Service Discovery DR 구성 2부 - Chaos Test로 찾은 예기치 못했던 문제를 고쳐라!
spring , cloud , kubernetes , eureka , msa , service-discovery , chaos-test
안녕하세요. 11번가 Core플랫폼개발팀에서 MSA 플랫폼 Vine의 개발과 운영을 담당하고 있는 전지원입니다.
이번 Article에서는 Spring Cloud의 Service Discovery 컴포넌트인 Eureka 의 Disaster Recovery를 구성하는 과정에서 겪었던 이슈에 대해서 소개하고, 이를 발견하게 된 계기와 문제를 해결한 과정에 대해서 설명드리고자 합니다.
본 Article은 Service Discovery DR 구성 1부 - Eureka 서버를 지역 분산시켜 안정성을 높이자의 후속 게시물입니다. 해당 Article의 Context 를 더욱 쉽게 이해하시기 위해서 사전에 1부 게시물을 확인하시는 것을 권장드립니다.
Background
11번가는 서비스의 높은 확장성과 간단한 통합 및 배포, 그리고 운영을 위해 2016년 거대한 Monolithic 서비스를 Microservice Architecture로 전환하는 프로젝트를 진행하였으며, 그 결과 Spring Cloud 기반의 Vine 플랫폼이 개발되어 현재 약 600여 개 인스턴스와 60여 개의 애플리케이션 서비스가 Vine 플랫폼 위에서 성공적으로 운영되고 있습니다.
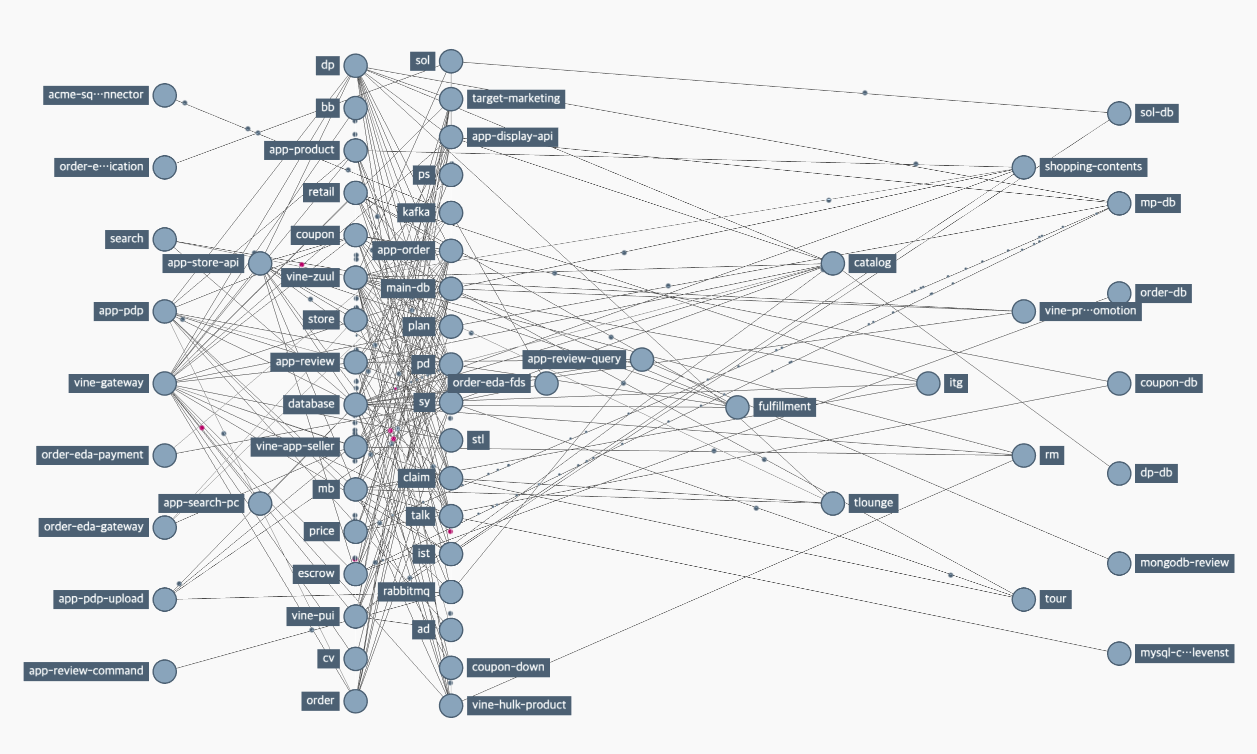
생성과 소멸을 반복하는 마이크로서비스가 서로를 인식하고 통신할 수 있도록, 인스턴스 자신의 동적으로 변화하는 주소를 등록하고 다른 인스턴스 정보를 검색할 수 있는 레지스트리가 필요한데, MSA 플랫폼 컴포넌트인 Service Discovery가 해당 역할을 담당하고 있습니다.
