Service Discovery DR 구성 3부 - eurekube-operator의 Zone Failover를 위한 Spring Cloud LoadBalancer 탐구
spring , cloud , kubernetes , eureka , msa , service-discovery , load-balancer
안녕하세요. 11번가 Core플랫폼개발팀에서 MSA 플랫폼 Vine의 개발과 운영을 담당하고 있는 전지원입니다.
이번 Article에서는 Eureka 서버의 Multi-Zone 구성을 함에 따라 기존에 11번가 내에서 IDC의 Client-side Service Discovery와 EKS 클러스터의 Server-side Service Discovery 통합을 담당하던 Kubernetes Operator인 eurekube-operator 의 구현을 변경한 내용에 대해서 공유드리고자 합니다.
본 Article은 Service Discovery DR 구성 1부 - Eureka 서버를 지역 분산시켜 안정성을 높이자 와, Service Discovery DR 구성 2부 - Chaos Test로 찾은 예기치 못했던 문제를 고쳐라! 의 후속 게시물입니다. 해당 Article의 Context 를 더욱 쉽게 이해하시기 위해서 사전에 해당 게시물을 확인하시는 것을 권장드립니다.
Background
What is Vine Platform?
11번가는 서비스의 높은 확장성과 간단한 통합 및 배포, 그리고 운영을 위해 2016년 거대한 Monolithic 서비스를 Microservice Architecture로 전환하는 프로젝트를 진행하였으며, 그 결과 Spring Cloud 기반의 Vine 플랫폼이 개발되어 현재 약 720여개 인스턴스와 70여개의 애플리케이션 서비스가 Vine 플랫폼 위에서 성공적으로 운영되고 있습니다.
더 나아가 Vine 플랫폼은 유연함과 확장성 증대를 위해서 AWS를 도입하여 IDC와 Cloud 리소스를 함께 사용하는 Hybrid Cloud 형태로의 고도화가 이루어지고 있습니다.
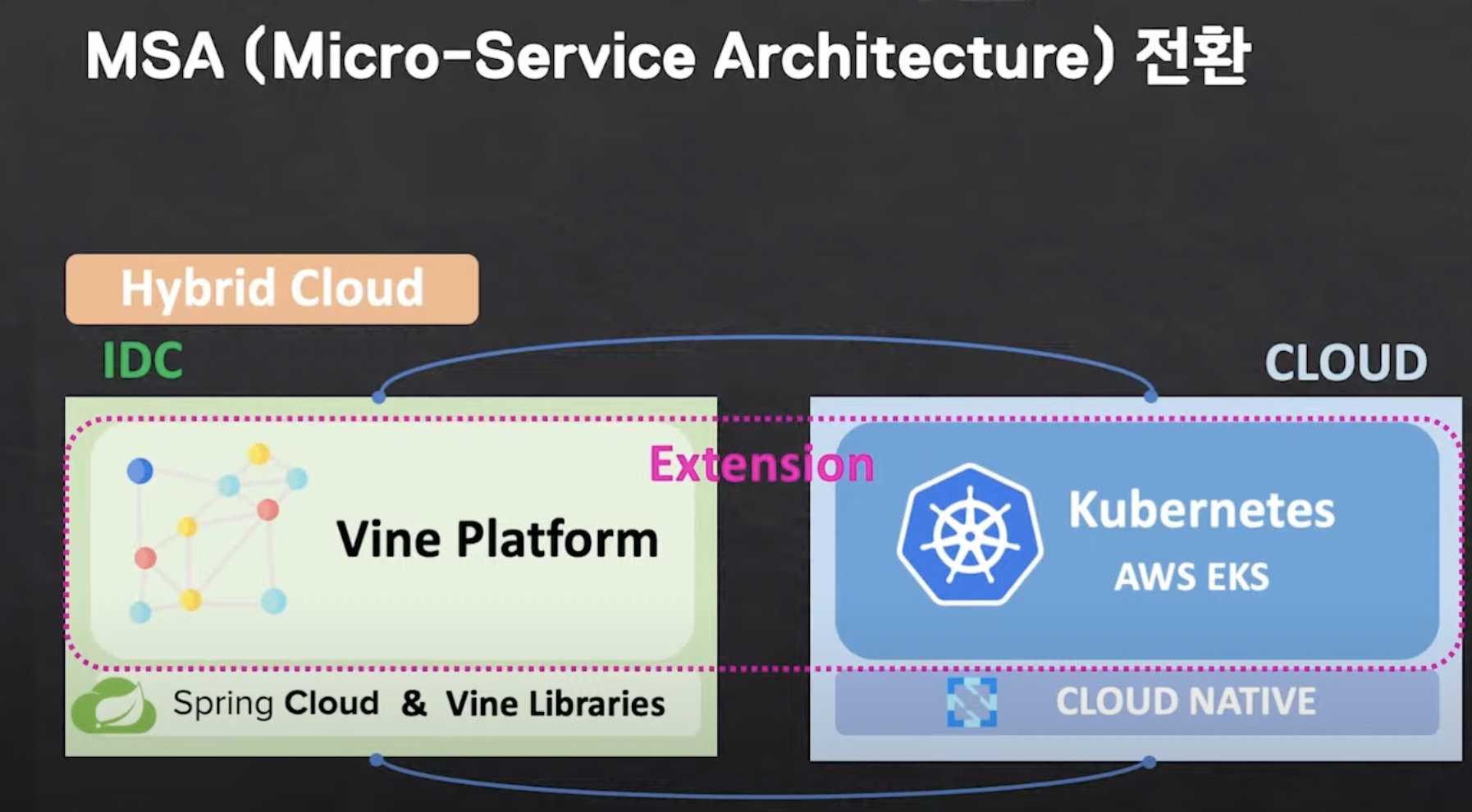
eurekube-operator
eurekube-operator는 IDC의 Client-side Service Discovery와 EKS 클러스터의 Server-side Service Discovery를 통합하기 위해 구현한 Kubernetes Operator입니다. eurekube-operator가 개발됨에 따라 서로 다른 곳에 위치한 마이크로서비스 간의 호출에 있어서 장소 투명성 유지의 목적을 달성할 수 있었습니다.
