션 내에서 예외 발생 후 재시도하여 성공한 경우입니다.
이 케이스의 200 응답은 트랜잭션이 자원을 오래 점유함으로써 전체 서비스의 지연을 발생시키고,
클라이언트가 불필요하게 늦은 응답을 받게 만드는 요인입니다.
결국 TimeoutException 이 발생하고 fallback 처리가 예상보다 늦게 수행됩니다.
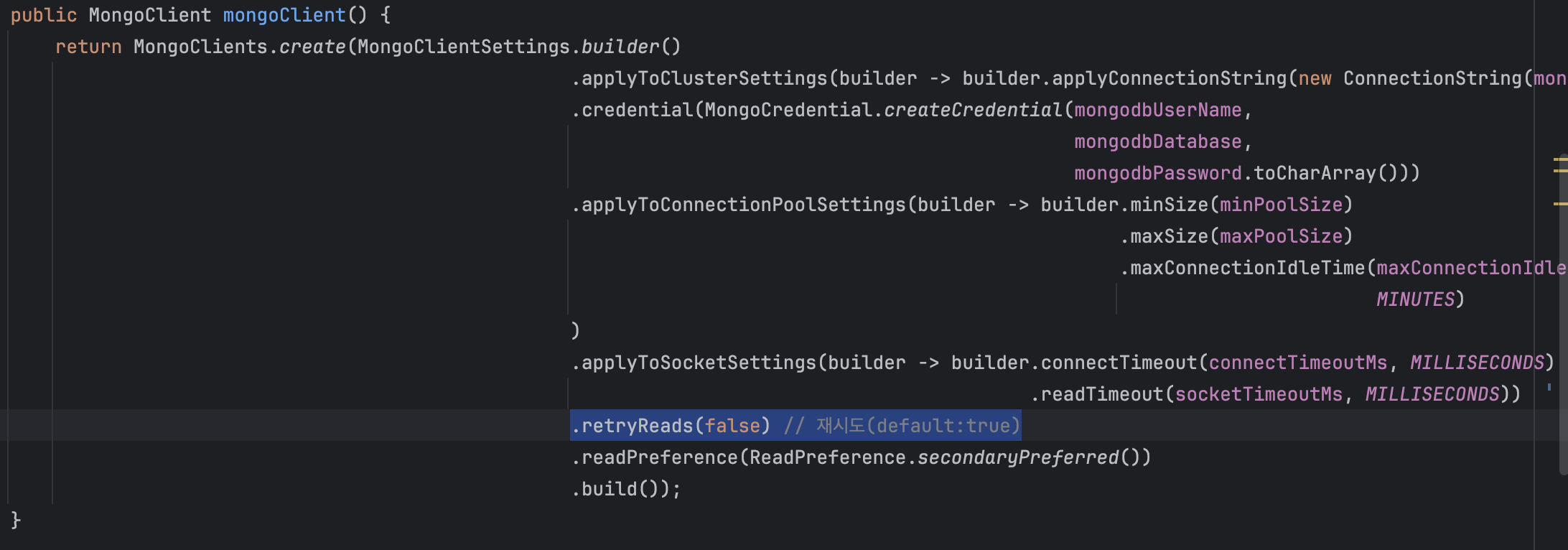
MongoDB Driver 재시도 설정 Off
버스트 트래픽 시 이러한 사이드 이펙트를 완화하기 위해 재시도 기능을 비활성화하는 Fast-Fail 전략을 선택했습니다.
이 전략은 일시적인 네트워크 오류나 일시적인 DB 부하 상황에서 실패율이 증가할 수 있지만,
버스트 트래픽 환경에서는 재시도로 인한 지연이 전체 시스템에 미치는 영향이 더 크기 때문에 전체적인 처리량과 안정성을 우선시하는 선택이었습니다.