Spring Cloud ecosystem에서는 Netflix OSS 인 Eureka를 Service Discovery로 제공하고 있습니다. 11번가는 IDC 내에 Eureka 서버를 Peering하여 구축해두었고, 각 애플리케이션에 포함된 Eureka Client가 서버 Peer와의 통신을 통해서 개별 인스턴스 정보를 받아와 통신하는 과정을 거치게 됩니다.
Disaster Recovery
11번가는 Vine 플랫폼의 유연함과 확장성을 증대하기 위해서 AWS를 도입하여 IDC와 Cloud 리소스를 함께 사용하는 Hybrid Cloud 형태로의 고도화를 진행하고 있습니다.
기존 IDC에서만 운영되고 있던 마이크로서비스들이 AWS EKS에도 인스턴스가 새롭게 추가됨에 따라서 11번가는 eurekube-operator 를 개발하여 Client-Side Service Discovery인 Eureka와 Kubernetes의 Server-side Service Discovery를 통합하고 있습니다.
eurekube-operator의 Service Discovery 통합과 관련한 내용은 다음 Article을 참조해주세요.
이에 더해 IDC에서 동작하는 서비스 클라이언트가 Zone Fail로 인해서 IDC Service Registry에 접근하지 못하는 상황에 대응하기 위해, EKS에 신규 Zone을 개설하고 Eureka Server 인스턴스를 추가로 생성하여 IDC 서버 인스턴스와 Replication 구성될 수 있도록 하였습니다.
실제 장애 상황에서 의도대로 동작해야만한다 - Chaos Engineering (Chaos Test)
chaos ([ˈkeɪɑːs] / [ˈkeɪɒs])
[명사] 혼돈, 혼란
Disaster Recovery를 구성했다면, 실제로 장애 상황이 발생했을 때 의도한 바대로 장애 대처를 시스템이 해낼 수 있는지 검증하는 작업이 요구될 것입니다. 이를 위해서 11번가는 Chaos Enginnering을 도입했습니다.
단어에서 알 수 있듯 Chaos Engineering (혹은 Chaos Test)은, 특정 애플리케이션 혹은 시스템에 예측 불가한 Chaos (혼란) 을 의도적으로 주입해 시스템이 비정상적 조건에서 어떠한 행위를 수행하는지 확인하는 행위를 의미합니다. 예측 불가능했던 상황에서 시스템이 어떻게 행동하는지 확인하고, 이를 견뎌낼 수 있도록 추가적인 시스템을 변경하는 작업인만큼 특정 Input이 입력되었을 때의 output을 기대하는 코드 Test와는 차이가 있습니다.
어떤 상황이 발생할 수 있을까요?
- 서버로의 연결 실패 (Failed Requests)
- 서버로의 연결 무한 대기 (High Network Latency)
Cloud 환경에서의 Chaos Test
EKS에 배포되어 있는 Eureka에 Network Chaos를 주입하기 위해 Cloud 환경에 최적화된 Chaos Engineering Tool인 chaos-mesh 를 사용했습니다.
Chaos Mesh는 CNCF (* Cloud Native Computing Foundation)의 Incubating Project로, Chaos Engineering Tool로서는 가장 범용적으로 활용되고 있는 도구 중 하나입니다.