eurekube-operator의 자세한 내용에 대해서는 지난 게시물을 참고해주세요.
지난 1, 2부에서는 IDC Zone에서 Eureka Server가 정상적으로 운영되지 못하는 상황에 대비하기 위해 EKS에 추가 Zone을 개설해 Eureka Server를 복제하는 것과 관련한 내용을 설명드렸는데요. 이렇게 구성된 Eureka Server 피어들이 무중단 운영이 가능하도록 하기 위해서는 추가적인 전제가 뒷받침되어야 합니다. eurekube-operator 에 대한 추가적인 Zone Failover 구현이 이루어져야 합니다.
이 구현이 이루어지지 않으면 특정 Zone의 Eureka Server가 정상적으로 동작하지 않는 동안 동일 Zone 내 인스턴스의 정보가 Sync되지 못해 다른 Zone의 서비스 클라이언트가 참조하려는 서비스 클라이언트의 정보를 정상적으로 쿼리하지 못하는 문제가 발생할 수 있습니다.
이에 기존에 IDC Eureka Server를 바라보던 eurekube-operator는 EKS Eureka Server를 바라보도록 우선 참조 Zone을 변경하고, EKS 내 Eureka Server Pods이 Killed되거나 High Network Latency로 정상적인 동작이 되지 않을 때 IDC로 그 참조를 변경하도록 구현하여 특정 Zone의 Eureka Server가 정상 동작하지 않더라도 다른 Zone에 인스턴스 정보 Sync를 진행할 수 있도록 해야 합니다.
IDC와 EKS Eureka Server 간에 Replication 구성이 되어 있어, EKS Eureka Server로 서비스 클라이언트를 register하게 되면 IDC Eureka Server에도 해당 인스턴스 정보가 복제됩니다. 우선 참조 대상을 변경하게 될 경우 Network Hop이 줄어들기 때문에 IDC 로 Request를 보내는 것보다 비용이 저렴해집니다.
Request를 보내기 위한 Eureka 서버 인스턴스를 선택하는 방법
eurekube-operator는 fabric8의 java based K8s Client 를 이용하여 EurekaSyncer CR이 활성화되어 있는 K8s 서비스 클라이언트의 Endpoint 정보를 가져와 Eureka Server에 register / sendHeartbeat / unregister 를 수행합니다.