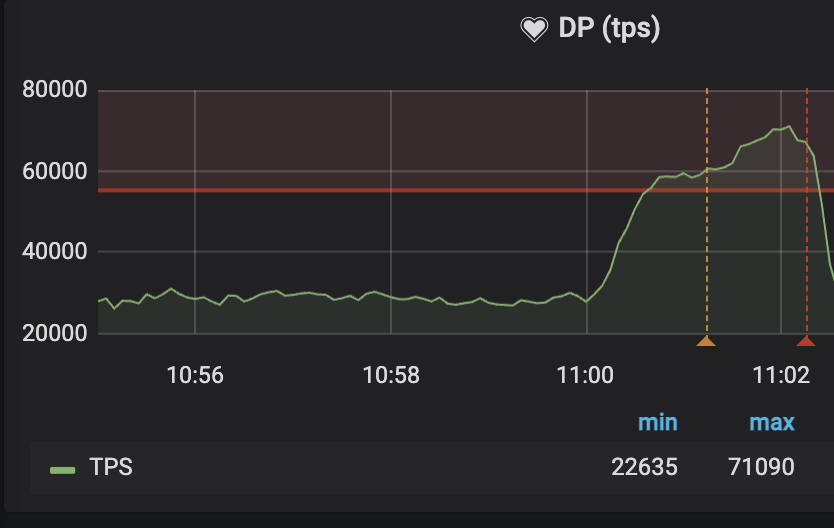
11:00시 TPS 71K Burst Traffic 지표
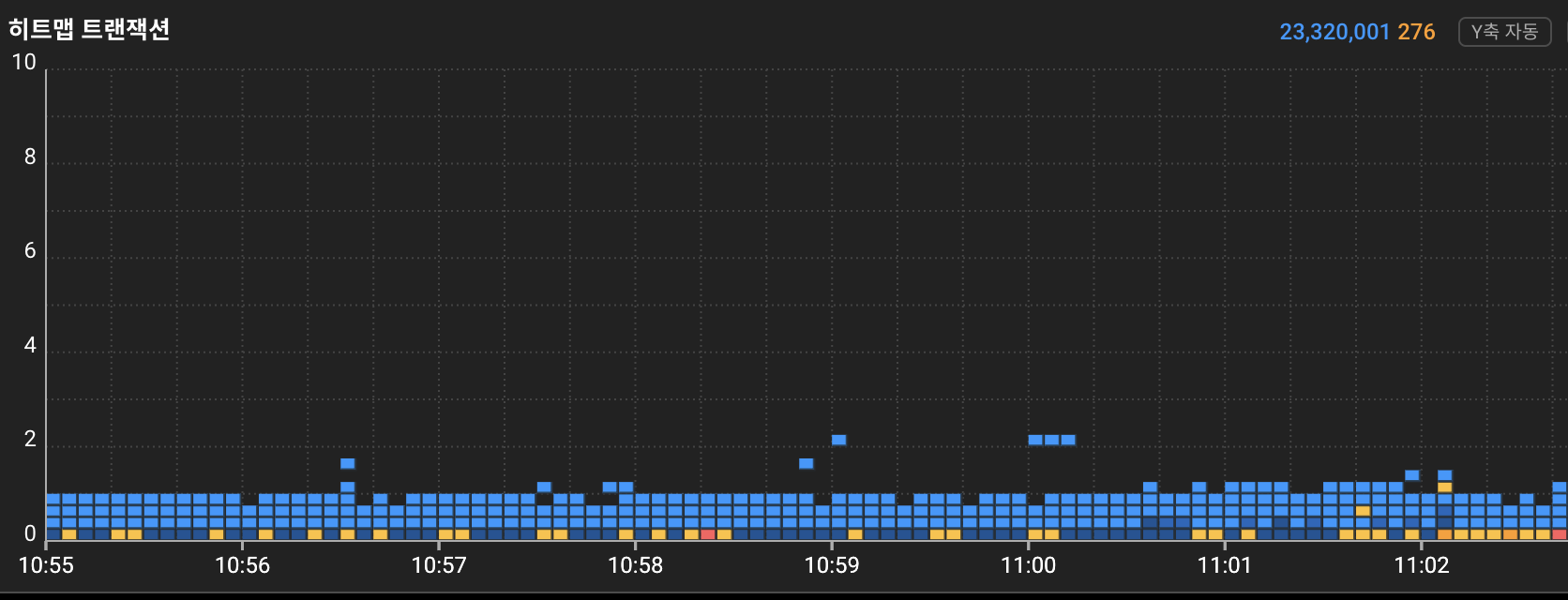
11:00시 TPS 71K Burst Traffic 에서 트랜잭션 히트맵이 양호한 모습
더 이상 버스트 트래픽(TPS: 71K)으로 인한 DB조회 트랜잭션의 실패는 지연으로 이어지지 않았고,
실패한 트랜잭션의 자원은 빠르게 반납하고, 다른 신규 트랜잭션이 더 원활히 동작할 수 있게 되었습니다.