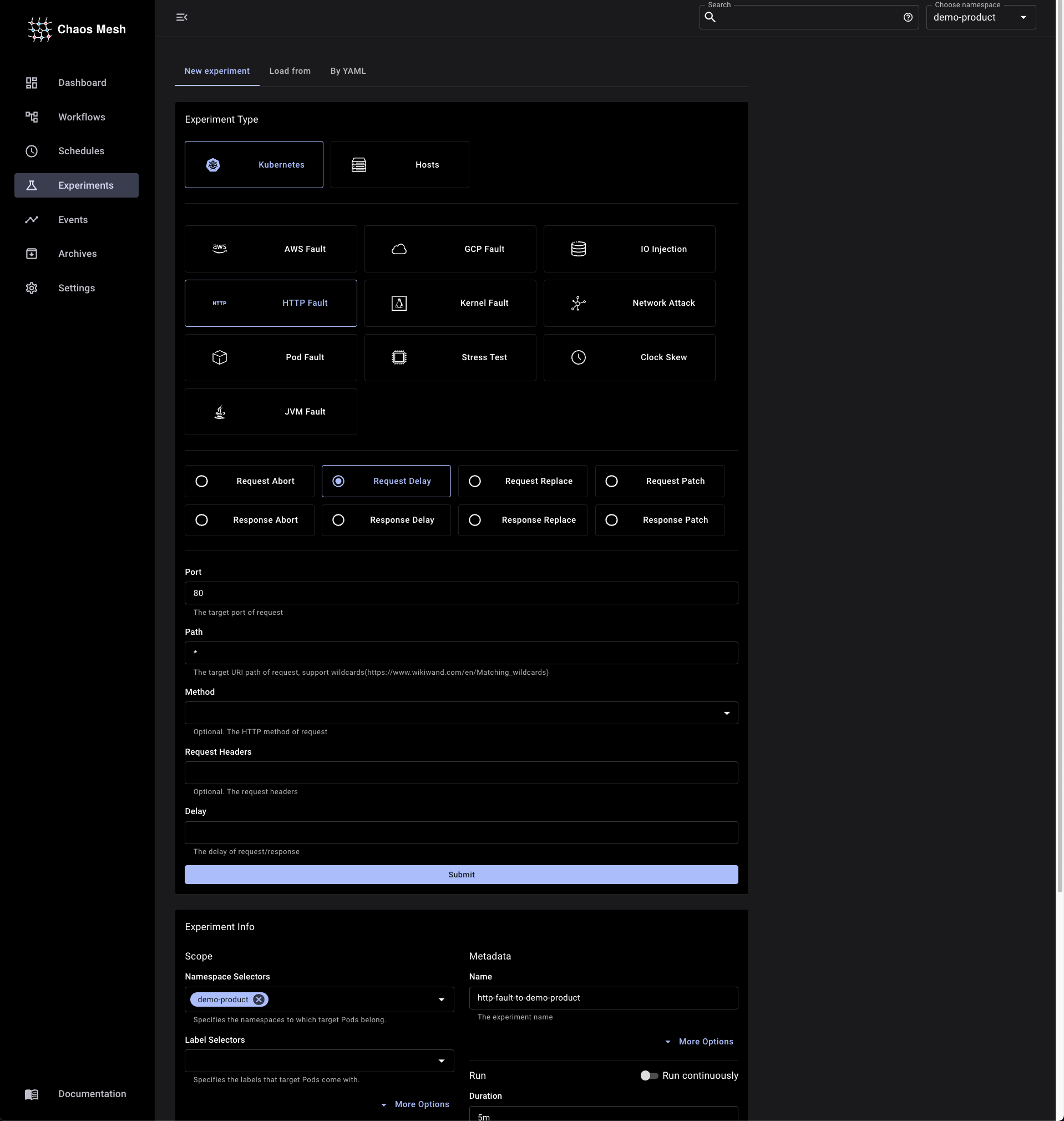
Chaos Test에서는 특정 Zone에 위치한 Eureka Server 인스턴스에 장애가 발생했을 때 다른 Zone으로 Switching 되어야 하는 것이 목표입니다. 따라서 위에서 언급했던 발생할 수 있는 상황에 맞는 Chaos를 주입하여 검증을 할 것입니다.
PodChaos (Pod Fault), HTTPChaos (HTTP Fault)를 주입해 각 Chaos가 발생했을 때 Zone Failover가 이루어지는지 확인해보면 됩니다. 클라이언트와 서버가 HTTP 통신을 하는 만큼 네트워크 패킷 스니퍼인 Wireshark로 그 과정을 확인해보도록 하겠습니다.

위 첨부 이미지는 PodChaos를 주입했을 때의 서비스 클라이언트에서 Eureka Server로의 네트워크 패킷 흐름을 보여주고 있습니다. 10.X 의 IP 대역은 EKS의 IP 대역이며 172.X 의 IP 대역은 IDC의 IP 대역입니다. 모든 서버 Pod가 죽으면 서비스 클라이언트는 서버에서 Response를 받을 수 없어 502 Response Code를 수신받게 되고 다른 피어로 재차 재시도를 진행합니다. 모든 피어가 실패되면 참조가 IDC로 이동되는 것을 확인할 수 있습니다.