Request를 위해 Spring WebClient Bean을 사용하고 있으며, Spring Cloud LoadBalancer의 ReactorLoadBalancerExchangeFilterFunction을 사용해 IDC 내 Eureka Server Instance를 임의로 선택하는 Load Balancer support를 추가해두었습니다.
Spring Cloud LoadBalancer는 Spring Cloud Commons 프로젝트의 일부로, 아키텍처는 Netflix Ribbon과 동일하게 대상 서버의 리스트를 얻어 Load Balancing 정책에 따라 연결할 대상 애플리케이션 인스턴스를 결정하는 방식입니다. 이를 통해 각 Eureka 서버에 적절한 부하 분산을 하여 서비스 가용성을 최대화 할 수 있습니다. Netflix Ribbon이 Blocking 방식의 HttpClient인 RestTemplate만 지원하는 반면 Spring Cloud LoadBalancer는 RestTemplate 뿐만 아니라 Non-Blocking 방식의 Spring WebClient 또한 지원하고 있습니다.
eurekube-operator의 Zone Failover 구현
eurekube-operator에 새롭게 요구되는 Zone Failover를 달성하기 위해서는 다음과 같은 작업을 진행해야 합니다.
먼저 단일 Zone인 IDC 인스턴스 외에 추가 Zone (EKS)를 선언하고, 추가된 Zone을 우선 참조하도록 변경해야 합니다. 이를 위해서는 기존 Property (spring.cloud.discovery.simple.instances) 외에 선호 Zone과 관련된 추가 Property를 입력받는 추가 구현이 필요합니다.
AS-IS:
spring:
cloud:
discovery:
simple:
instances:
[serviceId]:
- host: IDCEureka01
port: 8761
- host: IDCEureka02
port: 8761
TO-BE:
eurekube:
zone-failover:
# 우선 참조 Zone
preferred-zone: eks
# 연결 실패한 인스턴스를 캐시에 기록, 특정 주기로 만료시켜 특정 인스턴스에 sticking 방지
cache:
ttl: 20m
webclient:
timeout:
# High network latency에 fast-fail 위한 설정
connect-timeout: 5000
read-timeout: 5000
spring:
cloud:
loadbalancer:
retry:
enabled: true
cache:
enabled: false
discovery:
simple:
instances:
[serviceId]:
- host: IDCEureka01
port: 8761
# Zone 정보
metadata:
zone: idc
- host: IDCEureka02
port: 8761
# Zone 정보
metadata:
zone: idc
- host: EKSEureka01
port: 8761
# Zone 정보
metadata:
zone: eks
- host: EKSEureka02
port: 8761
# Zone 정보
metadata:
zone: eks
또한, EKS Zone 내 Eureka Server에 접근 불가능한 경우 Zone-Failover 가 가능하도록 Spring Cloud LoadBalancer 기능을 확장하는 추가 구현이 필요합니다.
이와 관련하여 관련된 클래스에 대해 간단하게 설명드리겠습니다.