추가로, 재시도 기능을 제거하고 나니 200 에러는 더 명확한 예외(500, DataAccessResourceFailureException) 로 로깅되는 이점도 있었습니다.

대량 조회 분할을 통한 command 부하감소
: DataAccessResourceFailureException의 근본 원인: CPU Load → Latency로 인한 타임아웃
바로 이전 내용 끝에 나와있는 DataAccessResourceFailureException(Timeout while receiving message) 의 발생원인이 궁금합니다.
주요 MongoDB Sharded Cluster 의 지표를 차례대로 보면 아래와 같습니다.
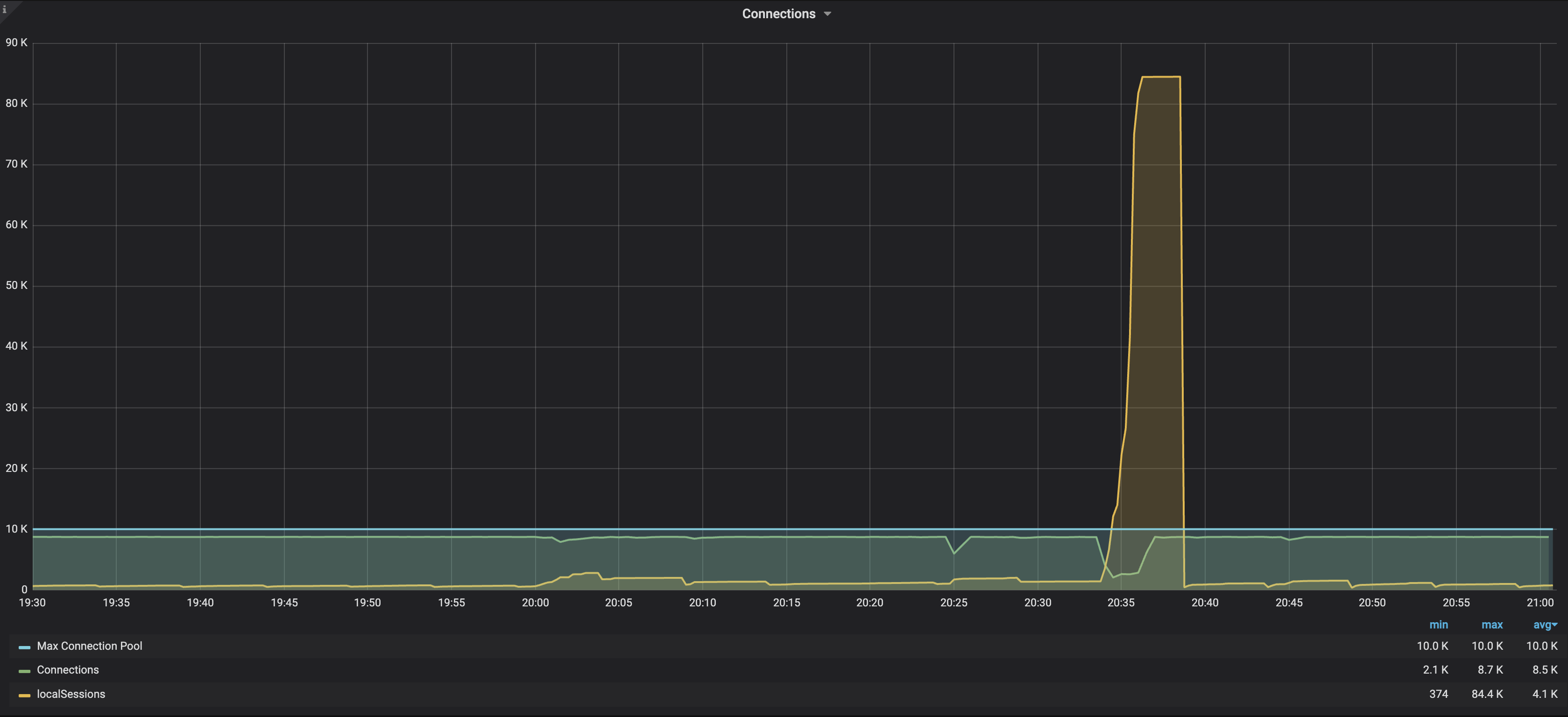
20:35분(버스트 트래픽 발생) 커넥션(초록색)의 상태와 액티브 세션(노란색)의 스파이크 현상을 볼 수 있다

20:35분(버스트 트래픽 발생) command 의 스파이크 현상을 볼 수 있다
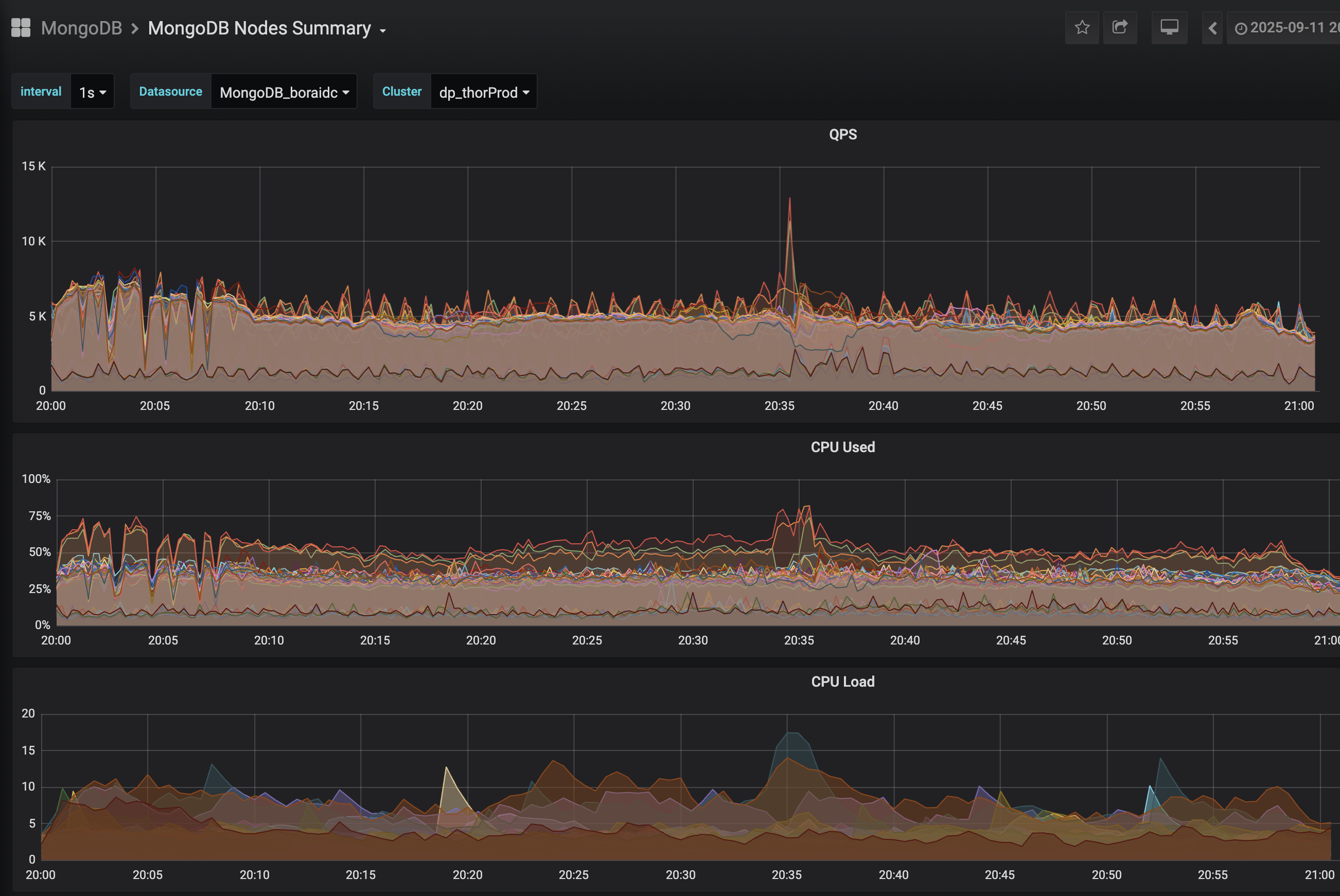
20:35분(버스트 트래픽 발생) QPS(호출수)증가, CPU 사용율과 처리부하가 급증한다
지표들을 살펴보는 과정에서 command 가 유독 눈에 띄게 증가하고 있었다는 점이 분명했습니다.