특정 시간이 지나고 EKS의 서버 Pod가 복구되면 어떻게 될까요? 새로운 세션이 수립되면서 EKS 서버 Pod에 재시도를 진행하게 되는데요. 이 때 404 Response Code가 반환되면 복구가 되었음을 확인할 수 있고 이 때 서비스 클라이언트 자신을 Register 하기 위한 시도를 진행하면서 EKS 서버로의 참조가 복구됨을 알 수 있습니다.
IDC에서의 Chaos Test
Cloud 환경에서의 Chaos Test와 마찬가지로 IDC 위에서 동작하는 Eureka Client도 동일하게 동작이 되어야할 것입니다. IDC에서의 Chaos Test는 ToxiProxy를 사용하여 Network 장애를 주입하고 테스트를 진행해보았습니다.
ToxiProxy는 Shopify에서 개발한 Chaos Test Tool로서, Latency / Server Down / Bandwidth / Slow close / Timeout / Slicer와 같은 발생 가능한 다양한 네트워크 Fault를 제공합니다. Go로 작성된 Proxy 서버가 종단 간 사이에 위치에 네트워크 Fault를 제어합니다.
docker-compose.yml
version: "3.9"
services:
dev-idc-01:
image: [EUREKA-SERVER]
environment:
spring.config.additional-location: file:/
eureka.instance.hostname: dev-idc-01
eureka.client.availability-zones: dev-idc,dev-eks
eureka.client.transport.retryable-client-quarantine-refresh-percentage: 0.6
ports:
- "8761:8761"
volumes:
- ./application.yml:/application.yml
dev-idc-02:
image: [EUREKA-SERVER]
environment:
spring.config.additional-location: file:/
eureka.instance.hostname: dev-idc-02
eureka.client.availability-zones: dev-idc,dev-eks
eureka.client.transport.retryable-client-quarantine-refresh-percentage: 0.6
ports:
- "8762:8761"
volumes:
- ./application.yml:/application.yml
dev-eks-01:
image: [EUREKA-SERVER]
environment:
spring.config.additional-location: file:/
eureka.instance.hostname: dev-eks-01
eureka.client.availability-zones: dev-eks,dev-idc
eureka.client.transport.retryable-client-quarantine-refresh-percentage: 0.6
ports:
- "8763:8761"
volumes:
- ./application.yml:/application.yml
dev-eks-02:
image: [EUREKA-SERVER]
environment:
spring.config.additional-location: file:/
eureka.instance.hostname: dev-eks-02
eureka.client.availability-zones: dev-eks,dev-idc
eureka.client.transport.retryable-client-quarantine-refresh-percentage: 0.6
ports:
- "8764:8761"
volumes:
- ./application.yml:/application.yml
toxiproxy:
image: ghcr.io/shopify/toxiproxy
ports:
- "8474:8474" # ToxiProxy Client
- "18761:18761" # Eureka Server Proxy (IDC 01)
- "18762:18762" # Eureka Server Proxy (IDC 02)
- "18763:18763" # Eureka Server Proxy (EKS 01)
- "18764:18764" # Eureka Server Proxy (EKS 02)
CLI
# Add Proxy
$ toxiproxy-cli create --listen 0.0.0.0:18761 --upstream dev-idc-01:8761 dev-idc-01
$ toxiproxy-cli create --listen 0.0.0.0:18762 --upstream dev-idc-02:8761 dev-idc-02
$ toxiproxy-cli create --listen 0.0.0.0:18763 --upstream dev-eks-01:8761 dev-eks-01
$ toxiproxy-cli create --listen 0.0.0.0:18764 --upstream dev-eks-02:8761 dev-eks-02
# List Proxies
$ toxiproxy-cli list
# Add Toxic
$ toxiproxy-cli toxic add -t latency -a latency=1000000 dev-eks-01 && toxiproxy-cli toxic add -t latency -a latency=1000000 dev-eks-02
# Remove Toxic
$ toxiproxy-cli toxic add -t latency -a latency=1000000 dev-eks-01 && toxiproxy-cli toxic add -t latency -a latency=1000000 dev-eks-02
RestTemplate 객체 생성과 관련하여 다음 Article 의
RestTemplate항목을 참조해주세요.