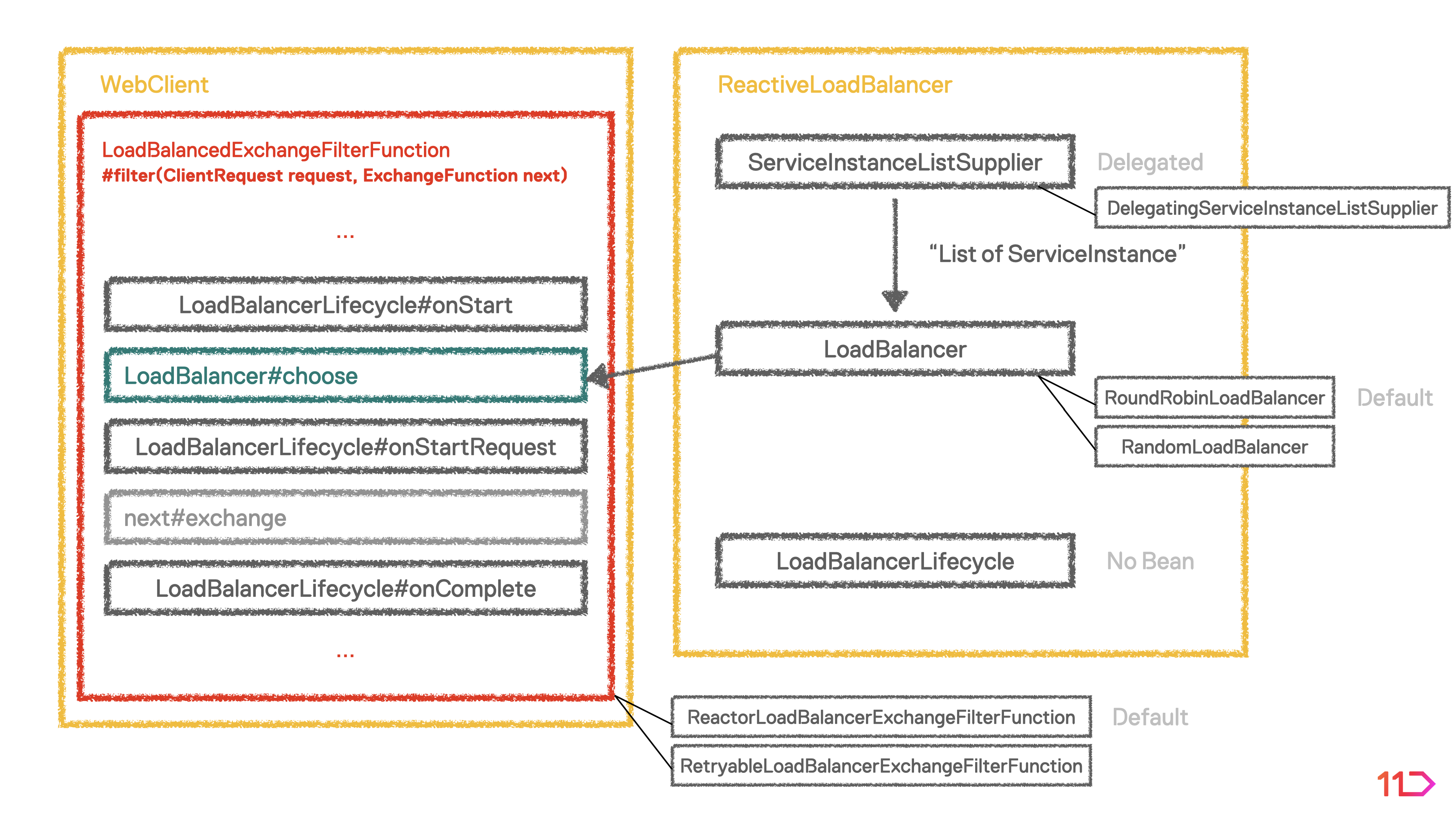
LoadBalancedExchangeFilterFunction
ExchangeFilterFunction은 WebClient의 요청과 응답에 대해 intercept하여 제어할 수 있는 인터페이스로, LoadBalancedExchangeFilterFunction 은 로드밸런싱과 관련한 제어를 수행합니다.
Spring Cloud LoadBalancer를 사용하게 되면 ReactorLoadBalancerExchangeFilterFunction 구현체 Bean이 Default로 활성화됩니다. LoadBalancer로부터 Property에 명시한 instance 중 임의로 하나를 받아 해당 인스턴스에 request를 보내는 형태입니다.
Default Bean인 ReactorLoadBalancerExchangeFilterFunction 에는 Retry 기능이 없습니다. 선택된 특정 인스턴스로의 요청이 실패할 경우 곧바로 다른 인스턴스를 선택해 시도하게 되는데요. 따라서 spring.cloud.loadbalancer.retry.enabled = true property를 추가하게 되면 RetryableLoadBalancerExchangeFilterFunction Bean이 활성화되어 Retry 기능을 사용할 수 있게 됩니다.
public interface LoadBalancedExchangeFilterFunction extends ExchangeFilterFunction {}
ReactiveLoadBalancer & ServiceInstanceListSupplier
ReactiveLoadBalancer 클래스는 로드밸런싱 정책과 관련되어 있습니다. ServiceInstanceListSupplier 로부터 인스턴스 목록을 받아와서 로드밸런싱 정책에 맞는 인스턴스를 반환합니다.