이 점을 토대로 이슈의 흐름을 정리해 보면,
버스트 트래픽이 발생으로 command의 급증이 MongoDB Server의 CPU 사용률 & CPU Load 증가로 이어지고,
이 CPU 부하는 Latency 증가의 주요 원인이 됩니다.
(또한, CPU가 이미 밀려 들어온 command 들을 처리하느라 포화 상태가 되어, 새로운 요청을 즉시 처리하지 못하고 큐잉됩니다.)
최종적으로, Latency가 일정 수준을 넘어서면 결국 DataAccessResourceFailureException(Timeout while receiving message)로 이어집니다.
질문. command가 CPU 에 부담을 주는 이유?
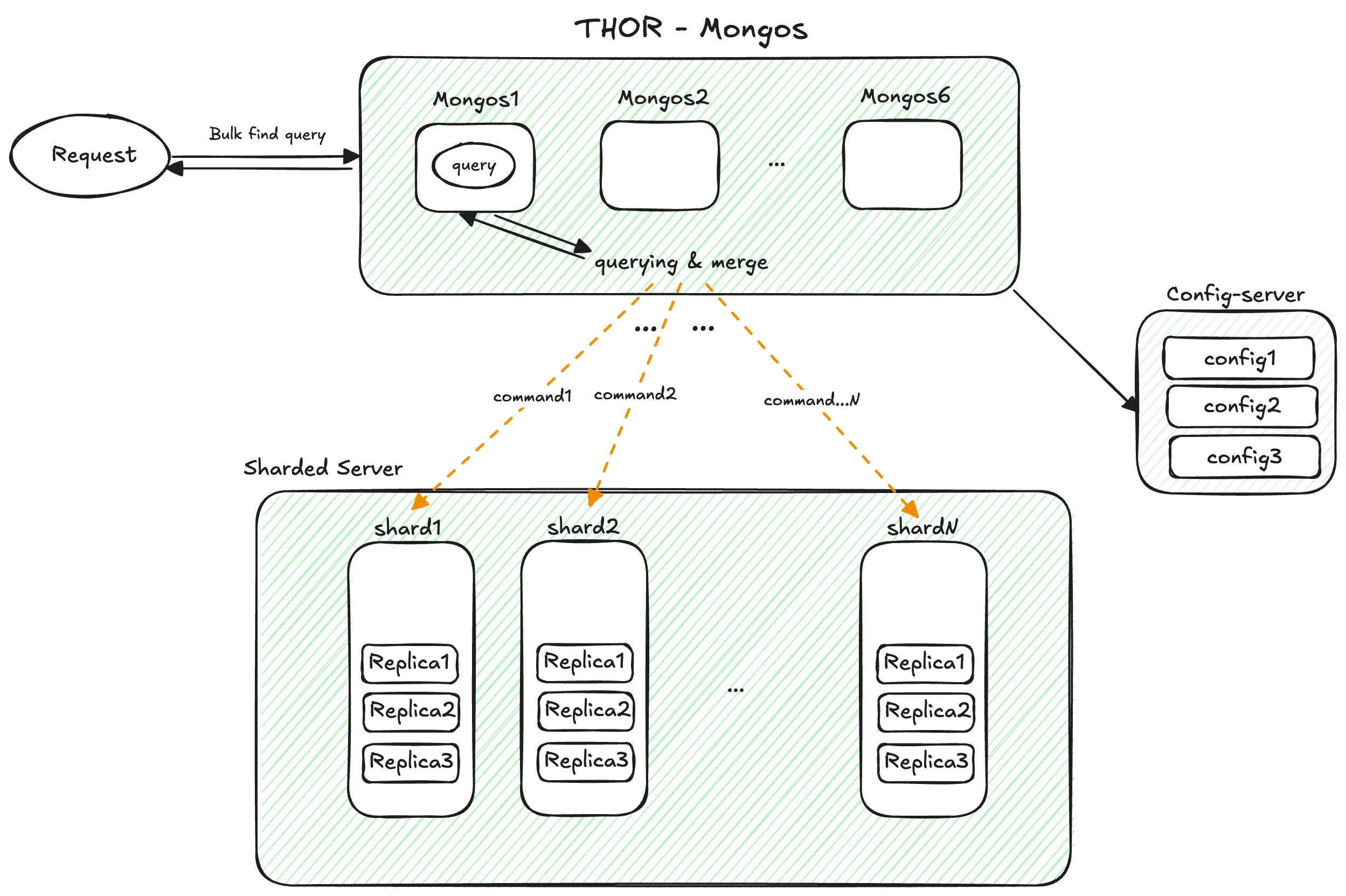
전시 서버에서 상품정보 조회 호출시, Sharded MongoDB Cluster으로 Bulk Find-query가 실행되는 간략한 프로세스를 그림으로 표현
지표에서 나오는 command는 Bulk Find-query를 mongos에서 샤드 별로 n개로 나누어 호출(Fan-out)하는 시스템 내부적인 명령 쿼리입니다.