또 다른 Chaos Test 사례가 궁금하시다면 다음 Article을 참조해주세요.
이 에러는 뭐지?
Chaos Test 결과로 High Network Latency (Request Delay) 가 주입되었을 때 Zone Failover가 발생하고 있지 않는 문제를 발견할 수 있었습니다. 무엇이 원인일까요? Eureka Client 내부 구현을 살펴보겠습니다.
DiscoveryClient 에서 default 30s interval로 클라이언트가 서버에게 자신이 Alive하다는 것을 알리는 Heartbeat (renew) 를 전달합니다. 그리고 주기적으로 클라이언트가 캐시로 가지고 있던 전체 레지스트리 정보를 갱신하기 위해서 CacheRefresh를 수행합니다.
그런데, Network Latency가 증가한 상황에서 request를 보냈을 때 응답을 무한하게 대기하는 현상이 나타났습니다.
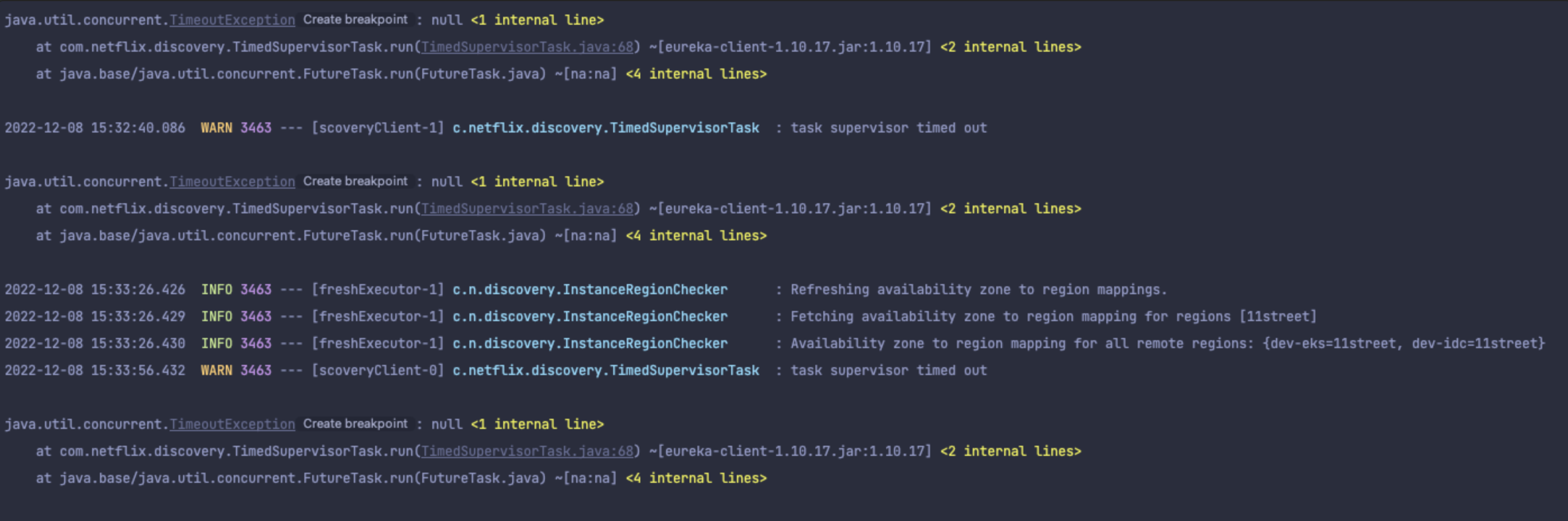
이렇게 될 경우 서비스 클라이언트는 로컬에 캐시하고 있는 인스턴스 정보로만 통신할 수밖에 없는 상황이 발생하는데, 이 때 다른 마이크로서비스 인스턴스의 정보가 변경되고 있었다면 정상적인 통신이 불가능할 가능성이 발생할 수 있습니다.
Spring Cloud Netflix에서 Default TransportClient로 사용하는 Apache HttpClient의 Config를 살펴보겠습니다.
// org.apache.http.client.config.RequestConfig
public class RequestConfig {
...
public static class Builder {
...
Builder() {
...
this.connectionRequestTimeout = -1;
this.connectTimeout = -1;
this.socketTimeout = -1;
...