Spring Cloud LoadBalancer의 로드밸런싱 정책은 RoundRobin과 Random 두 가지 방식을 제공하고 있으며, 별도 설정이 없는 경우 RoundRobin이 기본 정책으로 사용됩니다.
public interface ReactiveLoadBalancer<T> {
Request<DefaultRequestContext> REQUEST = new DefaultRequest<>();
Publisher<Response<T>> choose(Request request);
default Publisher<Response<T>> choose() { return choose(REQUEST); }
interface Factory<T> {
default LoadBalancerProperties getProperties(String serviceId) { return null; }
ReactiveLoadBalancer<T> getInstance(String serviceId);
<X> Map<String, X> getInstances(String name, Class<X> type);
<X> X getInstance(String name, Class<?> clazz, Class<?>... generics);
}
}
public interface ServiceInstanceListSupplier extends Supplier<Flux<List<ServiceInstance>>> {
String getServiceId();
default Flux<List<ServiceInstance>> get(Request request) {
return get();
}
static ServiceInstanceListSupplierBuilder builder() {
return new ServiceInstanceListSupplierBuilder();
}
}
// RoundRobinLoadBalancer#choose(Request request)
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
ServiceInstanceListSupplier supplier = serviceInstanceListSupplierProvider.getIfAvailable(NoopServiceInstanceListSupplier::new);
return supplier.get(request)
.next()
.map(serviceInstances -> processInstanceResponse(supplier, serviceInstances));
}
LoadBalancerLifecycle
LoadBalancerLifecycle 클래스는 로드밸런싱 전후로 수행해야 하는 작업을 실행할 수 있는 메서드가 포함되어 있습니다. LoadBalancer가 인스턴스를 선택하여 반환하기 전 (onStart), WebClient가 request를 수행하기 전 (onStartRequest), request가 수행된 후 (onComplete)로 나뉩니다.
public interface LoadBalancerLifecycle<RC, RES, T> {
default boolean supports(Class requestContextClass, Class responseClass, Class serverTypeClass) {
return true;
}
void onStart(Request<RC> request);
void onStartRequest(Request<RC> request, Response<T> lbResponse);
void onComplete(CompletionContext<RES, T, RC> completionContext);
}
Zone Failover 설계 및 구현
Q. 인스턴스의 Zone 정보를 기반으로 우선 참조해야하는 Zone을 먼저 선택하도록 하고 Zone 내 모든 서버 인스턴스에 Reqeust를 보낼 수 없다면 Secondary Zone으로 전환할 수 있도록 하되, 어느 시점에서는 실패했던 Zone이 복구되었다는 가정 하에 재시도해서 원래의 상태를 찾아가야 할텐데 어떻게 구현을 해야 할까요?
Spring Cloud Netflix 를 의존성으로 가지는 경우라면, 위 문제는 지난 1부에서 설명드렸던 것과 같이 eureka.client.transport.retryable-client-quarantine-refresh-percentage Property 값 조정으로 해결이 가능합니다.
Eureka Client는 eureka.client.availability-zones에 명시한 Zone 목록에 따라 Primary Zone을 우선적으로 Request를 보내게 되고, 실패하게 될 경우 RetryableEurekaHttpClient 의 구현에 의해 Secondary Zone으로 전환되어 Failover를 달성할 수 있습니다. 그리고 SessionedEurekaHttpClient 의 구현에 의해 한 세션이 만료될 경우 다시 초기 상태로 돌아가 Primary Zone을 우선시 하여 Request를 보내기 때문에 Primary Zone의 Eureka Server들이 복구되는 경우 원래의 이상적 상태로 돌아갈 수 있게 됩니다.
Eureka Client에서의 세션 Duration은 다음 property 값을 수정하여 변경할 수 있습니다.
eureka.client.transport.sessioned-client-reconnect-interval-seconds(기본 값은 20분이며, 세션은 20 ± [0, 20/2] 분간 유지되다가 새롭게 초기화됩니다.)
그런데 eurekube-operator 는 Eureka Client 의존성을 가지지 않고 직접 WebClient 빈을 등록하여 Request를 보내고 있습니다. 따라서 위에서 설명드렸던 Spring Cloud LoadBalancer에서 제공하는 LoadBalancedExchangeFilterFunction 을 사용하면, spring.cloud.loadbalancer.configurations: zone-preference Property 설정을 통해 우선적으로 시도해야 하는 Zone을 설정할 수 있고 Load Balancer는 인스턴스 목록 중 Preferred Zone과 일치하는 인스턴스를 기반으로 로드밸런싱을 수행하게 됩니다.