bulk-query 는 Mongos가 내부적으로 분리된 샤드 수만큼 나눠서
특정 샤드로 다시 querying (command) 하기 때문에, Mongos 입장에서 이러한 형태의 대량조회는 연산과 메모리 부담이 증가됩니다.
특히, 이런 대량조회가 많아지는 버스트 트래픽 상황에서는 이 현상이 뚜렷하게 보입니다.
정리하면, 이번 현상의 절대적인 원인이라고 단정할 수는 없지만 여러 정황상 command Fan-out 증가가 특히 눈에 띄었고,
이를 완화하기 위해 단일 호출 크기를 줄여 command 가 더 작은 단위로 분산 실행되도록 하여 CPU Peak load를 줄이는 작업을 추가했습니다.
3) 서버 리소스 관리와 성능 최적화
앞선 주요 이슈 처리 외에도 메모리 자원의 효율적인 사용과 API 호출을 성능을 정제시키기 위한 최적화 작업들이 있습니다.
로컬 캐시 최대 사이즈 설정
- 기존 로컬 캐시는 별도의 최대 사이즈 제한 없이 운영되고 있었고,
트래픽이 몰릴 때 캐시 오브젝트가 과도하게 증가해 힙 메모리 압박(잠재적 OOM)을 유발할 가능성이 있었습니다.
실제로 일부 서버에서 힙메모리가 비정상적으로 치솟는 현상도 관찰되었습니다. - 캐시 종류별로 크기를 측정해 명확한 상한을 설정함으로써, 메모리 사용량이 예측 가능한 범위 내에서 관리되도록 구조적인 기반이 되도록 했습니다.
즉, 힙 메모리 안정성을 확보하기 위한 방어적인 조치가 되도록 했습니다.
캐시키 정렬 처리
- 캐시키 생성 시 정렬 로직을 추가하여,
Top-Traffic Endpoint API 의 상품번호 파라미터가 입력되는 순서에 따라
캐시 키가 불필요하게 다양해지는 문제를 구조적으로 줄이고자 했습니다. - 동일 요청이지만 순서가 다른 문제를 동일 키로 귀결시키는 기반 로직을 갖추었다는 점에서
장기적으로 캐시 효율성 저하를 유발할 수 있는 측면에서 예방적 효과를 가지도록 했습니다.