}
...
}
...
}
모든 timeout 관련 값이 -1 로 설정되어 있습니다. 여기서 -1 이라는 값은 무한함 (infinite)을 의미하기 때문에, 특정 서버에 대해서 연결이 지연되더라도 무한히 대기하고 있음을 알 수 있습니다.
Spring Cloud Netflix에는 해당 값을 지정할 수 있는 Property가 없습니다. 따라서 문제 해결을 위해서 Default Timeout을 지정할 수 있는 추가적인 구현이 요구되는 상황입니다.
에러를 수정하자!
해당 에러를 수정하기 위해서는 기존 Bean을 Override하는 Custom Bean을 생성하거나, 혹은 Spring Cloud Netflix에 해당 에러를 수정하여 반영하는 방법을 선택해야 했습니다. 발견한 에러 Fix를 Eureka를 사용하는 전세계 모든 개발자들과 공유하기 위해서 적극적인 리포팅 및 Contribution을 하는 것이 좋겠다고 판단하여 오픈소스 컨트리뷰션을 결정하였습니다.
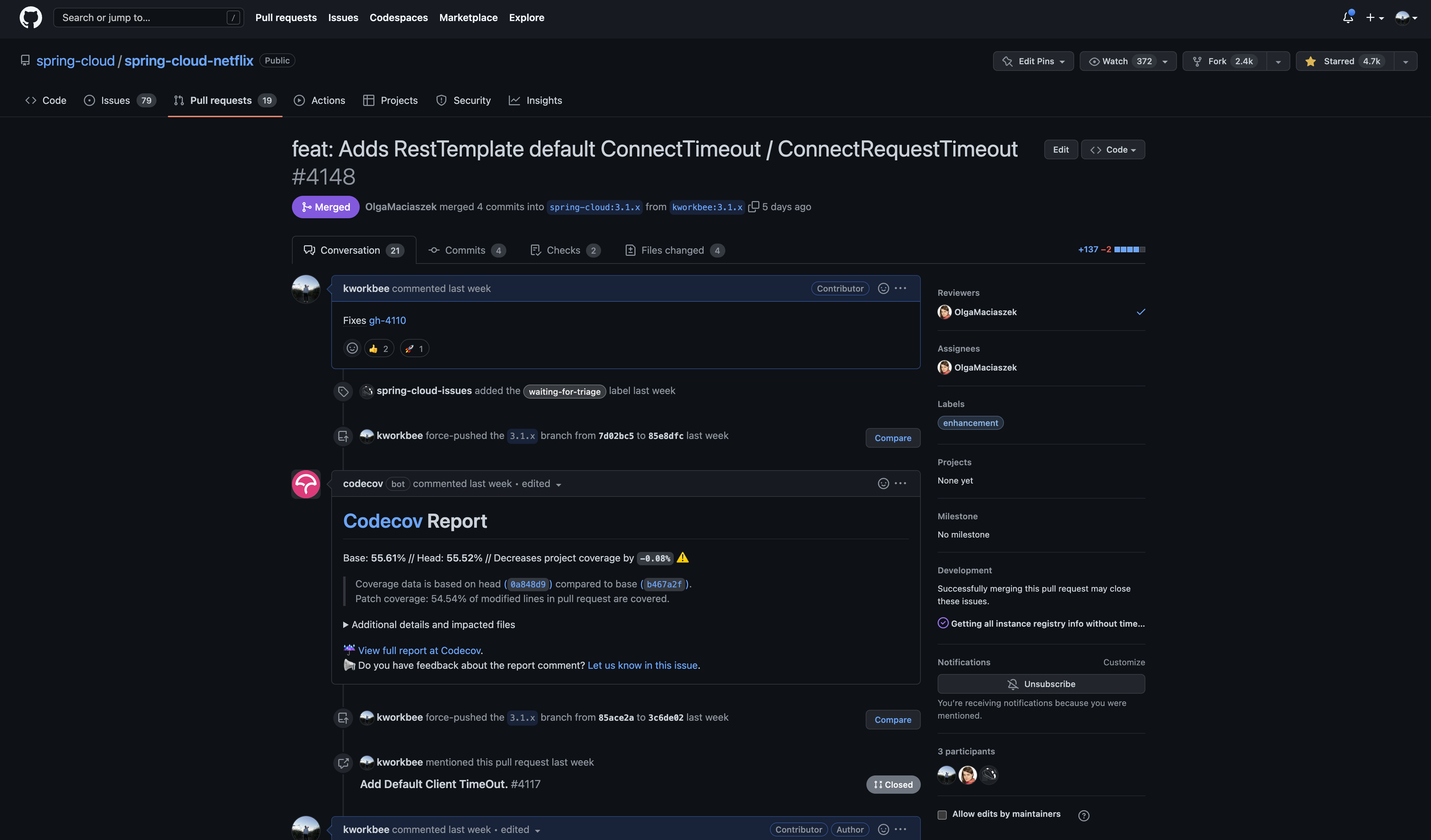
public class DefaultEurekaClientHttpRequestFactorySupplier implements EurekaClientHttpRequestFactorySupplier {
private final RestTemplateTimeoutProperties restTemplateTimeoutProperties;
public DefaultEurekaClientHttpRequestFactorySupplier() {
this.restTemplateTimeoutProperties = new RestTemplateTimeoutProperties();
}
public DefaultEurekaClientHttpRequestFactorySupplier(RestTemplateTimeoutProperties restTemplateTimeoutProperties) {
this.restTemplateTimeoutProperties = restTemplateTimeoutProperties;
}
@Override
public ClientHttpRequestFactory get(SSLContext sslContext, @Nullable HostnameVerifier hostnameVerifier) {
HttpClientBuilder httpClientBuilder = HttpClients.custom();
if (sslContext != null) {
httpClientBuilder = httpClientBuilder.setSSLContext(sslContext);
}
if (hostnameVerifier != null) {
httpClientBuilder = httpClientBuilder.setSSLHostnameVerifier(hostnameVerifier);
}
if (restTemplateTimeoutProperties != null) {
httpClientBuilder.setDefaultRequestConfig(buildRequestConfig());