그러나 우선 선호하는 Zone의 인스턴스를 선택만 할 뿐, 해당 Zone의 모든 인스턴스가 request failed되는 경우 다른 Zone으로의 Failover가 되지 않기 때문에 이러한 Failover 관련 구현은 직접 생성해야 합니다.
Zone Failover와 관련된 구현을 위해서 다음 두 가지가 고려되어야 할 것입니다.
- 특정 Zone의 모든 인스턴스에 Request가 실패하면 다른 Zone으로 전환될 것. (
RetryableEurekaHttpClient#getHostCandidates와 동일한 구현) - 어느 시점에 Preferred Zone이 복구될 것임을 감안하여 특정 시간이 지났을 때 초기의 상태로 돌아갈 것. (
SessionedEurekaHttpClient와 동일한 구현)
위 두 가지를 만족시키기 위해서 Cache Layer를 구현에 추가하였습니다. 요청 실패된 인스턴스 정보를 캐시에 보관하고, 로드밸런서가 인스턴스를 선택할 때 캐시에 포함된 요청 실패 인스턴스 정보를 감안하도록 할 수 있습니다. 또한 특정 시간 간격으로 캐시를 만료시켜 초기 상태로 되돌릴 수 있습니다.
따라서 다음과 같이 설계될 수 있습니다.
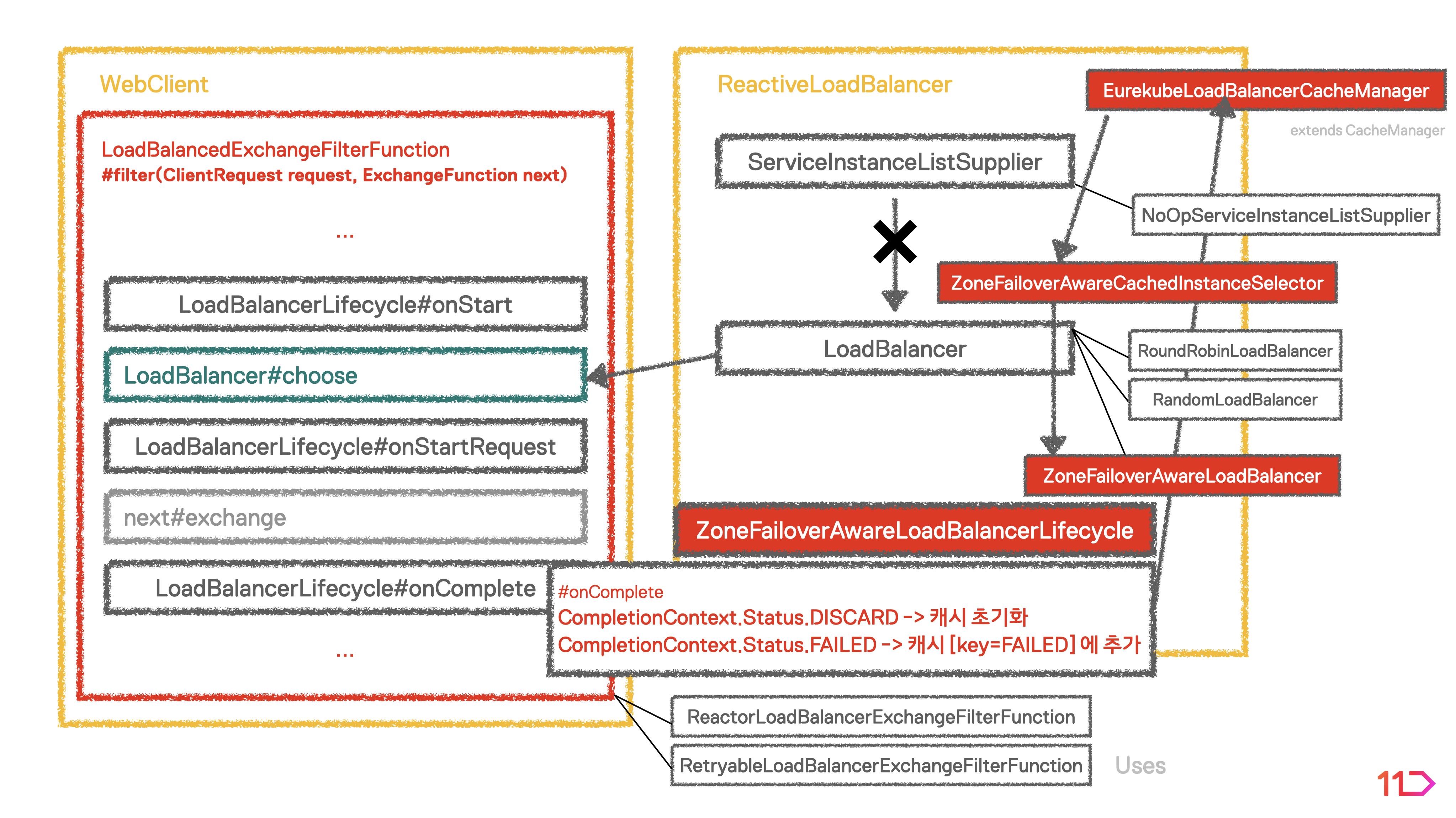
-
EurekubeLoadBalancerCacheManager- 캐시를 사용하여 요청 실패 인스턴스 정보를 기록합니다. TTL이 지나게 되면 캐시는 만료되어 초기 상태로 돌아가게 됩니다.