대량 데이터 호출 로직 개선
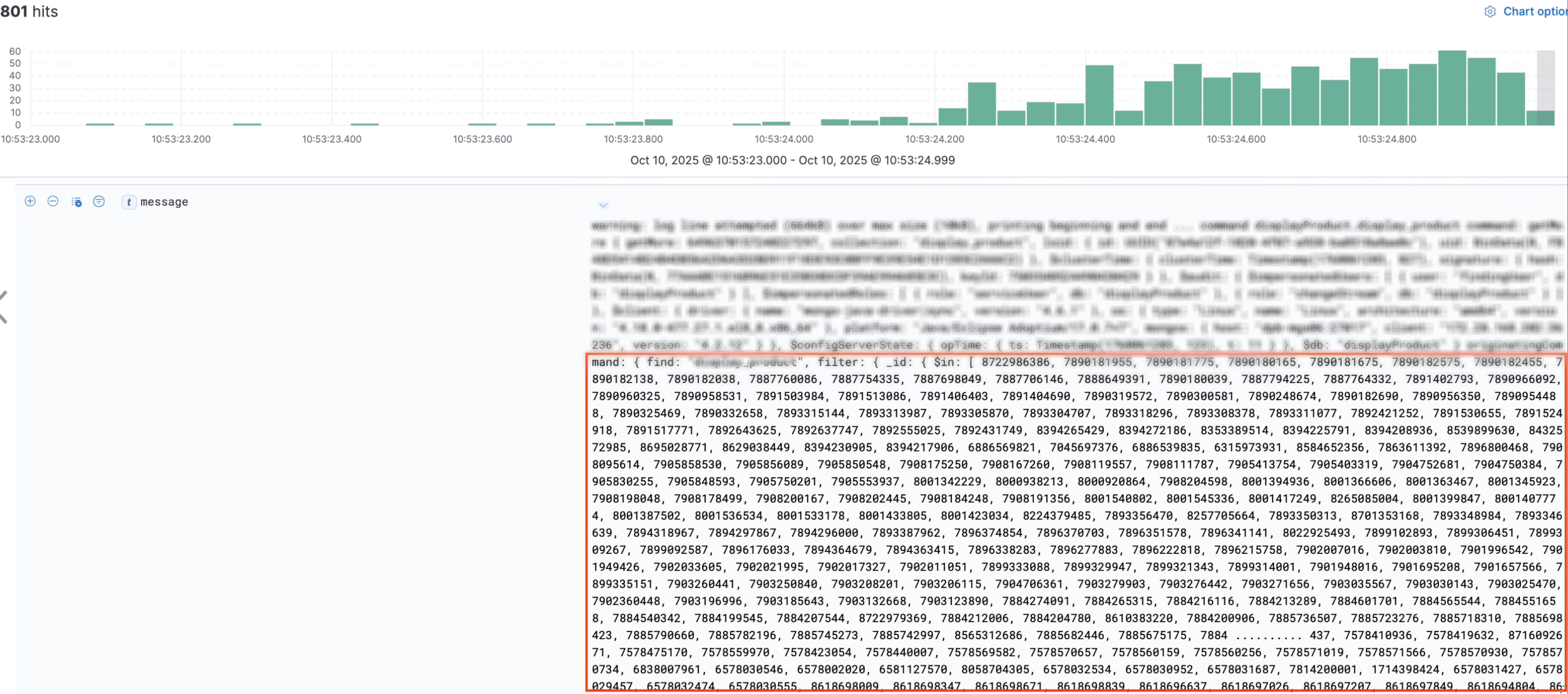
수백건을 한번에 조회하여 발생하는 MongoDB Slow Query 발생 op-log
- Sharded MongoDB Server - Slow Query Log에서,
한 번에 수백 건의 상품을 조회하는 대량 Bulk Find-query가 반복적으로 Slow Query로 기록되는 것을 확인했습니다. - Sharded Cluster 환경에서는 Bulk Find-query의 파라미터 개수가 많아질수록,
이전에 살펴본 command의 CPU·메모리 부하 문제가 더욱 증폭되는 특성이 있습니다. - 이를 완화하기 위해 조회 단위를 적절한 크기로 분할하는 전략을 도입했습니다.
- 물론 대량 조회를 여러 건의 소량 조회로 나누면 네트워크 왕복이 N 번 일어난다는 단점이 있습니다.
그러나 실제로는 일정 크기 이상의 대량 조회가 유발하는 command 급증 문제와 slow query로 인한 CPU 부담 증가가 더 크기 때문에,
100건 이상을 한 번에 조회하는 요청들을 단계적으로 분리·정리하는 방식으로 개선을 진행했습니다.
기타 API 성능 개선
- 트랜잭션 처리 시간이 오래 걸리는 API들을 선별해, 성능 개선 여지가 있는 API들의 쿼리·도메인 로직을 중심으로 최적화를 진행했습니다.
- 사소하지만 누적되면 성능에 영향을 줄 수 있는 각 API의 개별 도메인 로직 보완, 불필요한 연산 제거 등도 함께 수행했습니다.
- 이러한 미세 조정들은 건건이 기록하기는 어렵지만, 전체적인 API 응답 품질을 끌어올리는 데 중요한 역할을 했습니다.
정리: 3가지 핵심 개선포인트
전시 API 서버의 Scale-in 을 위한 현 상황을 점검하고,
Tune Up + Fix in 통한 최적화 여정은 크게 3가지 포인트로 정리해 보면 다음과 같습니다.