}
CloseableHttpClient httpClient = httpClientBuilder.build();
HttpComponentsClientHttpRequestFactory requestFactory = new HttpComponentsClientHttpRequestFactory();
requestFactory.setHttpClient(httpClient);
return requestFactory;
}
private RequestConfig buildRequestConfig() {
return RequestConfig.custom().setConnectTimeout(restTemplateTimeoutProperties.getConnectTimeout())
.setConnectionRequestTimeout(restTemplateTimeoutProperties.getConnectRequestTimeout())
.setSocketTimeout(restTemplateTimeoutProperties.getSocketTimeout()).build();
}
}
다음과 같이 기존 DefaultEurekaClientHttpRequestFactorySupplier 클래스에서 HttpClientBuilder에 Timeout 관련 설정이 지정된 RequestConfig 객체를 설정하면 Property를 통해서 특정 시간 안에 fast-fail 할 수 있도록 구현을 변경할 수 있습니다.
Merge된 Issue는 12월 새롭게 릴리즈된 Spring Cloud 2022.0.0 에 반영되었습니다.
eureka:
client:
# RestTemplate의 Timeout 관련 설정
rest-template-timeout:
connect-timeout: 5000
connect-request-timeout: 5000
socket-timeout: 5000
클라이언트가 포함된 프로젝트를 신규 버전으로 업그레이드하여, 다시 의도대로 장애 상황에서 대응을 잘하는지 검증해보았습니다.
다행히 클라이언트는 Network Latency가 증가하는 상황에서 지정한 Timeout이 지나면 연결 실패로 간주하고 다른 서버로 Heartbeat를 정상적으로 보내는 것을 확인할 수 있었습니다.
Spring Cloud 버전 Up이 어려운 경우 Custom한
EurekaClientHttpRequestFactorySupplierBean을 생성하여 해결 가능합니다. 관련 코드
Conclusion
지금까지 Service Discovery 컴포넌트의 Disaster Recovery 구성을 진행하는 과정 중 발생 가능한 장애 상황에서 의도된 동작이 이루어지는지 검증하고, 동작하지 않았을 때의 원인 그리고 대처가 어떻게 이루어졌는지 설명드렸습니다.
11번가는 견고하고 안정화된 시스템을 개발 / 운영하기 위한 다양한 방법을 시도하고 도입하고 있으며, Chaos Engineering도 이러한 방법 중 하나로 활용되고 있습니다.
본 Article과 관련한 피드백을 언제나 환영합니다! 이상으로 Article을 마치도록 하겠습니다. 감사합니다 :)