Caffeine.newBuilder() .expireAfterWrite(20L, TimeUnit.MINUTES) // Cache Miss가 발생하는 경우 CacheLoader에 의해서 EmptySet이 할당됩니다. .build(key -> new HashSet<ServiceInstance>());
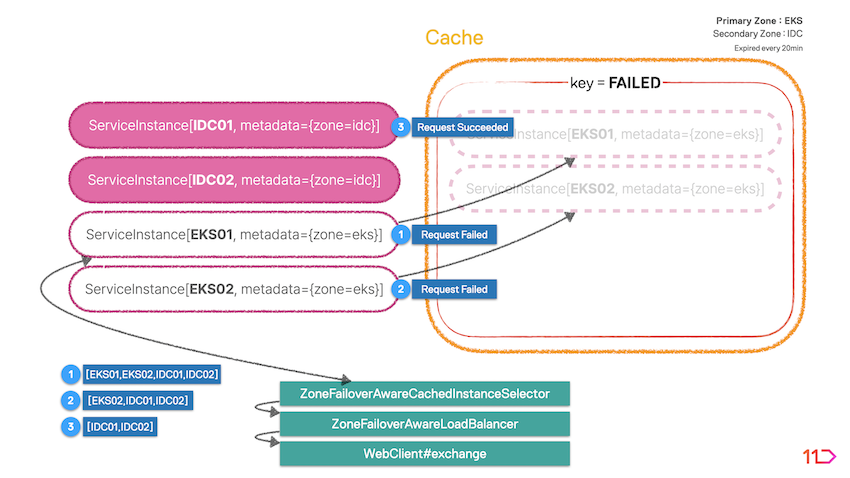
ZoneFailoverAwareLoadBalancerLifecycle- Load Balancer가 선택한 인스턴스로 요청 후 요청 결과가 실패인 경우에 캐시에 해당 인스턴스 정보를 기록합니다.
ZoneFailoverAwareCachedInstanceSelector- Load Balancer에 인스턴스 목록을 반환하되, 캐시에 저장되어 있는 요청 실패 인스턴스 정보를 고려합니다.
- 인스턴스 반환은 전체 목록에서 Preferred Zone을 우선 고려하되, 해당 Zone 내 접근 가능한 인스턴스가 없다면 나머지 Zone의 인스턴스 정보를 반환합니다.
ZoneFailoverAwareLoadBalancerZoneFailoverAwareCachedInstanceSelector에서 반환하는 인스턴스 목록을 대상으로 하나의 인스턴스를 선택합니다.RoundRobin방식과 결합한 형태로 구현하였습니다.
Chaos Test로 Zone Failover 달성 여부 확인
구현이 완료되었기 때문에 정상적으로 동작하는지를 Chaos Test를 통해서 확인해보겠습니다.