- CPU 스파이크 분산
- MongoDB 커넥션 대량 재생성으로 발생하던 주기성 CPU Spike를 인스턴스별 시간 분산 설정으로 안정화
- CPU 사용률의 고점을 낮추고 더 균일하게 유지(CPU Spike 64% 완화)
- 지연 트랜잭션 병목 개선
- 재시도 정책을 조정하여 지연가능성이 높은 단일 트랜잭션의 불필요한 자원 점유 방지
- 커넥션 풀 확충으로 동시 트랜잭션 대기 최소화
- 서버 리소스 관리 개선
- 캐시 및 메모리 안정화 - 캐시 최대 사이즈 설정과 캐시 키 정렬로 힙 메모리 사용량 안정화, GC 효율 개선
- 대량 조회 분할처리 - MongoDB command 부하 분산시켜 CPU Peak Load 완화
- 기타 API 최적화
최종 트래픽 결과
AS-IS ( MAX TPS: 65.9K )

MAX TPS: 65,973
서버 불안정 ⚠️많은 API 응답에서 지연·에러 다수 발생

🚀 TO-BE ( 🔥 MAX TPS: 87.9K )

🔥 MAX TPS: 87,918
서버 안정 ✅
Top Traffic Endpoint 트랜잭션인 v2/products API 기준으로 평균 시간은 23ms, 표준편차 23ms
대부분의 요청에서 사용자가 체감할 수 있는 지연 시간은 거의 없는 수준으로 볼 수 있습니다.

마치며
안정적이고 효율적인 Scale-in이라는 미션을 위해
저희 전시서비스 개발팀과 인프라팀은 꽤 깊은 여정을 함께 했습니다.
서로의 도메인에 대해 “이 현상의 원인이 무엇일까요?”, “이 지표의 근거는 무엇인가요?” 같은 깊이 있는 질문과 논쟁을 주고받으며,
모호했던 기술적 접점(Touchpoints)을 구체적인 지표와 상세한 문답을 통해 명확히 이해하고 정리할 수 있었습니다.
이 과정에서 ‘One-Team’으로서 강력한 시너지를 체감했고,
이는 앞으로 타 도메인 팀과 협업에도 비슷하게 적용할 수 있는 값진 결과물이라고 느꼈습니다.
협업을 진행하면서 기술적 접점에 대한 이해는 명확해졌지만, 근본적인 문제 해결은 또 다른 영역이었습니다.
서버의 이슈나 결과 지표들은 이기종 시스템과 여러 서비스가 얽혀 있어,
원인을 하나로 콕 집어내거나 정답 수치를 계산하기 어려운 미지의 영역이 많았고, 일부 경험이 없던 부분은 어려움도 많았습니다.
이럴 때 조언을 받았던 ‘예상 문제 지점 리스트업 → 순차적 검증 및 소거’ 방식이 효과적이었는데,
덕분에 긴 시간 동안 복합적인 문제를 헷갈리지 않고 전체 이슈의 흐름을 명확하게 잡고 해결해 나갈 수 있었다고 생각합니다.
때로는 문제 정의가 완료된 후 AI를 활용해 구체적인 해결책을 구상하고 이를 검증해나가는 방식이 매우 효율적이라는 점도 경험해 볼 수 있었습니다.
이번 Scale-in 최적화 여정은 단순히 서버 비용을 줄이는 작업을 넘어, 시스템의 깊은 동작 원리를 짚어보고 다시 이해하는 계기가 되었습니다.
원인을 알 수 없는 지표들을 보며 막막하기도 했지만, “왜?” 라는 질문을 던지며 모호한 지표들을 하나씩 검증해 나갔고,
덕분에 1차원적인 현상 뒤에 숨겨진 진짜 원인(Root Cause)을 찾아낼 수 있었고,
그랜드십일절 전시서비스는 Burst Traffic TPS 87.9K 에서도 안정적으로 서버를 운영할 수 있었습니다.
앞으로도 이러한 시스템을 깊이 있게 이해하려는 집요한 태도가, 안정적인 서비스 운영의 가장 단단한 기반이 될 것이라 믿습니다.
"이해하려는 욕구가 없다면, 아무것도 보이지 않는다." - 듄(Dune)
감사합니다.