서버가 동작하지 않아 Request를 보낼 수 없는 경우, Network Latency가 높아 지연이 발생되는 경우에 대해서 모두 Zone Failover를 진행해야 의도했던 바를 달성할 수 있습니다.
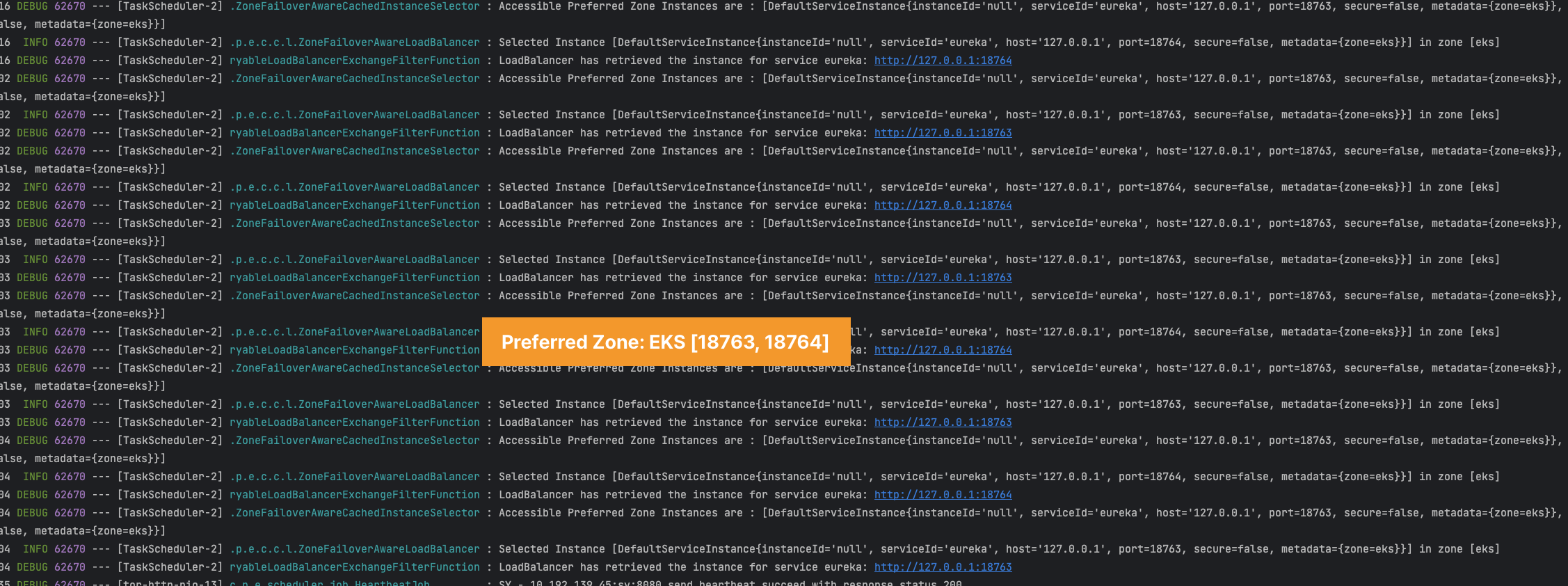

실제 동작은 의도했던 바와 같이 정상적으로 이루어지고 있음을 확인할 수 있었습니다.
Conclusion
Service Discovery DR 구성 1~3부에 걸쳐서 Service Discovery 컴포넌트 Eureka Server의 Multi-AZ Property 구성, Chaos Test를 통한 장애 상황 대처 검증, Client-side / Server-side Service Discovery 통합 K8s Operator의 Zone Failover 구현에 대한 내용을 설명드렸습니다.
11번가는 견고하고 안정화된 시스템을 개발 / 운영하기 위한 다양한 방법을 리서치하고, 도입하고자 노력하고 있습니다. 이와 같은 활동에 관심있으신 모든 분들의 지속적인 관심을 부탁드리며, 긴 글 읽어주셔서 감사합니다.
궁금하신 부분, 혹은 피드백 주실 내용이 있으시다면 언제든지 아래 코멘트 부탁드립니다. 🙇🏻♂️